| Issue |
JNWPU
Volume 39, Number 4, August 2021
|
|
|---|---|---|
| Page(s) | 901 - 908 | |
| DOI | https://doi.org/10.1051/jnwpu/20213940901 | |
| Published online | 23 September 2021 | |
A new end-to-end image dehazing algorithm based on residual attention mechanism
基于残差注意力机制的图像去雾算法
School of Computer and Information Engineering, Tianjin Chengjian University, Tianjin 300384, China
Received:
17
December
2020
Abstract
Traditional image dehazing algorithms based on prior knowledge and deep learning rely on the atmospheric scattering model and are easy to cause color distortion and incomplete dehazing. To solve these problems, an end-to-end image dehazing algorithm based on residual attention mechanism is proposed in this paper. The network includes four modules: encoder, multi-scale feature extraction, feature fusion and decoder. The encoder module encodes the input haze image into feature map, which is convenient for subsequent feature extraction and reduces memory consumption; the multi-scale feature extraction module includes residual smoothed dilated convolution module, residual block and efficient channel attention, which can expand the receptive field and extract different scale features by filtering and weighting; the feature fusion module with efficient channel attention adjusts the channel weight dynamically, acquires rich context information and suppresses redundant information so as to enhance the ability to extract haze density image of the network; finally, the encoder module maps the fused feature nonlinearly to obtain the haze density image and then restores the haze free image. The qualitative and quantitative tests based on SOTS test set and natural haze images show good objective and subjective evaluation results. This algorithm improves the problems of color distortion and incomplete dehazing effectively.
摘要
传统基于先验知识与基于学习的图像去雾算法依赖大气散射模型,容易出现颜色失真和去雾不彻底的现象。针对上述问题,提出一种端到端的基于残差注意力机制的图像去雾算法,该算法网络包括编码、多尺度特征提取、特征融合和解码4个模块。编码模块将输入的雾图编码为特征图像,便于后续特征提取并减少内存占用;多尺度特征提取模块包括残差平滑空洞卷积模块、残差块和高效通道注意力机制,能够扩大感受野并通过加权筛选提取的不同尺度特征以便融合;特征融合模块利用高效通道注意力机制,动态调整不同尺度特征的通道权重,学习丰富的上下文信息并抑制冗余信息,增强网络提取雾霾密度图像的能力从而使去雾更加彻底;解码模块对融合后的特征进行非线性映射得到雾霾密度图像,进而恢复无雾图像。通过在SOTS测试集和自然有雾图像上进行定量和定性的测试,所提方法取得了较好的客观和主观评价结果,并有效改善了颜色失真和去雾不彻底的现象。
Key words: image dehazing / deep learning / channel attention mechanism / residual smoothed dilated convolution / feature extraction
关键字 : 图像去雾 / 深度学习 / 通道注意力机制 / 残差平滑空洞卷积 / 特征提取
© 2021 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
在雾霾天气下,由于大气中存在浑浊的介质,导致采集到的图像具有对比度低、整体颜色偏灰暗,物体特征不明显、图像细节模糊等现象,这严重影响了基于图像的智能信息处理系统的鲁棒性和有效性[1]。因此图像去雾成为诸如图像分类、检测、分割等高级视觉任务的前提,如何提高图像去雾的效果也成为计算机视觉领域的一个重要问题。
图像去雾方法包括基于图像增强的方法、基于图像复原的方法和基于深度学习的方法。基于图像增强的方法,如直方图均衡化[2]、Retinex理论[3]等,直接对低质量的图像做增强处理,可能会造成图像信息损失和失真;基于图像复原的方法,如暗通道先验(dark channel prior, DCP)[4]、颜色衰减先验(color attenuation prior, CAP)[5]等,利用先验知识和假设并基于物理模型来对图像进行恢复,恢复效果自然,其中最具代表性的是He等人提出的暗通道先验方法,但该方法过高估计雾的浓度,导致去雾后图像整体亮度偏暗,且天空区域常出现颜色失真现象。尽管上述算法取得了较大的进步,但它们仍依赖先验知识,具有一定的局限性。
基于深度学习的方法可分为间接去雾方法和直接去雾方法。间接去雾方法首先需要估计大气光值、透射率或者其他中间变量,然后根据大气散射模型恢复无雾图像。Cai等[6]首次使用卷积神经网络(convolutional neural networks, CNN)来估计雾图透射率,提出了DehazeNet网络。Ren等[7]提出了多尺度的深层卷积神经网络(multi-scale convolutional neural networks, MSCNN)来学习雾图到透射率之间的映射关系,该网络分2个阶段来训练雾图粗糙和细化的透射率,并使用跳跃连接进行相连。Li等[8]对大气散射模型进行变换,将透射率和大气光值统一表示为参数K,并借鉴了文献[6-7]的多尺度和跳跃连接,提出了一种通过估计参数K来恢复无雾图像的卷积神经网络(all-in-one dehazing network, AOD-Net)。上述间接去雾方法取得了不错的去雾效果,但过于依赖大气散射模型,往往出现对透射率过度估计,且大多数方法将大气光值设置为全局常量,导致去雾后的图像容易出现颜色失真现象。直接去雾方法不依赖大气散射模型,端到端地学习雾图到无雾图像之间的映射关系。Li等[9]提出基于条件生成对抗(conditional generative adversarial networks, CGAN)的可训练去雾网络,并引入VGG特征和L1正则化梯度先验构建损失函数。Chen等[10]提出门控上下文聚合去雾网络(gated context aggregation network, GCANet),引入平滑空洞卷积并设计了门控融合网络。Qu等[11]提出了一个增强的pix2pix去雾网络(enhanced pix2pix dehazing network, EPDN),直接学习有雾图像和无雾图像之间的映射关系。Shao等[12]提出一种域适应(domain adaptation)去雾网络,采用双向变换网络,将图像从一个域变换到另一个域,以弥补合成域和真实域之间的差距,并使用变换前、后的图像来训练所提出的去雾网络。上述直接去雾方法在一定程度上提高了所恢复无雾图像的质量,但依然存在部分区域去雾不彻底或过度去雾的现象。受注意力机制的启发,Tian等[13]提出一种注意力引导的卷积神经网络用于图像去噪,使用注意力模块来指导卷积神经网络进行去噪训练,提高了效率并降低了模型的复杂性。Chen等[14]提出了一种基于特征注意力机制的超分辨率重建网络,将特征提取模块与注意力机制相结合,以便从低分辨率图像中提取有用的特征,重建的图像取得了更好的视觉效果。上述算法使用注意力机制,通过快速浏览全局信息来选择对象区域,并赋予关注对象区域较大的权重,以抑制其他无用信息,能够有效提高网络的性能和效率。因此,为了更加关注雾图的有用信息,本文所设计的去雾网络引入了注意力机制。
针对颜色失真和去雾不彻底的问题,本文提出基于残差注意力机制的图像去雾算法,端到端地预测雾霾密度图像,实现无雾图像的恢复。为了在不降低分辨率的情况下获取多尺度信息,提出了包含残差平滑空洞卷积的多尺度特征提取模块;设计了特征融合模块实现多尺度特征有效融合,提高了网络的效率和性能。实验结果表明本文算法无论在定性还是定量上都具有一定的优势,并通过消融实验验证了本文所提主要模块的有效性。本文主要创新点如下:
1) 提出基于残差注意力机制的图像去雾算法,不依赖大气散射模型端到端地预测雾霾密度图像,从而实现了无需计算透射率和大气光值即可恢复无雾图像,避免了估计大气光值带来的颜色失真现象,同时减少了计算成本。
2) 提出多尺度特征提取模块。利用平滑空洞卷积,通过设置不同空洞率来提取特征图的不同感受野信息,从而提取多尺度特征,并在扩大感受野的同时避免了网格伪影现象;利用高效通道注意力机制(efficient channel attention, ECA),通过加权筛选不同尺度的显著特征并替换原来特征向后传播,提高了网络的效率和性能;利用跳跃连接在保证网络加深的同时减少梯度消失。
3) 设计特征融合模块,堆叠压缩不同尺度特征后利用高效通道注意力机制,动态地调整其通道权重,学习丰富的上下文信息并抑制冗余信息,增强网络提取雾霾密度图像的能力从而使去雾更加彻底。
1 相关理论
1.1 大气散射模型
大多数图像去雾方法都采用大气散射模型来表示退化的图像,可以简化表示为:
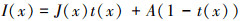 (1)
(1)
式中:x表示图像中的像素;I(x)表示输入的有雾图像;J(x)表示恢复的无雾图像;t(x)表示透射率;A表示大气光值。
基于先验的方法[4-5]和基于深度学习的方法[6-7], 均通过估计(1)式中的透射率t(x)和大气光值A来恢复无雾图像。但是对于大气光值A的估计一般采用经验方法, 从而容易导致恢复的无雾图像颜色失真, 因此基于大气散射模型进行图像去雾具有一定的局限性。
1.2 雾霾密度图像预测模型
为解决大气光值A估计不准确的问题, HDP-Net[15]根据雾图组成原理, 将大气散射模型重新定义为
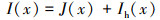 (2)
(2)
式中,Ih(x)表示雾霾密度图像。并提出了雾霾密度图像预测模型, 该模型表示为
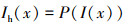 (3)
(3)
式中, P(·)表雾霾密度图像预测网络。则恢复的无雾图像可以表示为
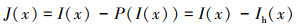 (4)
(4)
通过(4)式可知, 只需获得雾霾密度图像Ih(x), 便可从输入的有雾图像I(x)中恢复无雾图像J(x), 因此本文提出基于残差注意力机制的图像去雾算法端到端地预测雾霾密度图像Ih(x), 实现无雾图像恢复。
2 基于残差注意力机制的图像去雾算法
本文借鉴编码-解码结构[16]设计了基于残差注意力机制的图像去雾算法, 该算法的网络模型包括编码、多尺度特征提取、特征融合和解码4个模块。通过该网络预测雾霾密度图像Ih(x), 进而将输入的雾图I(x)与其相减获得最终的无雾图像J(x), 本文提出的整体网络结构如图 1所示。
 |
图1 基于残差注意力机制的图像去雾算法网络模型 |
2.1 编码模块
编码模块将输入的雾图转化为特征图像, 如图 1所示, 由2个卷积块(Conv1、Conv2)和一个下采样卷积块(Conv3) 组成, 卷积核大小均为3×3;卷积层的步长为1, 填充设置为1, 输入通道数为4。下采样卷积块的步长为2, 输出通道数为64。编码模块表示为
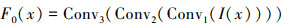 (5)
(5)
式中, F0(x)表示编码的特征图像。
2.2 多尺度特征提取模块
为了在不降低分辨率的情况下扩大感受野并提取不同尺度的特征, 本文设计了多尺度特征提取模块。如图 1所示, 该模块利用3组不同空洞率的特征提取模块(FEB1~FEB3), 通过提取特征图不同的感受野信息, 从而获得不同尺度的特征图。多尺度特征提取模块表示为
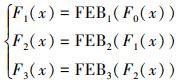 (6)
(6)
式中, F1(x), F2(x), F3(x)分别表示提取的不同尺度特征。每个特征提取模块(FEBi, i=1, 2, 3)均包含1个残差平滑空洞卷积模块(SDRBi)、2个结构相同的残差块(RB1i, RB2i)和1个高效通道注意力机制(ECAi)。特征提取模块FEBi(x)表示为
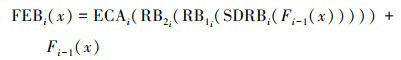 (7)
(7)
式中,Fi-1(x)表示当前输入的特征。
残差平滑空洞卷积模块如图 2所示, 包含2个平滑空洞卷积模块和跳跃连接。首先利用一个卷积核大小为(2r-1)×(2r-1), 步长为1,输出通道为64的分离共享卷积层[17]增强输入单元之间的依赖关系, 避免产生网格伪影现象; 然后利用一个卷积核大小为3×3, 步长为1, 输出通道为64的空洞卷积层扩大感受野; 最后利用实例归一化层和ReLU激活函数层加速模型收敛。同时利用跳跃连接避免梯度消失现象。SDRBi的空洞率r分别为2, 3, 4。残差平滑空洞卷积模块SDRBi(x)表示为
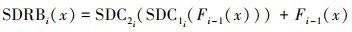 (8)
(8)
式中,SDCni(·), n=1, 2表示平滑空洞卷积函数。
残差块如图 3所示, 采用跳跃连接的方式, 提高了网络的学习能力。残差块包含2个卷积块和局部跳跃连接, 其中卷积块包含1个卷积核大小为3×3, 步长为1, 输出通道为64的卷积层, 1个实例归一化层和ReLU激活函数层。为了进一步提取当前尺度的特征, 残差平滑空洞卷积(SDRBi)后接两个残差块(RB1i和RB2i)来保证提取当前尺度特征的完整性。残差块RBi(x)表示为
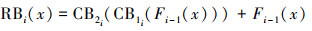 (9)
(9)
式中,CBni(·)表示卷积函数。
高效通道注意力机制[18]如图 4所示。首先进行不降维的全局平均池化; 其次自适应的确定一个卷积核大小为k×k的卷积层, 实现跨通道信息交互; 接着使用Sigmoid函数得到特征图的权重值; 最后使用特征图权重值调整输入特征图, 输出带权重的特征图。在每个特征提取模块(FEBi)中均使用高效通道注意力机制, 通过加权筛选出当前尺度的显著特征代替原来的特征向后传播, 提高了网络的效率和性能。高效通道注意力机制ECAi(x)表示为
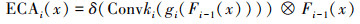 (10)
(10)
式中:gi(·)表示全局平均池化函数;Convki(·)表示卷积核大小为k×k的卷积函数;δ表示Sigmoid函数。
 |
图2 残差平滑空洞卷积模块SDRB结构图 |
 |
图3 残差块RB结构图 |
 |
图4 高效通道注意力机制ECA结构图 |
2.3 特征融合模块
为了将多尺度特征进行有效融合。如图 1所示, 特征融合模块首先将不同尺度的特征进行堆叠(Concat), 然后通过一个卷积核大小为3×3的卷积层将堆叠后的多尺度特征进行压缩, 其输入通道数为192, 输出通道数为64。堆叠并压缩后的特征Fcat(x)表示为
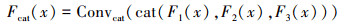 (11)
(11)
式中:Convcat(·)表示压缩的卷积函数;cat(·)表示拼接函数。不同尺度的特征堆叠压缩后再次使用高效通道注意力机制(ECA4), 动态调整其通道权重, 学习丰富的上下文信息并抑制冗余信息, 增强网络提取雾霾密度图像的能力从而使去雾更加彻底。特征融合模块Fc(x)表示为
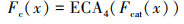 (12)
(12)
2.4 解码模块
解码模块与编码模块对称, 如图 1所示, 解码模块包含1个反卷积块(DeConv)和2个卷积块(Conv4、Conv5), 填充均设置为1。反卷积块的卷积核大小为4×4, 步长为2, 输入通道数为64;一个卷积块的卷积核大小为3×3, 步长为1;另一个卷积块的卷积核大小为1×1输出通道为3。解码模块将融合后的特征进行非线性映射得到雾霾密度图像, 解码模块表示为
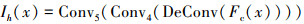 (13)
(13)
最终, 恢复的无雾图像J(x)表示为
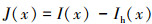 (14)
(14)
2.5 损失函数
大多数基于学习的图像去雾方法使用均方差损失(MSE)进行训练, 本文采用均方差损失函数来衡量网络预测的雾霾密度图像与真正雾霾密度图像之间的差异。均方差损失Lmse(x)表示为
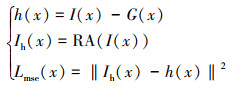 (15)
(15)
式中:h(x)为真正雾霾密度图像;G(x)为清晰图像;RA(·)为本文提出的残差注意力机制网络。
3 实验与结果分析
3.1 实验设置与数据集
实验环境为Win10操作系统, Intel(R)Core(TM)i7-7700CPU@3.60GHz处理器, 内存为16.0 GB, 显卡为NVIDIA GeForce GTX 1080。利用pytorch框架实现网络, 使用Adam对网络进行优化, 训练的批量大小为12, 初始学习率为0.01且每40次迭代学习率衰减为原来的0.1倍, 迭代次数为100次。
数据集采用公开的图像去雾RESIDE[19]数据集, 包括5个子集, 其中2个训练集分别为室内训练集(indoor training set, ITS)和室外训练集(outdoor training set, OTS); 3个测试集分别为综合客观测试集(synthetic objective testing set, SOTS)、混合主观测试集(hybrid subjective testing set, HSTS)和真实有雾图像测试集(real-world task-driven testing set, RTTS)。实验选取ITS作为训练集, 将本文算法与近些年具有优势的算法进行对比, 包括DCP[4]、CAP[5]、AOD-Net[8]、DehazeNet[6]和GCANet[10]。
3.2 在合成数据上实验
本实验对合成数据集进行测试, 并与经典方法进行定量和定性的比较。选用峰值信噪比和结构相似度[19]来评估去雾结果的好坏, 值越高代表去雾的效果越好。
各方法的峰值信噪比和结构相似度如表 1所示。
对于峰值信噪比, DCP方法、CAP方法和AOD-Net方法都在20.00以下, DehazeNet方法比AOD-Net方法提高了2.08, GCANet方法的峰值信噪比达到30.23, 较前4种方法有很大提升, 本文方法的峰值信噪比较GCANet方法提高了4.28。对于结构相似度, 前4种方法均未达到0.900 0, GCANet方法的结构相似度最高, 本文方法的结构相似度较GCANet方法略低0.004 6, 但相较于其他算法, 仍有较高的提升。
另外,在SOTS室内测试集中选择4张不同浓度的雾图,进行主观质量的评价。各方法的去雾效果以及对应的峰值信噪比如图 5所示。DCP方法恢复的图像出现了颜色失真的现象,整体颜色较深,且不适合高亮度区域的恢复(见图 5b)中的透光区域)。CAP方法恢复的图像颜色偏深(见图 5c)中的桌面区域),并且在浓雾的情况下,图像出现去雾不彻底的现象(见图 5c)中后3幅图远景处)。AOD-Net方法恢复的图像出现颜色失真(见图 5d)中的桌面区域颜色偏深)和去雾不彻底的现象(见图 5d)中的浓雾区域)。DehazeNet方法恢复的图像能保持原来的色彩,但是在去除浓雾时容易出现去雾不彻底的现象(见图 5e)中的浓雾区域)。GCANet方法去雾效果不错,但在某些区域仍出现颜色失真(见图 5f)中的窗帘和柜子区域)。本文的去雾方法,表现出了较好的去雾效果,未出现可见颜色失真现象,对于浓雾图像去雾较为彻底,并且恢复的图像细节和色彩更接近原始清晰图像。
在SOTS室内数据集上峰值信噪比和结构相似度
 |
图5 SOTS室内合成有雾图像的实验结果 |
3.3 在真实数据上实验
为了进一步验证本文提出的基于残差注意力机制的图像去雾算法的有效性,选取RESIDE中的RTTS真实有雾数据集和网络上常见的现实世界雾天图像作为自然雾图测试集,将本文算法与对比算法在上述自然雾图测试集上进行比较。去雾结果如图 6所示。对于前3幅薄雾图,DCP方法恢复的图像颜色失真,如图 6b)中第二、三幅图中建筑物的颜色偏深;另外,该方法恢复天空区域容易出现失真现象,如图 6b)中第一幅图天空区域出现黄色,第二幅图天空区域出现黑色。CAP方法恢复的图像颜色过深,如图 6c)中第二幅图近景处出现黑色;另外,该方法恢复的图像出现了去雾不彻底现象,如图 6c)中第一、三幅图的远景处。AOD-Net方法虽然可以去除部分雾,但恢复的图像缺少细节,如图 6d)中第二幅图远处的建筑物细节模糊不清,第一、三幅图均存在去雾不彻底现象;另外,该方法恢复的图像容易出现颜色失真现象,如图 6d)中第二幅图近处的建筑物区域颜色过深。DehazeNet方法对于远景处的雾去除效果不佳,如图 6e)中第二幅图远处的雾仍有残余;第一、三幅图也出现了去雾不彻底的现象。GCANet方法虽然取得了较好的去雾效果,但存在去雾不均匀的现象,如图 6f)中第一幅图天空区域出现不均匀色块,第二幅图最远处的高楼区域比较模糊。本文算法得到的图像去雾效果优于上述算法,既能较为彻底的去雾,又能恢复视觉效果较好的清晰图像。对于最后一幅浓雾图像,所有的方法均未能彻底的去雾,但本文算法能够恢复出远处建筑轮廓,对比其他算法在去除浓雾方面有一定进步,但也出现了部分区域颜色失真现象。
 |
图6 真实场景有雾图像实验结果 |
3.4 消融实验
为了验证本文所提多尺度特征提取和特征融合模块的有效性,在SOTS室内测试集上进行如下消融实验:①特征提取模块使用普通卷积层替换SDRB中的空洞卷积层,仅提取相同尺度的特征,并且特征融合模块不使用ECA模块;②特征提取模块使用普通卷积层,特征融合模块使用ECA模块;③特征提取模块使用空洞卷积,特征融合模块不使用ECA模块。上述实验的峰值信噪比和结构相似度如表 2所示。从表 2可以看出,仅使用特征融合模块(实验2)和仅使用多尺度特征提取模块(实验3)比二者均不使用(实验1)的峰值信噪比分别提升了0.62和0.94;同时利用2个模块(本文算法)比实验2和实验3的峰值信噪比分别提升了1.65和1.33;并且本文算法的结构相似度较其他3组实验均有提升。因此本文提出的多尺度特征提取模块和包含ECA的特征融合模块具有实际的有效性。
在SOTS室内数据集上峰值信噪比和结构相似度比较
4 结论
本文提出了基于残差注意力机制的图像去雾算法,端到端地预测雾霾密度图像进行去雾。网络设计基于编码-解码结构,方便后续特征提取并且减少内存占用;利用多尺度特征提取和特征融合模块对不同尺度特征进行有效提取和融合,在其每个模块末尾均使用了高效通道注意力机制,自适应地使显著特征具有较大权重,抑制了冗余信息,增强了网络恢复雾霾密度图像的性能从而令去雾更加彻底。本文方法不依赖大气散射模型,有效地改善了颜色失真和去雾不彻底的现象,提高了网络性能,针对合成图像和现实场景中的雾图均表现出了良好的去雾效果。
References
- Wu Di, Zhu Qingsong. The latest research progress of image dehazing[J]. Acta Automatica Sinica, 2015, 41(2): 221–239 [Article] (in Chinese) [NASA ADS] [Google Scholar]
- Stark J A. Adaptive image contrast enhancement using generalizations of histogram equalization[J]. IEEE Trans on Image Processing, 2000, 9(5): 889–896 [Article] [NASA ADS] [CrossRef] [Google Scholar]
- Cooper T J, Baqai F A. Analysis and extensions of the Frankle-Mccann retinex algorithm[J]. Journal of Electronic Imaging, 2004, 13(1): 85–92 [Article] [NASA ADS] [CrossRef] [Google Scholar]
- He K, Sun J, Fellow, et al. Single image haze removal using dark channel prior[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2011, 33(12): 2341–2353 [Article] [CrossRef] [Google Scholar]
- Zhu Q, Mai J, Shao L. A Fast single image haze removal algorithm using color attenuation prior[J]. IEEE Trans on Image Processing, 2015, 24(11): 3522–3533 [Article] [NASA ADS] [CrossRef] [Google Scholar]
- Cai B, Xu X, Jia K, et al. Dehaze net: an end-to-end system for single image haze removal[J]. IEEE Trans on Image Processing, 2016, 25(11): 5187–5198 [Article] [NASA ADS] [CrossRef] [Google Scholar]
- Ren W, Liu S, Zhang H, et al. Single image dehazing via multi-scale convolutional neural networks[C]//European Conference on Computer Vision, 2016: 154–169 [Google Scholar]
- Li B, Peng X, Wang Z, et al. AOD-net: all-in-one dehazing network[C]//2017 IEEE International Conference on Computer Vision, 2017: 4770–4778 [Google Scholar]
- Li R, Pan J, Li Z, et al. Single image dehazing via conditional generative adversarial network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 8202–8211 [Google Scholar]
- Chen D, He M, Fan Q, et al. Gated context aggregation network for image dehazing and deraining[C]//2019 IEEE Winter Conference on Applications of Computer Vision, 2019: 1375–1383 [Google Scholar]
- Qu Y, Chen Y, Huang J, et al. Enhanced pix2pix dehazing network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019: 8160–8168 [Google Scholar]
- Shao Y, Li L, Ren W, et al. Domain adaptation for image dehazing[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 2808–2817 [Google Scholar]
- Tian C, Xu Y, Li Z, et al. Attention-guided CNN for image denoising[J]. Neural Networks, 2020, 124: 117–129 [Article] [Google Scholar]
- Chen Y, Liu L, Phonevilay V, et al. Image super-resolution reconstruction based on feature map attention mechanism[J]. Applied Intelligence, 2021, 51(8): 1–14 [Article] [Google Scholar]
- Liao Y, Su Z, Liang X, et al. HDP-net: haze density prediction network for nighttime dehazing[C]//Pacific Rim Conference on Multimedia, 2018: 469–480 [Google Scholar]
- Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention, 2015: 234–241 [Google Scholar]
- Wang Z, Ji S. Smoothed dilated convolutions for improved dense prediction[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018: 2486–2495 [Google Scholar]
- Wang Q, Wu B, Zhu P, et al. ECA-net: Efficient channel attention for deep convolutional neural networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 11534–11542 [Google Scholar]
- Li B, Ren W, Fu D, et al. Benchmarking single-image dehazing and beyond[J]. IEEE Trans on Image Processing, 2018, 28(1): 492–505 [Google Scholar]
All Tables
All Figures
|
图1 基于残差注意力机制的图像去雾算法网络模型 |
| In the text | |
|
图2 残差平滑空洞卷积模块SDRB结构图 |
| In the text | |
|
图3 残差块RB结构图 |
| In the text | |
|
图4 高效通道注意力机制ECA结构图 |
| In the text | |
|
图5 SOTS室内合成有雾图像的实验结果 |
| In the text | |
|
图6 真实场景有雾图像实验结果 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.