| Issue |
JNWPU
Volume 37, Number 3, June 2019
|
|
|---|---|---|
| Page(s) | 503 - 508 | |
| DOI | https://doi.org/10.1051/jnwpu/20193730503 | |
| Published online | 20 September 2019 | |
A Bioinspired Visual Saliency Model
一种生物启发的视觉显著模型
1
Key Laboratory of Contemporary Design and Integrated Manufacturing Technology of Ministry of Education, Northwestern Polytechnical University, Xi’an, 710072, China
2
School of Computer Science, Northwestern Polytechnical University, Xi’an, 710129, China
Received:
12
February
2018
Abstract
This paper presents a bioinspired visual saliency model. The end-stopping mechanism in the primary visual cortex is introduced in to extract features that represent contour information of latent salient objects such as corners, line intersections and line endpoints, which are combined together with brightness, color and orientation features to form the final saliency map. This model is an analog for the processing mechanism of visual signals along from retina, lateral geniculate nucleus(LGN)to primary visual cortex V1:Firstly, according to the characteristics of the retina and LGN, an input image is decomposed into brightness and opposite color channels; Then, the simple cell is simulated with 2D Gabor filters, and the amplitude of Gabor response is utilized to represent the response of complex cell; Finally, the response of an end-stopped cell is obtained by multiplying the response of two complex cells with different orientation, and outputs of V1 and LGN constitute a bottom-up saliency map. Experimental results on public datasets show that our model can accurately predict human fixations, and the performance achieves the state of the art of bottom-up saliency model.
摘要
提出一种生物启发式的视觉显著模型,利用初级视皮层中的end-stopping机制来提取角点、边缘交叉点和线段端点等这些表征潜在显著物体轮廓的特征,将其与亮度、颜色和方向特征合并形成最终显著图。模型模拟了视觉信号从视网膜、侧膝体到初级视皮层的处理机制:首先根据视网膜和侧膝体特性,将图像分解为亮度和对立颜色通道;然后通过2D Gabor滤波模拟简单细胞感受野,Gabor响应振幅用于表示复杂细胞响应;最后V1层end-stopped细胞响应通过不同朝向的复杂细胞响应乘积来计算,V1层和侧膝体的输出共同构成自底向上显著图。公开数据集上的实验结果显示模型能够准确地预测人眼注视点,性能达到了自底向上模型的先进水平。
Key words: bottom-up saliency / visual attention / end-stopping
关键字 : 自底向上显著模型 / 视觉注意力 / end-stopping机制
© 2019 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
显著图是表示视觉场景中每个像素位置吸引注意力程度的地形图[1]。研究者已经提出了多种用于计算显著图的视觉显著模型, 根据注意力类型的不同, 可以分为自顶向下和自底向上2种:自顶向下注意力依赖于任务, 由生物的主观认知控制; 相反自底向上注意力受图像数据驱动, 由图像中的突出特征引导。自底向上显著模型通常提取图像中的低层特征并整合为显著图, 而自顶向下显著模型一般通过加入高层特征或从真实眼动数据中学习特征权重的方式来加入自顶向下注意成分。
自底向上注意通常在初级视皮层V1中形成, 而自顶向下注意则与高级脑皮层相关, 这2种显著模型都直接或间接地受到生物视觉机制的启发。最经典的自底向上显著模型[2], 模拟了人类从视网膜到初级视皮层的早期视觉通路:首先根据视网膜中视锥细胞和视杆细胞的特点将输入图像分解为亮度和颜色成分, 之后进行的中央周边差算子模拟侧膝体中的on-off型神经元, 用于提取方向特征的Gabor滤波则是对V1简单细胞方向选择特性的模拟。该框架在自底向上模型中被广泛采用, 但未考虑V1中更深层的end-stopping机制, 无法检测T型结点和线段端点等特征。
end-stopping机制是初级视皮层内一部分简单细胞和复杂细胞的特性, 这类细胞被称为end-stopped细胞, 约占V1层神经元的25%左右。end-stopped细胞对特定长度和朝向的条状刺激敏感, 其组合可以用于检测角点、直线和边缘的交叉点、奇点和曲率较大点[3]。这些特征可以描述场景中物体的形状和轮廓信息, 因此被许多模型用于提取显著区域或估计显著度, 如基于角点的方法[4]、基于兴趣点的方法[5]和基于曲率特征的方法[6]等, 但这些模型使用设计好的单一特征来描述显著性, 均未涉及end-stopping机制的建模, 而end-stopped细胞能感知角点、线交叉点、曲率点等多种特征, 其在自底向上显著图形成过程中的作用还未被充分研究。
不同于上述模型, 本文将end-stopping机制引入自底向上显著图的计算框架, 通过模拟初级视皮层V1中end-stopped神经元的特性来提取角点、边缘交叉点和曲率较大点等显著特征, 并与颜色、亮度、方向特征合并, 共同形成自底向上显著图的表达。在公开的眼动数据集上, 将模型输出的显著图与人眼真实数据进行了比较, 结果显示模型能够较好地估计人眼注视位置; 与其他模型的对比结果显示, 本文方法达到了当前自底向上显著模型的领先水平, 部分指标优于早期的基于深度学习的自顶向下模型。
1 基于end-stopping机制的显著模型
早期的视觉注意力模型认为显著图在额顶叶等高级视皮层中形成, 但最新研究表明, 自底向上显著图在初级视皮层V1中就已生成[7]。在V1中, 信号按照简单细胞→复杂细胞→end-stopped细胞(曾被称为超复杂细胞), 完成由低级到高级的整合过程。另外, 心理学实验也证实end-stopping刺激物具有高显著性[8], 因此end-stopped细胞对于自底向上显著图的形成具有重要意义。
本文考虑将end-stopping机制引入自底向上显著图的计算框架, 用于提取角点、边缘交叉点和曲率较大点等显著特征(本文中统称为end-stopping特征), 将其与方向特征一起作为V1显著图表达, 并融合代表侧膝体输出的亮度和颜色特征, 合并得到自底向上显著图, 整个流程如图 1所示。
在end-stopping机制的建模上, 本文借鉴了[9]提出的一种理想模型, 首先通过2D Gabor函数模拟简单细胞感受野, 然后提取Gabor响应振幅作为复杂细胞响应, 最后将2个不同朝向的复杂细胞响应乘积作为end-stopped细胞的响应。该模型成功模拟了V1皮层中end-stopped细胞的大部分特性, 计算较为简便, 符合自底向上注意快速分析场景信息的特点。
 |
图1 基于end-stopping机制的显著模型 |
1.1 图像通道分解
视网膜中的视锥细胞对可见光谱中的不同波长敏感, 对应于长(L)、中(M)和短(S)波长, 视杆细胞则对亮暗变化敏感。视网膜和侧膝体中的神经节细胞具有中心-周边拮抗型感受野, 将亮度和彩色信号作为一个对立成分来处理, 从视锥细胞响应分离出“红-绿”(R-G)通道和“蓝-黄”(B-Y)通道, 从视杆细胞响应分离出亮度通道(L), 并沿侧膝体(LGN)并进入V1。
CIE Lab颜色空间常被用来描述上述过程, L, a和b通道可看作下式中定义的R-G、B-Y和L对立颜色表示
 1
1
1.2 end-stopping特征提取
LGN输出的对立颜色成分进入V1层后, 按照简单细胞→复杂细胞→end-stopped细胞(曾被称为超复杂细胞), 完成由低级到高级的逐层整合。简单细胞和复杂细胞都具有方向和空间频率选择性, 我们首先对L, a, b通道分别进行2D Gabor滤波来提取简单细胞响应
 2
2
式中,σ为高斯滤波方差, 控制感受野大小, θ是细胞朝向, 波长为λ, 带宽取σ/λ=0.56。2D Gabor滤波的实部和虚部分别对应偶、奇对称滤波器, 通过卷积计算出响应值, 表示对当前方向的响应强度。
复杂细胞建模为Gabor响应振幅, 即奇偶滤波器对图像响应的模值
 3
3
式中,Re和Im分别是Gabor响应的实部和虚部, 尺度s对应不同的波长λ, θ=(i-1)π/N, N是选取的方向角度个数。
文献[9]将end-stopped细胞建模为相邻2个朝向的复杂细胞响应乘积, 当细胞朝向角度差异大于20°、小于等于30°时效果最好, 因此我们取N=8使得角度差为22.5°, 尺度因子s为6。每幅end-stopping特征图的计算公式为
 4
4
式中,θi=(i-1π)/N, Cθ(x, y)表示最优朝向为θ的复杂细胞响应之和, 是对V1中方位功能柱的模拟
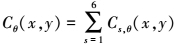 5
5
end-stopped细胞会受到其他相邻神经元的长距离抑制, 可以用高斯差分(difference of Gaussian)算子来模拟这种机制, 以抑制邻域中的近似响应
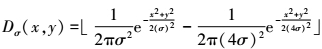 6
6
实验中σ取输入图像宽度的0.02倍,  =max(x, 0)。所有特征图被抑制后加权相加得到end-stopping显著图
=max(x, 0)。所有特征图被抑制后加权相加得到end-stopping显著图
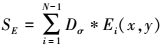 7
7
SE中像素值越高, 表示该位置同时存在多个方向响应的可能性越大, 该像素是角点、线交叉点或曲率点的概率越大。
1.3 自底向上显著图
自底向上显著图主要在V1层形成, V1层中end-stopped细胞大约占25%, 其余大部分为具有方向选择性的简单和复杂细胞, 另外侧膝体输出的对立颜色和亮度信息也有一定贡献, 因此将end-stopping特征图和文献[2]中的亮度、颜色、方向特征合并, 形成自底向上显著图的完整表达。
各通道特征图具有不同的动态范围和提取机制, 其重要性也各不相同, 合并前需要进行归一化。文献[2]提出的归一化算子包括归一化和加权2个步骤, 模拟了皮层的侧抑制机制。但该方法在只有一个强峰值时有效, 存在多个同等峰值的特征图会被忽略。本文采用了基于局部峰数量的归一化加权方法
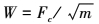 8
8
式中,F是各特征通道C上归一化后的特征图, m为全局峰值附近范围内的局部峰数量。通过除以局部峰值数量的平方根, 局部峰较少的特征图得到增强而整体存在大量局部峰的特征图被抑制。加权后的各特征图直接相加, 形成最终显著图。
2 实验
视觉显著模型研究一般有2个目的:①根据模型生成的显著图来研究视觉注意力机制; ②预测注视点位置并将其用于计算机视觉的其他领域。我们对模型的注视点预测性能进行了评估, 即以人眼眼动数据生成的注视图(fixation map)作为真实值(ground truth), 将模型输出显著图与之进行对比。
2.1 评价指标
本文使用sAUC、CC和NSS这3种最常见的评价指标, 以提供最公平的对比评估结果。其中sAUC用于描述模型对显著区域检测的准确性, CC和NSS用于描述模型输出的显著图与人眼注视图的一致性或相关性。
sAUC(AUC-shuffled)是对AUC的改进。AUC曾是显著模型中使用最广泛的评价指标, 它将显著图看作二值分类器, 显著值在阈值之上的点被视为正样本(注视点), 阈值之下的作为负样本(非注视点), 人眼注视点为真值, AUC值是以真阳性率和假阳性率为坐标轴绘制成的ROC曲线下方区域面积。与AUC不同, sAUC将其他图像上的注视点作为负样本, 从而将中心偏差也引入假阳性率的计算, 因而不易受到中心偏差效应的影响。
归一化扫描路径显著性(NSS)是归一化后的显著图在注视点位置的平均值, 用来衡量每一次扫视时显著图与人眼注视图之间的关联程度。NSS越大, 眼动位置预测越准确, 值为1表示眼动位置落在预测区域的密度高于平均值一个标准差。
线性相关系数(CC)在显著模型中常被用于衡量模型估计的显著图与人眼注视图之间的相关性。CC值越接近1, 2幅图越相似。
2.2 数据集和模型
本文采用的数据集为Toronto和MIT1003[10-11]:Toronto数据集包含120幅分辨率为511*681的彩色图像, 其中大部分为不包含特定感兴趣区域的场景图像, 收集了20位观测者对每幅图观看3 s的眼动数据; MIT1003数据库包含分辨率不一、横向或竖向排列的1 003幅图像, 种类包括文本、人脸和室内外场景, 收集了15名受试者自由观看3 s数据, 2幅图像之间间隔1 s。
我们选择了4种显著模型(AWS[12], BMS[13], Cor[4], eDN[14])进行对比, 其中AWS、BMS和Cor是最新的、性能最优的自底向上模型, eDN是首个基于深度学习的显著模型, 另外我们还将end-stopping显著图ES加入对比。
3 结果与讨论
3.1 直观对比
本文模型与其他对比模型在Toronto数据集上的部分显著图结果如图 2所示。可以看出本文模型的显著图与人眼真实眼动数据较为接近, 能够准确预测注视点位置。
与其他模型相比, 本文模型更关注物体边界上的轮廓和边缘信息。这是因为我们通过复杂细胞响应相乘的方式建模end-stopped细胞, 角点(遥控器、显示器的四角)、线交叉点(自行车骨架联结点)和曲率点(手指弯曲处)等对多个方向存在响应的特征被检测出来, 同时方向响应代表的物体边缘也得到一定保留。end-stopping显著图主要感知物体轮廓信息, 而对物体内部或与物体无关的显著区域关注不足, 因此我们加入了颜色和亮暗特征, 完善了自底向上显著图的表达。另外, 模型对长边缘具有一定的抑制作用, 与end-stopped细胞对长边缘不敏感的特性吻合。
 |
图2 各模型在Toronto数据集上的部分显著图 |
3.2 性能对比
表 1和表 2分别给出了各模型在Toronto和MIT1003数据集上的性能对比结果。在Toronto数据集上, 本文模型的各项指标均略低于BMS而高于AWS和Cor; sAUC值略高于Cor模型, 而CC和NSS值有大幅提升; 与eDN相比, 本文方法CC和NSS较低, 但在sAUC上具有明显优势。MIT1003数据集上的对比结果大体相似, 唯一不同的是本文模型的各项指标低于AWS模型, 但差距很小。end-stopping显著图各项指标略低于最终显著图, 其sAUC明显高于eDN模型, CC和NSS较Cor模型具有优势, 表明本文中的end-stopping特征能够有效提取显著区域。
2个数据集上的对比结果显示, 本文模型性能与当前最好的3种自底向上模型相当, 部分指标优于基于深度学习的eDN模型。
Toronto数据集上各模型的性能评价指标
MIUT1003数据集上各模型的性能评价指标
3.3 中心偏差效应
中心偏差效应是指观察者的眼动数据通常会更加偏向图像中心, 部分显著模型利用这一点, 对图像中心进行高斯模糊而获得较高的分数, 从而产生不公平的性能对比结果。除sAUC外的大部分评价指标都容易受到中心偏差的影响, 由于sAUC的特性, 其对高斯模糊具有良好的抗干扰能力, 我们通过绘制不同高斯模糊标准差std下的sAUC变化曲线, 分析了模型对中心偏差效应的鲁棒性。
图 3和图 4给出了各模型在Toronto数据集上的sAUC-std曲线。本文模型的sAUC峰值略低于BMS模型而明显高于其他模型, end-stopping显著图的sAUC峰值略低于BMS和AWS模型。与其他模型相比, 本文模型的sAUC曲线变化较为平缓, 表示模型对高斯模糊std值不敏感, 受中心偏差效应的影响较小。
 |
图3 模型在Toronto数据集上的sAUC-std曲线 |
 |
图4 模型在MIT1003数据集上的sAUC-std曲线 |
4 结论
本文提出了一种生物启发的视觉显著模型, 引入初级视皮层V1中的end-stopping机制以提取角点、边缘交叉点和线段端点等特征, end-stopped细胞响应与V1中简单/复杂细胞的方向响应, 以及LGN输出的亮度、颜色特征一起形成自底向上显著图的完整表达。
在2个公开数据集上, 模型与3种自底向上模型及一种深度学习模型进行了对比, 结果表明本文模型达到了当前自底向上显著模型的先进水平, 且对中心偏差效应具有较强的抗干扰能力。其原因是, 本文提取的end-stopping特征表征潜在的物体形状和轮廓信息, 相对于颜色、亮度等低层特征, 物体在场景中往往更易吸引人的注意。但由此带来的问题是, 对于场景中较大的物体, end-stopping特征难以预测物体内部的注视点位置; 另外当场景中不存在显著物体时, 具有较高明暗、亮度对比度的区域最具显著性, 因此模型加入了亮度和颜色特征来计算最终显著图。
本文将end-stopping机制引入显著模型计算框架, 对视觉显著性和注意力研究具有2点贡献:第一, 验证了将end-stopping机制用于显著图计算的可行性; 第二, 通过建模end-stopped细胞, 对包含视网膜、侧膝体和V1输出的自底向上显著图, 形成了一个初步的完备表达。本文提出的显著模型在注视点预测性能上未能超越其他方法, 这可能是由于V1中end-stopped细胞的生理结构和作用机制还不是十分明晰, 所以本文采用了一种计算上较为简便的end-stopping理想模型, 更准确的建模方法有赖于视觉神经生理机制的未来进展, 以建立更加完备、准确的自底向上显著模型, 这对于自底向上注意机制的研究具有重要意义。
References
- BorjiA, IttiL. State-of-the-Art in Visual Attention Modeling[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2013, 35(1): 185-207 [Article] [CrossRef] [MathSciNet] [Google Scholar]
- IttiL, KochC, NieburE. A Model of Saliency-Based Visual Attention for Rapid Scene Analysis[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 1998, 20(11): 1254-1259 [Article] [Google Scholar]
- PonceC R, HartmannT S, LivingstoneM S. End-Stopping Predicts Curvature Tuning along the Ventral Stream[J]. Journal of Neuroscience, 2017, 37(3): 648-659 [Article] [CrossRef] [Google Scholar]
- Rueopas W, Leelhapantu S, Chalidabhongse T H. A Corner-Based Saliency Model[C]//20161 3th International Joint Conference on Computer Science and Software Engineering, 2016: 1-6 [Google Scholar]
- Zhang X, Ma S, Gao W, et al. A Study on Interest Point Guided Visual Saliency[C]//Symposium on Picture Coding, 2015: 307-311 [Google Scholar]
- DanX. Object Detection Based on Saliency Map[J]. Journal of Computer Applications, 2010, 30(suppl 2): 82-85 [Article] [CrossRef] [Google Scholar]
- YanY, ZhaoP L, LiW. Bottom-up Saliency and Top-Down Learning in the Primary Visual Cortex of Monkeys[J]. Proceedings of the National Academy of Sciences, 2018, 115(41): 10499-10504 [Article] [CrossRef] [Google Scholar]
- PoirierF J, GosselinF, Arguin, et al. Perceptive Fields of Saliency[J]. Journal of Vision, 2008, 8(15): 14-19 [Article] [CrossRef] [Google Scholar]
- SkottunB C. A Model for End-Stopping in the Visual Cortex[J]. Vision Research, 1998, 38(13): 2023-2035 [Article] [CrossRef] [Google Scholar]
- BruceN D, TsotsosJ K. Attention Based on Information Maximization[J]. Journal of Vision, 2007, 7(9): 950 [Article] [CrossRef] [Google Scholar]
- Judd T, Ehinger K A, Durand F, et al. Learning to Predict Where Humans Look[C]//2009 IEEE 12th International Conference on Computer Vision, 2010: 2106-2113 [Google Scholar]
- LeboranV, GarciadiazA, FdezvidalX R, et al. Dynamic Whitening Saliency[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2017, 39(5): 893-907 [Article] [CrossRef] [Google Scholar]
- ZhangJ, SclaroffS. Exploiting Surroundedness for Saliency Detection:A Boolean Map Approach[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2016, 38(5): 889-902 [Article] [CrossRef] [Google Scholar]
- Vig E, Dorr M, Cox D. Large-Scale Optimization of Hierarchical Features for Saliency Prediction in Natural Images[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014: 2798-2805 [Google Scholar]
All Tables
All Figures
|
图1 基于end-stopping机制的显著模型 |
| In the text | |
|
图2 各模型在Toronto数据集上的部分显著图 |
| In the text | |
|
图3 模型在Toronto数据集上的sAUC-std曲线 |
| In the text | |
|
图4 模型在MIT1003数据集上的sAUC-std曲线 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.