| Issue |
JNWPU
Volume 42, Number 4, August 2024
|
|
|---|---|---|
| Page(s) | 744 - 752 | |
| DOI | https://doi.org/10.1051/jnwpu/20244240744 | |
| Published online | 08 October 2024 | |
Research on metal surface specular removal algorithm based on unsupervised learning
基于无监督学习的金属表面高光去除算法研究
1
School of Software, Northwestern Polytechnical University, Xi'an 710072, China
2
Department of Mechanical Engineering, Tsinghua University, Beijing 100084, China
3
Shanghai Aerospace Precision Machinery Research Institute, Shanghai 201699, China
Received:
20
July
2023
Abstract
The highlights on the surface of metal materials can seriously destroy the continuity of the image, produce certain false edges, and cause the texture details in the highlights area to weaken or even disappear, which interferes with the subsequent operations such as surface region segmentation and defect detection. Aiming at the low efficiency, high loss, easy distortion and difficult calibration of metal highlight data, an unsupervised perceptual enhancement network model based on the convolutional neural network (CNN) is proposed. Firstly, the method of generating antagonism is used to generate a large number of metal images with high-light feature information, which is used to increase the number of high-light metal image data sets in the training set. Secondly, a detail enhance model(DEM) and a color enhance model(CEM) are introduced into the context aggregation network to improve the feature detail retention rate in the low resolution weight graphs. Finally, the multi-scale structural similarity function is used to replace the original structural similarity function to solve the insensitive detail when the image size is too large. Experiments show that comparing with other multi-exposure image fusion models, the present model can improve the evaluation index of mutual information and average gradient of fused images by about 10%, and can retain more texture feature information.
摘要
金属材料表面的高光会严重破坏图像的连续性, 产生一定的伪边缘, 导致高光区域的纹理细节减弱甚至消失, 干扰后续表面的区域分割和缺陷检测等操作。针对现有高光去除方法效率低、损失大、易失真、金属高光数据难标定等问题, 提出了一种基于卷积神经网络(CNN)的无监督感知增强网络模型。使用生成对抗的方法生成大量拥有高光特征信息的金属图像, 用于增加训练集中高光金属图像数据集的数量; 在上下文聚合网络中引入细节增强模块(detail enhance model, DEM)和色彩增强模块(color enhance model, CEM)提高低分辨率权重图中的特征细节保留率; 评估函数采用多尺度结构相似性函数代替原有结构相似性函数, 解决在图像尺寸过大时细节不敏感的问题。实验表明, 所提模型相比其他多曝光图像融合模型, 在融合速度领先情况下, 融合图像的互信息和平均梯度等评估指数提升10%左右, 能够保留更多的纹理特征信息。
Key words: highlight removal / unsupervised learning / MEF / image fusion /
关键字 : 高光去除 / 无监督学习 / MEF / 图像融合 / 感知增强
© 2024 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
在智能制造推动下,机器视觉不断深入应用于制造行业的各个领域,使用计算机视觉完成工艺检测工作已成为智能装备的主流趋势。以视觉为主导的智能制造产业不断进步与创新,在实际工业复杂环境下的应用也越来越广泛。利用机器视觉集合工业大数据对在机加工件进行实时缺陷检测,可以及时发现加工过程中的问题,也可以在一定程度上解决人工检测带来的不确定性和低效率问题。
然而目前的机器视觉都需要基于高质量的图像来发挥作用,带有高光的金属图像不满足高质量的要求。由金属材料构成的航空发动机大部分组成部件在工业复杂光线条件下易产生高光区域,导致该区域的纹理细节以及特征信息缺失,并且金属特性容易导致其表面产生极端高光的情况。极端的高曝光使得金属曲面上信息丢失,干扰后续视觉检测过程,通过此类高光图像无法获得完整信息。因此,金属表面的高光去除对于后续以机器视觉为主的智能检测系统具有重要意义。
基于输入图像的数量,高光去除方法可以分为2类:基于单图像的方法和基于多图像的方法。高光去除的早期研究始于1985年Shafer[1]的双色反射模型,该模型首次将图像中的高光分解为镜面反射和漫反射2种分量,其中前者的光谱分布与光源的相似,而后者的光谱分布在很大程度上取决于材料表面的属性,根据该模型使用图像的颜色分析和光谱分析便可以消除图像高光。后续学者们基于此模型,发展出了很多基于单图像的高光去除算法模型。然而基于单图像的方法大都会使用像素填充,在图像纹理或者光线环境较复杂情况下高光去除效果差[2], 单图像方法在高光区域信息完全被掩盖情况下通常只能降低区域亮度,不能保留其中的纹理信息和色度信息。
随着计算机运算能力的增长以及图像处理算法对高质量图像数量需求的增多,基于多图像的高光去除方法也逐渐发展起来。多图像方法中多曝光图像融合(multi-exposure image fusion,MEF)方法最具代表性,其主要思想是获得同一图像在不同曝光属性下的状态,包括曝光角度、曝光强度等,然后对这些图像进行特征提取,通过原图与特征图的加权结合获得最终的融合图像[3]。相比基于单图像的方法,MEF方法能够获得高光区域中更多的纹理细节,但获得更多信息的代价是降低算法模型的实时性和泛化能力,因为大量固定的参数使其无法在多样化的数据上表现如一,并且传统的多图像方法在处理极端曝光情况下的图像时效果较差。
自2012年以来,深度学习在计算机视觉领域被广泛应用,学者们针对不同问题提出了各种针对性的网络框架,基于这些基础性框架的优化更是层出不穷。在深度学习多曝光图像融合领域,主要分为2类方法:基于无监督的方法和基于有监督的方法。前者属于先聚类再定性,可适应多样化的输入图像,如MEF-Net[4]、DeepFuse[5]、MEF-GAN等[6],模型运行速度较快;后者则是按照已有标签进行分类,一般用于指定图像类型,如ECNN[7]、MFNet等[8],此类模型生成的图像质量较高。
目前已有学者将多曝光图像融合应用于自然图像处理领域并加以优化和改进,均在一定程度上取得了不错的效果。2018年,Peng等[9]基于CNN设计了MergeNet融合网络,此方法将光流配准[10]和深度学习网络相结合,相比之前多位学者提出的基于运动检测的方法,有效地解决了融合图像的重影问题,然而鲁棒性有限。后续Yan等[11]提出了CAHDRNet,一种基于多尺度的上下文注意的图像融合网络,这是一个端到端的网络,由特征提取网络和特征融合网络2个子网络构成,解决了速度慢的问题。在这些研究的基础上,Ma等提出了一种快速多曝光图像融合方法MEF-Net,此方法适用于任意空间分辨率和曝光次数的图像,使用了“下采样-执行-上采样”的方案,中间生成低分辨率权重图,上采样过程中利用了权重图的平滑性,在保证融合图像质量的同时,极大程度上提高了运行速度,在GPU上处理相同图像时,速度比其他深度学习方法快10~100倍。
当前的多曝光图像融合方法主要针对自然曝光图像,很少有在金属曝光图像上的研究,主要几点原因有:一是工业数据集的特殊性,导致金属高光图像的数据集稀少,很难找到专业的金属高光数据集用于研究;二是金属特性的原因,其表面极易产生极端高曝光或者低曝光的情况,难度较大。除此以外,还有一个重要的待解决问题是模型的运行速度,高光去除作为一个图像预处理步骤,不应花费太多的时间。因此,本文以目前速度最优的MEF-Net为基础,引入细节增强模块(detail enhance model, DEM)和色彩增强模块(color enhance model, CEM)[12]提高融合图像质量,并且使用DCGAN[13]生成金属高光图像扩充数据集,一定程度解决金属图像数据集缺少的问题,实现无监督下的金属表面高光去除。
1 算法原理
1.1 MEF-Net模型介绍
MEF-Net是一种端到端的多图像融合方法,它在保证融合图像质量的同时,极大提高了运行速度。MEF-Net利用了一个全卷积网络使得用户可以输入任意数量的图像,为了提高运行速度,对输入图像直接进行线性下采样操作,难以避免会损失一些高频的细节信息。MEF-Net的整个模型是基于MEF结构相似性(MEF-SSIM)[14]指数进行优化的,这是整个模型质量保证。目前大量的实验表明,与多数最新MEF方法相比,MEF-Net融合的图像在视觉感知方面有一定优势,且其运行速度远快于其他方法。
1.2 MEF-Net网络结构
MEF-Net由一个双线性下采样器、一个基于扩张卷积[15]的特征预测网络(context aggregation net, CAN)、一个引导滤波器[16]和一个加权融合模块组成。获取特征的结构如图 1所示。
MEF-Net首先对输入序列进行降采样,并输入CAN网络低分辨率版本用来预测低分辨率权重图。以原图和特征图作为输入,使用引导滤波器获得高分辨率权重图,该操作也称为计算机视觉中的联合上采样。最后,计算特征图与原图的融合图像获得最终图像,如(1)式所示,Wk表示原图像Xk的权重图, Y为最终加权融合获得的无高光图像。
 (1)
(1)
MEF-Net核心模块是一个卷积网络, 它将低分辨率的输入序列转换为相应的权值图。网络需要允许任意空间大小和曝光数, 并产生相应大小和数量的特征图。为此, MEF-Net使用完全卷积网络来处理所有的曝光(即不同曝光的图像共享相同的权重生成网络), 这可以通过batch维度的分配来高效实现。MEF-Net的核心网络有7个卷积层, 其配置如表 1所示, 它的输出与输入具有相同的分辨率。
 |
图1 MEF-Net获取特征结构图 |
CAN网络配置
2 改进的MEF算法
2.1 DCGAN图像生成
本文的方法主要应用在复杂工业环境下的高光金属表面, 当前已有的高光图像数据集均为自然图像。实际加工现场收集到的图像数量很少, 远远达不到深度学习模型训练要求, 若采用现有数据集直接进行训练, 容易导致实验结果出现过拟合情况。传统的数据集扩充方法主要采用旋转、缩放以及添加噪音等方式, 这样的方式不仅繁琐, 而且本身依赖于一定的数据数量[17]。为基于目前有限的数据集获得更多金属高光图像, 本文采用深度卷积生成对抗网络(deep convolutional generative adversarial networks, DCGAN)进行金属高光图像生成。
DCGAN是目前生成对抗网络在实际工程应用中被采用最多的衍生网络, 它是生成对抗网络针对图像生成质量以及稳定性优化而产生的。DCGAN模型由生成网络G与判别网络D组成, 结构如图 2所示, 网络结构均为5层, 生成网络接收一个随机输入的噪声, 通过该噪声生成一张目标图像; 判别网络接收一张图像, 对该图像做出判断后, 计算出一个概率值, 若该图像来源为生成网络, 则输出0, 若该图像来自真实的数据分布, 则输出1。两者根据反馈的结果, 不断更新自己的参数, 直至达到纳什均衡。
生成模型的网络结构一共有5层, 其中采用反卷积代替上采样来获得指定大小的图片。它的主要结构如图 3所示。
网络根据输入的向量信息, 分步获取输入图像的特征信息, 包括边缘、色度等, 随后根据网络的深入, 不断优化图片细节。输入一张图片, 根据需要的特征图大小设置相应的卷积核, 卷积核大小影响了生成网络的可学习空间特征值大小。在除了输出层之外的每一层, 加上批归一化处理, 缓解模型崩溃问题。最后, 输出一个像素的三通道RGB图像。
判别模型的网络结构类似于反向的生成器, 网络同样有5层, 采用下采样方法。整个网络结构没有池化层, 采用LeakyReLU[18]作为激活函数, 通过一个全连接层输出判别结果, 表示输入图像属于真实样本还是由生成器所生成, 其结构如图 4所示。
生成网络和判别网络的输出层激活函数分别为Than函数和Sigmoid函数, 两者都是S型函数, 其函数特性会导致反向传播算法收敛速度降低, 使用BCELoss函数后, 解决了因Sigmoid函数导致的梯度消失问题。
用DCGAN模型生成的部分金属高光图像如图 5a)所示。这些生成的图像带有金属高光的特征, 并且可以通过调节参数和输入来改变生成图像的曝光程度, 如图 5b)所示。这些生成的图像分辨率为256×256, 并且带有一定的噪音点, 可以作为训练集提高模型泛化能力。
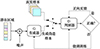 |
图2 生成对抗模型 |
 |
图3 生成器G的网络结构 |
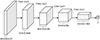 |
图4 判别器D的网络结构 |
 |
图5 DCGAN生成图像结果 |
2.2 引入DEM模块和CEM模块
MEF-Net为了满足速度要求, 使用了下采样-处理-上采样的方法进行特征融合, 其中下采样直接使用了线性下采样(bilinear downsampling), 这样会导致高光区域中高频的纹理信息丢失, 下采样得到的图像序列输入CAN进行低分辨率权重预测。本文在这个过程中引入细节增强模块DEM和色彩增强模块CEM来增强网络的感知能力, 减少因线性下采样导致的细节丢失和颜色失真问题, 并且可以在几乎不影响原来速度的情况下实现。整体感知增强流程如图 6所示, 将色彩空间从RGB转换为YCbCr是很自然的, 因为与RGB色彩空间相比, YCbCr可以有效地将亮度和纹理(Y通道, 亮度分量)与颜色(Cb和Cr通道, 色度分量)分开, 这样细节增强和色彩增强就可以分别在亮度和色度组件上进行。
在细节增强模块中, 给定图像I, 在图像中可以轻松得到全局收益Iα=α×I, α为带曝光调整的比例系数。图像曝光升高时α>1, 降低时α < 1。图像中可能同时存在过度曝光、适度曝光和曝光不足的区域, 通过全局调优α时并不能完全解决所有区域存在的曝光问题, 因此需要找到一个自适应规则。引入一个标准差变量σ, 在半径为r的窗口内, 图像的每个位置为Iij, 这样标准差就可以看作是细节丰富度的衡量标准, 其公式表示为
 (2)
(2)
在α>1的预设集合中逐渐增加其标准差, 将相应得到σijα=α×σij, 到达合适的曝光。对于曝光不足的区域, 上述操作增强其对比度, 但无法处理过度曝光的区域。因此通过反转原图像获得Iinv=1-I, 最初过度曝光的区域看起来就像曝光不足的区域。将完全相同的规则应用于Iinv, 便可获得双向的细节增强。
在色彩增强模块中, 源图像被转换为YCbCr色彩空间, 然后仅在Y(亮度)通道上执行融合策略, 而Cb和Cr(色度)通道的融合规则仍然以直接的形式设计, 如(3)式所示。
 (3)
(3)
式中, C1和C2表示输入图像的Cb和Cr通道, Cf是相应的融合色度通道, τ值一般设定为128。当原图像曝光严重时, 颜色信息会受到干扰甚至破坏, 并且不同照明条件下的颜色也会不一致, 因此CEM中通过获取2个源图像(亮度和色度分量)的全部信息以及目标亮度作为输入来推断最适合融合亮度(由DEM生成)的色度, 如(4)式所示
 (4)
(4)
式中: NCEM表示带有参数的CEM网络; θCEM是需要学习的参数。CEM设置为编码器-解码器联合结构, 每层有4个分支, 以探索输入图像之间的颜色映射关系。
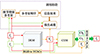 |
图6 感知增强流程 |
2.3 评估损失函数的改进
MEF-SSIM是MEF领域普遍适用的评估函数, 它的构建遵循SSIM(结构相似性)指数[19]的定义, 评价指标主要基于人眼查看图像时提取的结构化信息。SSIM方法是一种全参考的评价方法, 对于图像x和y, 其SSIM定义如(5)式所示。
 (5)
(5)
式中: μx和μy分别表示输入图像的平均强度;σx, σy和σxy表示局部方差和协方差;N1和N2是2个较小的常数, 以防止其不稳定。在本文方法中由于可以输入不同空间分辨率的图像, 而SSIM需要在特定配置下才能表现良好, 在灵活性方面没有较好的结果, 所以采用多尺度结构相似度(multi-scale SSIM, MSSSIM)[20],作为评估函数进行优化替代。
MSSSIM采用了多尺度分块的方法, 对于不同分辨率都能保持性能稳定。将对比图像进行输入后, 依次使用低通滤波器进行1/2下采样。假设原始图像为Scale 1, 最高尺度为Scale M经过M-1次迭代得到。对于第j尺度, 只计算对比度C(x, y)和结构相似度S(x, y)。通过Scale M,计算亮度相似度l(x, y), 最终的MSSSIM是将各个尺度的结果连接起来。
 (6)
(6)
式中,α, β和γ用于调整各分量的权重。图像细节的可感知性取决于图像信号的采样密度、图像平面到观察者的距离以及观察者视觉系统的感知能力。在实验中, 当这些因素发生变化时, 对给定图像的主观评价就会发生变化。因此MSSSIM的评估结果可以更贴近主观质量评估结果。
2.4 改进后的网络结构
本文使用了DCGAN的方法扩充了曝光金属图像的数量, 提升了网络的训练效果; 在CAN网络之前引入DEM和CEM模块, 使低分辨率图像进行特征预测时保留更多的纹理细节和色彩细节; 将评估函数SSIM替换为MSSSIM, 更加注重图像整体的质量, 提高网络的感知能力。整体改进后的多曝光图像融合网络结构如图 7所示。
 |
图7 改进后的网络结构图 |
3 实验方案与结果
3.1 实验环境
本文的生成对抗网络以及多曝光图像融合网络均基于Pytorch深度学习框架而搭建, Python版本为3.9。网络训练采用的计算机操作系统为Windows10, CPU为6核12线程的Intel(R) Core(TM) i5-12400F, 图形处理器(GPU)采用NVIDIA RTX 3070, 显存12 GB。
3.2 实验参数设定
本文在训练中使用了自适应动量估计算法(Adam)作为其求解器, 学习率为0.000 1, 动量参数β1为0.5, Adam中的其他参数是默认情况下设置的。Batch-size等于当前序列中的曝光次数, 即图像数量。epoch设置为200, 前150个epoch保持初始学习率0.001不变, 后50个epoch采取线性衰减方式至0。对于损失权重的权值, 经过多次实验对比后设置λ1为15, λ2为0.5。
作为一个无监督的模型, 本文中实验所用到的数据集均不需要进行标注, 同一图像的不同曝光数据放在相同目录下, 通过Pytorch中的Dataset工具包自动转化成数据流作为训练以及测试的输入。
3.3 评估指标
在图像融合领域, 评估方法分为2类: 一是定性分析, 通过主观的视觉质量来进行对比; 二是定量客观分析。目前在大多数MEF方法中用到的客观评估指标包括多曝光图像融合结构相似度(multi-exposure fusion structural similarity index measure, MEF-SSIM)、信息熵(entropy, EN)、互信息(mutual information, MI)等[21], 详细如表 2所示。
本文方法针对融合金属图像的特征信息和色彩信息进行了优化, 因此主要对应MEF-SSIM、AG以及MI 3个指标进行评估, 用于反映方法对细节和色彩的保留程度。
MEF-SSIM是MEF领域被广泛应用的评估指标, 它基于结构相似性方法原理和补丁结构一致性来计算度量指标, 主要用于MEF结果的感知质量评估。该指标反映了融合图像中保留输入图像局部细节的程度, 其数值越大代表融合结果越好。感知质量评价S与整体结构相似度定义为
 (7)
(7)
 (8)
(8)
式中:σx2, σy2分别代表x, y向量的局部方差;σxy为x与y的局部协方差;M为分割的图像块总数;Q(Y)是最终计算的整体结构相似度指标。
除上述对融合图像质量的评估指标外, 本文引入了计算复杂度(computational complexity, CC)和融合时间(running time, RT), 用于反映模型的规模以及速度。计算复杂度中假设输入通道的数量为K, 每个图像都包含M像素, 用于计算本地统计信息的窗口大小为N2, 若模型只对整张输入图像进行n次处理, 则计算复杂度为nKMN2。融合时间则为在输入相同数量及空间分辨率的曝光图像后, 模型输出图像的运行时间。
图像融合评估指标
3.4 结果对比分析
为了评估本文所改进的MEF-Net模型的高光去除效果,选取了部分带有曲面特征的金属高光图像进行实验,这部分图像与本文实验实际针对对象有相似的一些特征,其中包含字符信息、细小纹理以及大曲面等。将本文方法和原MEF-Net以及当前一些主流MEF方法,包括深度学习MEF-GAN、U2Fusion和传统MGFF方法进行对比。实验结果如图 8~11所示,输入高光图像为4张不同曝光角度的金属高光图像。
从图中可以看出,传统MGFF方法在实际处理金属高光时表现很差,丢失了大量纹理信息,在复杂纹理的融合图像中产生了异常像素,在人脸这类大曲面金属工件上还产生了严重的色彩失真。MEF-GAN方法在金属高光图像中的融合结果不仅在色彩上严重的失真,高光区域还存在特征信息丢失的情况,高光去除效果差。
U2Fusion在融合图像的细节保留上表现良好,但由于其网络特性,只能产生单通道的灰度图,如果使用OpenCV对结果图像进行色彩转换也会出现一定程度失真。相比于原MEF-Net,本文改进后的方法保留了高光区域更多纹理细节的同时,避免了失真,整体高光去除效果优于其他方法,无异常像素产生,一定程度上还原了图像无高光的场景。
表 3中选取了部分评估指数在高光金属数据集下的表现,SSIM、MI和AG参数指数主要反映融合图像与原图像之间信息的关系,时间和CC(计算复杂度)参数用于评估模型的实时性和规模大小。如表中数据所示,MEF-GAN方法在高光金属数据集中的表现普遍较差且模型规模最大,传统MGFF方法速度最快,因为其只对像素做了多尺度的算法运算,融合质量一般。相较于原MEF-Net方法,本文方法在基本不牺牲速度的情况下,整体评估质量提升了10%左右,进一步表明了本文方法在金属高光区域有着较强的细节保留能力。
为探究本文方法在实时性方面所占优势的具体情况,选取了几种主流多曝光图像融合方法在不同分辨率图像下进行速度对比,实验结果如图 12所示。图中横坐标代表不同分辨率,如512s表示512×512大小的图像,纵坐标表示融合所花费的时间,各种方法输入图像数量均为2张。
从图中的数据可以看出,在不同分辨率的图像融合中, 本文当前的方法速度领先于其他主流图像融合高光去除方法,并且MEF-Net得益于其端到端的特性,其在CPU模式下的运行速度也快于其他方法。
综上所述,本文改进后的MEF方法在金属表面的高光去除效果相比于当前的一些主流方法,无论是在视觉上还是指标上都有着一定的优势,说明引入的DEM和CEM模块很好地解决了由于线性下采样所导致的纹理丢失问题,为CAN特征预测网络提供了良好的输入。此外,本文方法在速度上继承了MEF-Net的优势,远远快于其他方法,这对后续的实时性应用提供了很好的基础。
 |
图8 带字符金属高光图像融合结果 |
 |
图9 带复杂纹理金属高光图像融合结果 |
 |
图10 复杂曲面类金属高光图像融合结果 |
 |
图11 人脸曲面类金属高光图像融合结果 |
高光金属数据集中不同方法评估
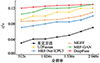 |
图12 主流多曝光图像融合方法速度对比 |
3.5 消融实验
为了验证DPM(DEM和CEM)模块以及多尺度评估损失函数MSSSIM对融合图像质量的影响,本文将网络模型按照不同的组合在金属高光图像上进行了消融对比,分3组对照:第一组为原MEF-Net默认参数下的配置;第二组为引入DPM模块后,使用SSIM为评估函数;第三组为引入DPM模块,并且使用MSSSIM替换SSIM作为评估函数,实验结果如图 13所示。
从图中可以看出,引入DPM模块后高光区域局部亮度更加平和,保留了极端高光区纹理特征。使用MSSSIM评估函数后,高光区域整体更加平滑,图像边缘更加清晰,极大提升高光去除效果的同时,对图像中划痕、细小凹坑等特征信息进行了有效还原。
表 4展示了消融实验各组的客观评估数据,由表中数据可知,DPM模块的引入提高了融合图像的信息保留程度,MSSSIM的使用提升了图像的整体结构相似度。上述实验结果表明,本文改进的MEF方法从特征信息细节和整体结构相似度上进行了优化,能够对金属表面高光去除,获得更高质量的融合图像。
 |
图13 消融实验结果 |
消融实验客观评估比较
4 结论
本文针对金属表面高光问题,提出了一种以MEF-Net为基础,改进细节增强和色彩增强的MEF高光去除方法,使用DCGAN生成对抗的方法扩充了金属高光数据集。在CAN特征提取网络前引入了DEM模块CEM模块,使其能保留高光区域更多的特征信息。最后使用多尺度的MSSSIM评估函数代替单尺度的SSIM损失,提高了融合图像的整体结构相似性。实验结果表明,在金属表面高光数据集上,本文改进的模型相较原MEF-Net模型,图像融合的视觉质量和客观评估指数均有所提升,其中反映图像中信息保留程度的评估指数互信息(MI)和平均梯度(AG)提升了10%左右,并且保留了原模型的高运行速度。对比当前主流的MEF方法在高光去除效果以及速度方面均有明显优势。后续工作是继续优化网络结构,在满足实时性要求的同时,进一步提高图像的细节还原能力。
References
- SHAFER A S. Using color to separate reflection components[J]. Color Research & Application, 1985, 10(4): 210–218 [CrossRef] [Google Scholar]
- ZHU Xinli, ZHANG Yasheng, FANG Yuqiang, et al. Review of multi-exposure image fusion methods[J]. Laser & Optoelectronics Progress, 2023, 60(22): 2200003 (in Chinese) [CrossRef] [Google Scholar]
- FERIS S R, RASKAR R, TAN K, et al. Specular highlights detection and reduction with multi-flash photography[J]. Journal of the Brazilian Computer Society, 2006, 12(1): 35–42. [Article] [CrossRef] [Google Scholar]
- MA K, DUANMU Z, ZHU H, et al. Deep guided learning for fast multi-exposure image fusion[J]. IEEE Trans on Image Processing, 2020, 29(1): 2808–2819 [CrossRef] [Google Scholar]
- PRABHAKAR K R, SRIKAR V S, BABU R V. DeepFuse: a deep unsupervised approach for exposure fusion with extreme exposure image pairs[C]//IEEE International Conference on Computer Vision, 2017: 4724–4732 [Google Scholar]
- XU H, MA J, ZHANG X P. MEF-GAN: multi-exposure image fusion via generative adversarial networks[J]. IEEE Transa on Image Processing, 2020, 29(5): 7203–7216 [CrossRef] [Google Scholar]
- AMIN-NAJI M, AGHAGOLZADEH A, EZOJI M. Ensemble of CNN for multi-focus image fusion[J]. Information Fusion, 2019(51): 201–214 [CrossRef] [Google Scholar]
- XIANG Y, ZULQARNAIN S G, HANLIN Q, et al. Structural similarity loss for learning to fuse multi-focus images[J]. Sensors, 2020, 20(22): 6647–6664 [NASA ADS] [CrossRef] [Google Scholar]
- PENG F, ZHANG M, LAI S, et al. Deep HDR reconstruction of dynamic scenes[C]//IEEE International Conference on Image, Vision and Computing, 2018: 347–351 [Google Scholar]
- ILG E, MAYER N, SAIKIA T, et al. Flownet 2.0: evolution of optical flow estimation with deep networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2462–2470 [Google Scholar]
- YAN Q, GONG D, SHI Q, et al. Attention-guided network for ghost-free high dynamic range imaging[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 1751–1760 [Google Scholar]
- HAN D, LI L, GUO X, et al. Multi-exposure image fusion via deep perceptual enhancement[J]. Information Fusion, 2022, 79: 248–262 [CrossRef] [Google Scholar]
- RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[J/OL]. (2016-01-07)[2023-05-22]. [Article] [Google Scholar]
- MA K, ZENG K, WANG Z. Perceptual quality assessment for multi-exposure image fusion[J]. IEEE Trans on Image Processing, 2015, 24(11): 3345–3356 [NASA ADS] [CrossRef] [Google Scholar]
- FU J, LI W, DU J, et al. DSAGAN: a generative adversarial network based on dual-stream attention mechanism for anatomical and functional image fusion[J]. Information Sciences, 2021, 576: 484–506 [CrossRef] [Google Scholar]
- HE K, SUN J, TANG X. Guided image filtering[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2012, 35(6): 1397–1409 [Google Scholar]
- LUO Lingjie. Research on image highlight removal based on deep learning[D]. Hangzhou: Hangzhou Dianzi University, 2020 (in Chinese) [Google Scholar]
- XU J, LI Z, DU B, et al. Reluplex made more practical: Leaky ReLU[C]//2020 IEEE Symposium on Computers and Communications, 2020: 1–7 [Google Scholar]
- WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Trans on Image Processing, 2004, 13(4): 600–612 [NASA ADS] [CrossRef] [Google Scholar]
- HUANG H, LIN L, TONG R, et al. Unet 3+: a full-scale connected unet for medical image segmentation[C]//2020 IEEE International Conference on Acoustics, Speech and Signal Processing, 2020: 1055–1059 [Google Scholar]
- ZHANG Xiaoli, LI Xiongfei, LI Jun. Validation and correlation analysis of metrics for evaluating performance of image fusion[J]. Acta Automatica Sinica, 2014, 40(2): 306–315 (in Chinese) [Google Scholar]
All Tables
All Figures
|
图1 MEF-Net获取特征结构图 |
| In the text | |
|
图2 生成对抗模型 |
| In the text | |
|
图3 生成器G的网络结构 |
| In the text | |
|
图4 判别器D的网络结构 |
| In the text | |
|
图5 DCGAN生成图像结果 |
| In the text | |
|
图6 感知增强流程 |
| In the text | |
|
图7 改进后的网络结构图 |
| In the text | |
|
图8 带字符金属高光图像融合结果 |
| In the text | |
|
图9 带复杂纹理金属高光图像融合结果 |
| In the text | |
|
图10 复杂曲面类金属高光图像融合结果 |
| In the text | |
|
图11 人脸曲面类金属高光图像融合结果 |
| In the text | |
|
图12 主流多曝光图像融合方法速度对比 |
| In the text | |
|
图13 消融实验结果 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.