| Issue |
JNWPU
Volume 38, Number 6, December 2020
|
|
|---|---|---|
| Page(s) | 1225 - 1234 | |
| DOI | https://doi.org/10.1051/jnwpu/20203861225 | |
| Published online | 02 February 2021 | |
A Paged Prefetching Model for Join Operations of Cross-Databases
一种用于跨数据库联接操作的分页预取模型
School of Computer Science and Engineering, Northwestern Polytechnical University, Xi'an 710072, China
Received:
16
April
2020
Abstract
As the applications of big data are increasing, the NoSQL (Not only Structured Query Language) database management systems have been developed rapidly. How to integrate NoSQL database and relational database effectively has become one of the research hotspots. In the existing research results, the paged query method used for join operations of these heterogeneous multi-databases can produce a large delay. In view of this deficiency, this paper presents a paged prefetching model, and focuses on its basic composition, prefetching mode and operation mechanism. A prototype system is designed and developed. The effect of this model is verified, and the expected targets are achieved. Compared with the non-prefetched paging query method, the outstanding contribution of this research result is that it can reduce the delay of paging query and thus improve the efficiency of the join operations of cross-databases.
摘要
随着大数据应用日益增多,NoSQL(not only structured query language)数据库管理系统得到了快速发展。如何对NoSQL数据库和关系型数据库进行有效集成成为研究热点之一。在现有研究成果中,在这些异构的多数据库之间进行联接(join)操作时,所采用的分页查询方法产生的延迟较大。针对这一问题,提出了一种分页预取的模型,并重点研究了其基本构成、预取方式以及运行机制。基于该模型,设计开发了原型系统,对其效果进行了验证,达到了预期目标。与无预取的分页查询方法相比,所建模型可以减少分页查询延迟,从而提升跨数据库联接操作的效率。
Key words: big data / NoSQL / SQL / database integration / cross-databases join / paged prefetching model / time delay / paging query
关键字 : 大数据 / NoSQL / SQL / 数据库集成 / 跨数据库联接 / 分页预取模型 / 时延 / 分页查询
© 2020 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
随着互联网, 特别是社交网络的飞速发展, 数据量也在以惊人的速度增长着, 人类已经迈入到大数据时代。
利用大数据给人们的生活和工作带来了极大的便利, 同时也给传统的数据管理方式带来了巨大的挑战[1-2]。大数据应用系统的日益增多, 为NoSQL数据库管理系统的发展提供了巨大的机遇。与关系型数据库管理系统相比, NoSQL数据库管理系统在大数据应用场景中的表现更胜一筹[3]。
在互联网、物联网、网络通讯、生物信息、医疗卫生、灾害预防、金融、公共安全以及地理信息等许多关键领域, NoSQL数据库管理系统都得到了广泛应用, 因此, 相关研究具有重要的学术价值和应用价值。
键值存储类型(key-value store)、列存储类型(column-oriented store)、文档存储类型(document-oriented store)和图存储类型(graph store)构成了NoSQL数据库管理系统的4种常见类型[3], 同时, 每种类型的NoSQL数据库管理系统又包括了许多知名的代表性产品。
NoSQL数据库管理系统拥有4个非常突出的优点[4]:扩展性高、读写数据速度快、支持对海量数据的存储以及具有相对低廉的成本。同时, NoSQL数据库管理系统也具有一些明显的缺点[2, 4-5], 主要表现在以下2个方面:
首先, NoSQL数据库管理系统缺乏诸如SQL(structured query language)那样的标准查询语言, 也没有通用的标准应用编程接口(application programming interface, API), 软件开发人员只能使用特定NoSQL数据库管理系统的API来与其进行交互, 这就使得应用系统的可移植性变得非常低[2, 4]。
其次, 在通常情况下, 为了提高性能和可伸缩性, NoSQL数据库管理系统放松了原子性、一致性、隔离性和持久性(atomicity, consistency, isolation, durability, ACID)事务属性的约束[5]。换言之, 它对数据库事务特性的支持程度较低。
目前, 关系型数据库管理系统和NoSQL数据库管理系统各有利弊, 在今后可以预见的时期内, 2种数据库管理系统是并存的[2, 6]。另外, 现代软件系统的构造模式是基于多数据库管理系统的, 不再只单纯地基于某一种数据库管理系统[7]。因此, 在大数据应用背景下, 如何有效地对这2种异构的数据库进行集成就成为一个非常具有挑战性的问题。
为了集成NoSQL数据库与关系型数据库, 许多学者从不同角度对这个问题进行了大量研究, 主要涉及NoSQL数据库的访问语言、NoSQL数据库的事务模型以及NoSQL数据库与关系型数据库的联合操作方法等方面。需要特别说明的是:由于NoSQL数据库的种类和代表性的产品非常多(正如前文所述), 并且同一类型的每个产品在具体的实现方法方面也存在差异, 对全部产品进行研究的工作量非常巨大, 因此, 学者们在进行相关研究时通常只选取其中的部分产品进行研究。
在现有的研究成果中, 为了在NoSQL数据库与关系型数据库之间进行联合操作, 一些学者采用SQL对跨数据库的联接操作(指join操作, 本文下同)进行了研究。其中, 为了避免大数据量联接过程中产生服务器内存溢出, 采用了从源数据库中进行分页查询的方法。但是, 这种方法产生的延迟较大。在已经取得的研究成果[8]的基础上, 本文对跨数据库联接操作的分页查询方法进行了进一步的研究, 提出了分页预取模型, 涉及模型构成、预取方式以及运行机制。通过对该模型进行定性比较和定量分析, 可以发现该模型在减少延迟、从而提高跨数据库联接操作的效率方面表现良好。
1 模型构成
1.1 基本构成
如图 1所示, 分页预取模型由以下6个基本单元构成。
1) 预取队列主要用于缓存从特定数据库管理系统中加载的数据记录, 可对其大小进行配置, 以避免对服务器内存的无限制使用。另外, 它支持阻塞方式的移除方法, 换言之, 当队列为空时, 获取队列中元素的线程会等待该队列变为非空。
2) 批量预取单元主要负责从特定数据库管理系统中分批次地将数据记录加载到预取队列中。为了控制好加载的节奏, 批量预取单元需要按照约定的预取方式确定下一个批次的预取时机。
3) 分页获取单元主要负责从预取队列中获取每个分页的数据记录, 并通过预取控制单元将这些分页数据返回给联接处理单元。当预取队列中没有数据记录时, 分页获取单元需要等待。
4) 预取协作单元的主要职责是为预取控制单元、批量预取单元和分页获取单元完成一些协作性任务, 主要涉及2个方面的任务:①从指定的数据库管理系统中获取符合查询条件的数据记录的总数量, 计算预取的总次数、每次预取的数据记录数量、分页获取的总次数以及每次分页获取的数据记录数量, 并将这些参数写入到预取参数对象中。②动态地计算每次预取的消耗时间、预取的动态平均速度、每次分页获取的消耗时间、每次分页联接的消耗时间以及分页联接的动态平均速度, 并将这些参数也写入到预取参数对象中。
5) 预取控制单元主要负责调度和协调任务, 并与联接处理单元进行交互。
6) 异常处理单元主要对分页预取过程中出现的错误进行响应。
 |
图1 分页预取模型的基本构成 |
1.2 与其他服务的关联
基于本文提出的分页预取模型(paged pre-fetching model)所实现的软件功能模块被称为分页预取器(paged prefetcher), 图 2展示了分页预取器与其他服务(在图 2中由虚线标记的具体功能)的关联关系。
当从SQL客户端输入一条SQL语句时, 首先, 由SQL API调度器调用SQL解析器, 将输入的SQL语句的各个组成部分转化为特定计算机语言的对象; 然后, 经过SQL优化器和SQL路由器, 由SQL执行器将分解后的SQL语句内容分发到特定的数据库管理系统进行执行; 接着, 执行结果被返回给结果合并器; 最后, 这些执行结果数据再由SQL API调度器返回给SQL客户端。在此过程中, SQL优化器负责处理复杂嵌套查询转化等优化工作。当SQL语句涉及多个数据库管理系统时, 由SQL路由器对其进行分解, 这样, 特定的数据库管理系统只处理与其相关的部分。数据库管理系统(database management system, DBMS)适配器主要由语义检查、参数生成、API调用、运行时支撑模块以及错误处理等部分组成, 与具体的数据库管理系统进行交互。对于由多个数据库管理系统返回的查询结果数据, 则需要结果合并器对其进行合并和排序等工作。另外, 元数据管理模块主要负责对数据库的各种配置参数、SQL语句的解析结果、优化的结果以及路由的结果进行管理。
对于分页预取器来说, 图 1中的联接处理单元和配置参数部分则分别位于图 2中的SQL执行器和元数据管理模块中。因此, 对于多数据库的联接操作来说, SQL执行器通过联接处理单元来完成。
需要说明的是:关于多数据库(包括NoSQL数据库和关系型数据库)的基本联接算法以及图 2中由虚线标记的具体功能, 在本文作者的另外一篇论文[8]中进行了详细描述, 受限于本文讨论的重点和篇幅, 这里不再进行赘述。
 |
图2 分页预取器与其他服务的关联 |
2 预取方式
2.1 相关定义与符号表示
定义1 预取的数据记录总数:指进行数据的联接操作时, 需要从参与联接操作的特定数据库中查询的数据记录数量, 记为St。在预取控制单元的协调下, 当批量预取单元获取第一个批次的数据记录时, 由预取协作单元并行地获取该参数。
定义2 请求分页的大小:指进行数据的联接操作时, 联接处理单元每次需要获取的数据记录数量的最大值, 记为Sq。在数量上, 等于分页获取单元每次从预取队列中得到的数据记录数量。在联接处理单元发起分页查询请求时, 会将分页大小参数传递给预取控制单元。
定义3 预取队列的大小:指最多可以在预取队列中保存的数据记录的数量, 记为Sp。这个参数限制了数据的联接操作对计算机内存的使用量, 以避免过多的内存使用导致计算机内存溢出问题。另外, 在数量上, 规定这个参数是请求分页大小参数的整数倍, 即
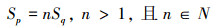 (1)
(1)
定义4 预取的总次数:指进行数据的联接操作时, 批量预取单元从参与联接操作的特定数据库中获取数据的次数, 记为Cp。在数量上, 这个参数等于预取的数据记录总数除以预取队列的大小, 并向上取整数, 即
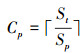 (2)
(2)
定义5 每次预取的数据记录数量:指进行数据的联接操作时, 批量预取单元每次从参与联接操作的特定数据库中获取的数据记录数量, 记为Sp, i, 其中, i表示预取的序号, 并且1≤i≤Cp。在数量上, 这个参数不大于预取队列的大小, 即
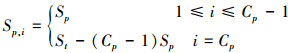 (3)
(3)
定义6 分页获取的总次数:指进行数据的联接操作时, 分页获取单元从预取队列中获取数据的次数, 记为Cq。在数量上, 这个参数等于预取的数据记录总数除以请求分页的大小, 并向上取整数, 即
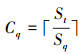 (4)
(4)
定义7 每次分页获取的数据记录数量:指进行数据的联接操作时, 分页获取单元每次从预取队列中获取的数据记录数量, 记为Sq, j, 其中, j表示分页获取的序号, 并且1≤j≤Cq。在数量上, 这个参数不大于请求分页的大小, 即
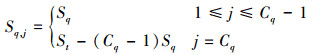 (5)
(5)
定义8 每次预取的开始时间和结束时间:指批量预取单元每次从参与联接操作的特定数据库中获取数据记录的开始时间点和结束时间点, 分别记为Tps, i和Tpe, i, 其中, i表示预取的序号, 并且1≤i≤Cp。如图 3所示, Tps, 1表示第1次预取的开始时间, Tps, 2表示第2次预取的开始时间, 以此类推, Tps, i表示第i次预取的开始时间。类似的, Tpe, i表示第i次预取的结束时间。
定义9 每次预取的消耗时间:指批量预取单元每次从参与联接操作的特定数据库中获取数据记录时所花费的时间, 记为ΔTp, i, 其中, i表示预取的序号, 且1≤i≤Cp。在数量上, 该参数等于每次预取的结束时间与每次预取的开始时间的差值, 即
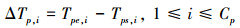 (6)
(6)
如图 3所示, ΔTp, 1表示第1次预取的消耗时间, ΔTp, 2表示第2次预取的消耗时间, 以此类推, ΔTp, i表示第i次预取的消耗时间。
定义10 预取的动态平均速度:指在单位时间内, 批量预取单元从参与联接操作的特定数据库中获取数据记录的数量, 记为Vp, i, 其中, i表示预取的序号, 且1≤i≤Cp。在数量上, 该参数等于已经预取到的数据记录数量除以所花费的时间之和, 即
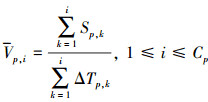 (7)
(7)
另外, 由预取协作单元来动态计算该参数的具体大小, 因而, 这个参数会随着时间的推移而发生一些变化。
定义11 每次分页获取的开始时间和结束时间:指分页获取单元每次从预取队列中获取数据记录的开始时间点和结束时间点, 分别记为Tqs, j和Tqe, j, 其中, j表示分页获取的序号, 并且1≤j≤Cq。如图 4所示, Tqs, 1表示第1次分页获取的开始时间, Tqs, 2表示第2次分页获取的开始时间, 以此类推, Tqs, j表示第j次分页获取的开始时间。类似的, Tqe, j表示第j次分页获取的结束时间。
定义12 每次分页获取消耗时间:指分页获取单元每次从预取队列中获取数据记录时所花费的时间, 记为ΔTq, j, 其中, j表示分页获取的序号, 并且1≤j≤Cq。在数量上, 这个参数等于每次分页获取的结束时间与每次分页获取的开始时间的差值, 即
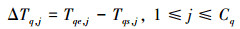 (8)
(8)
如图 4所示, ΔTq, 1表示第1次分页获取消耗时间, ΔTq, 2表示第2次分页获取消耗时间, 以此类推, ΔTq, j表示第j次分页获取消耗时间。
定义13 每次分页联接的消耗时间:指进行数据的联接操作时, 联接处理单元每次分页联接所花费的时间, 记为ΔT*, j, 其中, j表示分页获取的序号, 并且1≤j≤Cq。在数量上, 这个参数等于下一次分页获取的开始时间与本次分页获取的结束时间的差值, 即
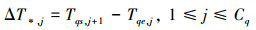 (9)
(9)
如图 4所示, ΔT*, 1表示第1次分页联接的消耗时间, 以此类推, ΔT*, j表示第j次分页联接的消耗时间。
定义14 分页联接的动态平均速度:指在单位时间内, 联接处理单元所处理的数据记录的数量, 记为V*, j, 其中, j表示分页获取的序号, 并且1≤j≤Cq。在数量上, 这个参数等于已经分页获取到的数据记录数量除以分页联接的消耗时间之和, 即
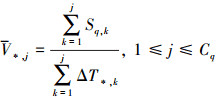 (10)
(10)
另外, 由预取协作单元来动态计算该参数的具体大小, 因而, 这个参数也会随着时间的推移而发生一些变化。
 |
图3 预取的相关时间示意图 |
 |
图4 分页获取和分页联接的相关时间示意图 |
2.2 预取时机
分页预取模型的核心思想是:在预取队列的大小保持不变的前提下, 根据分页联接的动态平均速度和预取的动态平均速度来决定预取下一个批次数据记录的时机。这样, 在服务器内存占用不超过指定数量的条件下, 尽可能减少联接操作的等待时间, 从而提升多数据库联接操作的效率。
如图 5所示, 在Tpe, 1时刻, 批量预取单元完成了第一批数据记录的加载工作, 这时, 可以利用公式(7)得到当前预取的动态平均速度Vp, 1; 在Tqs, 2时刻, 联接处理单元完成了第一个分页数据记录的联接工作, 这时, 可以利用公式(10)得到当前分页联接的动态平均速度V*, 1; 根据Vp, 1和V*, 1计算批量预取单元在开始下一个批次数据记录的加载工作之前还需要等待的时间ΔTε, 1。以此类推, 在Tpe, i-1时刻, 批量预取单元完成了第i-1批数据记录的加载工作, 根据当前预取的动态平均速度和当前分页联接的动态平均速度, 计算批量预取单元在开始第i个批次数据记录的加载工作之前还需要等待的时间ΔTε, i-1。
ΔTε, i(1≤i≤Cp-1)的计算方法如下:
首先, 计算联接处理单元将当前预取队列中剩余数据记录处理完毕所需要的时间(记为Tq*), 即
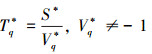 (11)
(11)
式中, S*为当前预取队列中剩余数据记录的数量, 可以通过测量预取队列得到。而Vq*则为当前分页联接的动态平均速度V*, j, Vq*的初始值被置为-1。若Vq*=-1, 则表示联接处理单元还没有完成第一个分页数据记录的联接工作, 这时, 批量预取单元需要等待(在图 5中表示为ΔT*, 1时间段)。
其次, 计算批量预取单元加载一个批次的数据记录所需要的时间(记为Tp*), 即
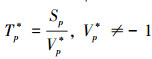 (12)
(12)
式中, Sp为预取队列的大小(见定义3)。而Vp*则为当前预取的动态平均速度Vp, i, Vp*的初始值被置为-1。若Vp*=-1, 则表示批量预取单元还没有完成第一批数据记录的加载工作(在图 5中表示为ΔTp, 1时间段)。
最后, 根据(13)式计算ΔTε, i, 其中1≤i≤Cp-1
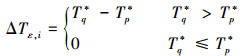 (13)
(13)
另外, 从图 5可以看出, 分页预取模型可以尽力减少联接操作的等待时间, 但不能完全消除所有的等待时间。例如, 在ΔTp, 1时间段之内, 联接处理单元还是需要等待的。
 |
图5 预取时机示意图 |
3 运行机制
如图 6所示, 当2个不同的数据源参与联接操作时, 联接处理单元通过2个不同的分页预取器实例获取不同的分页数据记录。
如图 7所示, 在单个分页预取器内部, 其运行机制可以通过以下步骤进行描述。
1) 预取控制单元接收联接处理单元的分页查询请求(涉及数据库表名、查询字段列表、排序要求以及分页大小等参数)。
2) 首先, 预取控制单元在配置参数中查找到数据库表名所对应的数据库系统的配置参数(如IP地址、端口以及账户信息等)和预取队列的大小参数(Sp), 并将这些参数和从联接处理单元传递来的参数一起写入预取参数对象中; 然后, 预取控制单元调用预取协作单元和批量预取单元, 让它们并行地执行各自的任务:前者负责获取符合查询条件的数据记录的总数量, 而后者则负责获取第一个批次的数据记录; 最后, 预取控制单元通过调用分页获取单元来得到第一个分页的数据记录, 而分页获取单元在预取队列当中没有得到指定数量的数据记录时会处于等待状态, 直到获得本次分页的全部数据记录为止。
3) 首先, 通过DBMS适配器单元, 预取协作单元从指定的数据库中获取符合查询条件的数据记录的总数量(即预取的数据记录总数St)。接着, 通过(2)至(5)式, 预取协作单元分别计算出预取的总次数(Cp)、每次预取的数据记录数量(Sp, i)、分页获取的总次数(Cq)以及每次分页获取的数据记录数量(Sq, j), 并将这些参数写入到预取参数对象中。此后, 根据(6)至(10)式, 预取协作单元会动态地分别计算每次预取的消耗时间(ΔTp, i)、预取的动态平均速度(Vp, i)、每次分页获取消耗时间(ΔTq, j)、每次分页联接的消耗时间(ΔT*, j)以及分页联接的动态平均速度(V*, j), 并及时更新当前分页联接的动态平均速度(Vq*)和当前预取的动态平均速度(Vp*), 并将这些参数也写入到预取参数对象中。
4) 通过DBMS适配器单元, 批量预取单元从指定的数据库中获取第一个批次的数据记录, 并将这些数据记录加载到预取队列当中。另外, 批量预取单元还将每次预取的开始时间(Tps, i)和每次预取的结束时间(Tpe, i)写入到预取参数对象中。从完成第一个批次的数据记录加载开始, 根据(11)至(13)式, 批量预取单元在开始下一个批次数据记录的加载工作之前, 还需要计算等待的时间ΔTε, i (1≤i≤Cp-1), 以决定预取数据的时机。
5) 根据每次分页获取的数据记录数量(Sq, j)参数, 分页获取单元从预取队列当中得到指定数量的数据记录, 并通过预取控制单元返回给联接处理单元。另外, 分页获取单元还将每次分页获取的开始时间(Tqs, j)和每次分页获取的结束时间(Tqe, j)写入到预取参数对象中。
 |
图6 联接操作示意图 |
 |
图7 分页预取器内部运行机制示意图 |
4 相关研究
在NoSQL数据库管理系统与关系型数据库管理系统各有利弊并且共同存在的背景下, 围绕如何对这2种异构的数据库进行有效集成这个问题, 许多学者从不同侧面进行了研究。
1) 在NoSQL数据库的访问语言研究方面, 许多学者尝试为特定的NoSQL数据库管理系统增加SQL访问语言。通常的做法是:在NoSQL数据库管理系统之上, 构造一个SQL中间层, 让熟悉SQL的数据库用户或者软件系统开发人员使用常用的SQL命令来访问特定的NoSQL数据库系统, 以提高应用系统的可移植性, 并降低用户学习和使用NoSQL数据库系统的难度, 从而提升软件系统的开发效率。目前, 这部分的研究工作主要涉及HBase[6]、MongoDB[2, 8-10]、Cassandra[11]、Redis[8]以及SimpleDB等[12]NoSQL数据库管理系统。
2) 在NoSQL数据库的事务控制模型研究方面, 有许多学者采用快照隔离(snapshot isolation)技术或者经典的锁技术为特定的NoSQL数据库管理系统实现事务控制功能, 也有一些研究人员通过修改特定的NoSQL数据库管理系统的源程序, 从而在数据库存储本身来实现事务支持特性。目前, 这部分的研究工作主要涉及HBase[13]、MongoDB[14-15]以及Cassandra[16-17]等NoSQL数据库管理系统。
3) 在关系型数据库与NoSQL数据库的联合操作方法研究方面, 一些学者基于SQL对此问题进行了一些初步的探索[2, 8-10]。
首先, 文献[9-10]不涉及SQL嵌套语句和多数据库联接的处理。其中, 文献[9]设计了一个软件引擎(MingleDB), 负责解析SQL语句, 并从中剥离出不同类型的数据, 在MongoDB数据库中保存非结构化数据, 在MySQL数据库中则只存储结构化数据。文献[10]构造了一个虚拟引擎(NoMiddleware), 负责解析SQL语句, 并标记该SQL语句访问的数据库类型(MongoDB或者MySQL)。也就是说, 这种方法不能在一条SQL语句中访问多种数据库。
其次, 文献[2, 8]涉及多数据库的联接操作。文献[2]设计了一个虚拟系统(unity), 负责解析、分解和改写SQL语句, 并向每种数据库(MongoDB或者MySQL)发送与其相关的数据, 这种方法能够在一条SQL语句中访问2种数据库。同时, 文献[2]的研究工作也涉及在MongoDB与MySQL之间进行联接操作, 但是, 不涉及数据记录的分页查询和复杂的嵌套查询操作。在文献[8]中, 作者们研究了为Redis和MongoDB构造SQL特性的方法, 在此基础上, 还研究了通过一条SQL语句访问Redis、MongoDB以及MySQL的方法, 涉及任意复杂嵌套查询操作的转化方法和基本联接操作的实现方法。另外, 为了避免大数据量联接过程中产生服务器内存溢出, 文献[8]采用了从源数据库中进行分页查询的方法。但是, 不涉及分页查询的预取操作, 会产生查询延迟。
由于在多数据库场景下, 在从参与联接操作的特定数据库中查询每一个分页数据记录的过程中, 联接操作会出现等待的现象, 因此, 有必要对此问题进行进一步研究, 以尽可能减少联接操作的等待时间, 从而提升多数据库联接操作的效率。
5 模型评估
5.1 定性比较
尽本文作者所知, 在现有的关于NoSQL数据库和关系型数据库集成方法的研究成果中, 文献[2]和文献[8]涉及多数据库的联接操作, 将本文与它们做一个定性比较(如表 1所示)。
从表 1可以看出, 三者都涉及NoSQL数据库和关系型数据库的联接操作, 但是, 对联接的支持程度却存在差别, 主要表现在以下2个方面:
首先, 在是否支持分页查询方法方面存在差别, 其中, 文献[ 2]不支持, 而文献[8]和本文则支持。当数据库联接操作涉及的数据记录很多时, 如果不采用分页查询方法的话, 就会出现服务器内存溢出的问题。
其次, 在是否支持预取查询方法方面存在不同, 其中, 本文支持这种方法, 而文献[2]和文献[8]则不支持。如果不采用预取的方法, 多数据库联接操作的效率则相对较低。
从以上定性比较可以发现, 本文提出的用于多数据库联接操作的分页预取模型, 不但可以避免由大数据量查询所导致的服务器内存溢出现象, 而且也可以减少分页查询的延迟, 从而提升多数据库联接操作的效率。
关于联接操作的定性比较
5.2 定量分析
以左联接为例, 对本文提出的分页预取模型的性能进行评估, 这里考虑MongoDB数据库的表与MySQL数据库的表进行左联接, 同时, 参与评估的2种数据库表通过外键进行联接。
1) 度量和参数说明
软件的运行环境参数如下:
MySQL DataBase: 5.6;
MongoDB DataStore: 3.2;
JDK: 1.8, 64 bit;
操作系统:CentOS Linux 7.6, 64 bit。
在3台测试的计算机上分别部署了MySQL、MongoDB以及原型系统, 采用千兆以太网交换机连接这些测试计算机。这些计算机的参数如下:
CPU: Intel i7 9700(8核, 3.6 GHz);
内存:8G(DDR4 2 666 MHz);
硬盘:1T, 7 200 r/min;
网卡:千兆以太网网卡。
在进行评估时, 预先在MySQL和MongoDB数据库中分别加载了100万条数据记录。
2) 参与联接的数据记录数量对性能的影响分析
如表 2所示, 在分页大小和预取队列大小保持不变的情况下, 通过改变参与联接的数据记录数量参数, 对分页预取模型进行性能评估。在此场景中, 分页大小参数(Sq)为100, 预取队列大小参数(Sp)为500。另外, 在表 2中, “5kx5k”表示MongoDB数据库中的5 000条记录与MySQL数据库中的5 000条记录参与了左联接测试, 其他情形以此类推。
从表 2可以发现:首先, 随着参与联接的数据记录数量的增加, 无预取分页联接和有预取的分页联接所花费的时间都在增加, 这主要是由于访问数据库的总次数也在增加所导致的。其次, 相对于无预取联接, 随着参与联接的数据记录数量的增加, 分页预取模型减少延迟的百分比却接近一个常数, 其原因在于预取队列大小参数(Sp)与分页大小参数(Sq)之间的比例没有改变。
3) 预取队列的大小对性能的影响分析
如表 3所示, 在分页大小和参与联接的数据记录数量保持不变的情况下, 通过改变预取队列大小参数, 对分页预取模型进行性能评估。在此场景中, 分页大小参数(Sq)为100, MongoDB数据库中的6 000条记录与MySQL数据库中的6 000条记录参与了左联接测试。
从表 3可以发现:随着预取队列大小参数(Sp)的增大, 有预取的分页联接所花费的时间会减少, 而分页预取模型减少延迟的百分比却在增大, 这主要是由于访问数据库的总次数随着预取队列大小参数(Sp)的增大而减少所导致的。
4) 分页的大小对性能的影响分析
如表 4所示, 在参与联接的数据记录数量和预取队列大小保持不变的情况下, 通过改变分页大小参数, 对分页预取模型进行了性能评估。在此场景中, 预取队列大小参数(Sp)为1 000, MongoDB数据库中的6 000条记录与MySQL数据库中的6 000条记录参与了左联接测试。
从表 4可以发现:首先, 随着分页大小参数(Sq)的增大, 无预取分页联接和有预取的分页联接所花费的时间都在减少, 这主要是由于访问数据库的总次数也在减少所导致的。其次, 随着分页大小参数(Sq)的增大, 分页预取模型减少延迟的百分比却在减少, 其原因在于预取队列大小参数(Sp)与分页大小参数(Sq)之间的比例也在减小所造成的。
参与联接的数据记录数量对性能的影响评估
预取队列的大小对性能的影响评估
分页的大小对性能的影响评估
5.3 评估小结
通过前文的定性比较和定量分析, 现对本文提出的用于多数据库联接操作的分页预取模型进行小结如下:
1) 除了可以避免由大数据量查询所导致的服务器内存溢出现象之外, 通过减少分页查询的延迟, 分页预取模型可以提升多数据库联接操作的效率。
2) 在预取队列大小参数大于分页大小参数的前提下, 适当增大这2个参数, 有助于提升多数据库联接操作的效率。
3) 在预取队列大小参数大于分页大小参数的前提下, 适当增大前者与后者之间的比例, 有助于提高分页预取模型减少延迟的百分比(相对于无预取的分页查询方法)。
6 结论
针对无预取分页查询方法所存在的延迟较大的不足, 本文提出了一种分页预取的模型, 并对该模型的基本构成、预取方式以及运行机制进行了重点研究。为了对该模型的效果进行评估, 设计开发了该模型的初始版本的原型系统。通过评估数据可以看出, 与无预取的分页查询方法相比, 可以明显减少分页查询延迟, 达到了预期的目标。下一步, 将基于该模型, 在原型系统中实现更多的新特性。
References
- Meng Xiaofeng, Ci Xiang. Big Data Management:Concepts, Techniques and Challenges[J]. Journal of Computer Research and Development, 2013, 50(1): 146-169 (in Chinese) [Google Scholar]
- Ramon Lawrence. Integration and Virtualization of Relational SQL and NoSQL Systems Including MySQL and MongoDB[C]//2014 International Conference on Computational Science and Computational Intelligence, USA, 2014: 285-290 [Google Scholar]
- Alejandro Corbellini, Cristian Mateos, Alejandro Zunino, et al. Persisting Big Data:The NoSQL Landscape[J]. Information Systems, 2017, 63(1): 1-23 [CrossRef] [Google Scholar]
- Jing Han, Haihong E, Guan Le, et al. Survey on NoSQL Database[C]//6th International Conference on Pervasive Computing and Applications, USA, 2011: 363-366 [Google Scholar]
- Bhuvan N T, Elayidom M S. A Technical Insight on the New Generation Databases:NoSQL[J]. International Journal of Computer Applications, 2015, 121(7): 24-26 [CrossRef] [Google Scholar]
- Liao Yingti, Zhou Jiazheng, Lu Chiahung, et al. Data Adapter for Querying and Transformation between SQL and NoSQL Database[J]. Future Generation Computer Systems, 2016, 65: 111-121 [CrossRef] [Google Scholar]
- Xie Guoqi, Chen Yuekun, Liu Yan, et al. JDAS:a Software Development Framework for Multidatabases[J]. Software:Practice and Experience, 2018, 48(2): 366-382 [CrossRef] [Google Scholar]
- Li Changqing, Gu Jianhua. An Integration Approach of Hybrid Databases Based on SQL in Cloud Computing Environment[J]. Software:Practice and Experience, 2019, 49(3): 401-422 [CrossRef] [Google Scholar]
- Pan Mingming, Li Dingding, Tang Yong, et al. Design and Implemention of Accessing Hybrid Database Systems Based on Middleware[J]. Computer Science, 2018, 45(5): 163-167 (in Chinese) [Google Scholar]
- Zhang Chao, Xu Jing. A Unified SQL Middleware for NoSQL Databases[C]//The 2018 International Conference on Big Data and Computing, ACM USA, 2018: 14-19 [Google Scholar]
- Solanke G B, Rajeswari K. SQL to NoSQL Transformation System Using Data Adapter and Analytics[C]//2017 IEEE International Conference on Technological Innovations in Communication, Control and Automation, USA, 2017: 59-63 [Google Scholar]
- Andre Calil, Ronaldo Mello. SimpleSQL: a Relational Layer for SimpleDB[C]//East European Conference on Advances in Databases and Information Systems, Germany, 2012: 99-110 [Google Scholar]
- Vinit Padhye, Anand Tripathi. Scalable Transaction Management with Snapshot Isolation for NoSQL Data Storage Systems[J]. IEEE Trans on Services Computing, 2015, 8(1): 121-135 [CrossRef] [Google Scholar]
- Adewole Conrad Ogunyadeka, Muhammad Younas, Hong Zhu, et al. A Multi-Key Transactions Model for NoSQL Cloud Database Systems[C]//Second International Conference on Big Data Computing Service and Applications, USA, 2016: 24-27 [Google Scholar]
- Xuan Chao. Research and Implementation of Transaction Mechanism Based on MongoDB[D]. Chengdu: University of Electronic Science and Technology of China, 2018 (in Chinese) [Google Scholar]
- Fabio Andre Coelho, Francisco Miguel Barros da Cruz, Ricardo Vilaca, et al. PH1: a Transactional Middleware for NoSQL[C]//The 33rd International Symposium on Reliable Distributed Systems, USA, 2014: 115-124 [Google Scholar]
- Li Xiaolong. The Support for Distributed Database Transaction[D]. Chengdu: University of Electronic Science and Technology of China, 2014 (in Chinese) [Google Scholar]
All Tables
All Figures
|
图1 分页预取模型的基本构成 |
| In the text | |
|
图2 分页预取器与其他服务的关联 |
| In the text | |
|
图3 预取的相关时间示意图 |
| In the text | |
|
图4 分页获取和分页联接的相关时间示意图 |
| In the text | |
|
图5 预取时机示意图 |
| In the text | |
|
图6 联接操作示意图 |
| In the text | |
|
图7 分页预取器内部运行机制示意图 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.