| Issue |
JNWPU
Volume 43, Number 3, June 2025
|
|
|---|---|---|
| Page(s) | 620 - 629 | |
| DOI | https://doi.org/10.1051/jnwpu/20254330620 | |
| Published online | 11 August 2025 | |
Graph Huber: a robust regression model for graph data
G-Huber: 一种面向图数据的鲁棒回归模型
1
School of Computer Science and Technology, Taiyuan University of Science and Technology, Taiyuan 030024, China
2
School of Mathematics, Northwestern University, Xi'an 710100, China
Received:
24
January
2024
Abstract
As it is increasingly prevalent that data contains noise or obeys heavy-tailed distribution, a robust regression model becomes one of focal and hot topics in many study fields. However, most existing robust regression models are based on the assumption of sample independence and negligent of the correlation between samples, thus being unable to be effectively used to solve a graph data problem. Therefore, this paper uses graphs to represent the correlation between samples and studies robust regression models oriented to graph data. Specifically, based on the robust Huber regression, the paper proposes a graph Huber regression model, which contains information on the correlation between samples and has a certain robustness. Then it gives an algorithm for solving the regression model. The experimental results show that the performance of the regression model is far superior to that of the graph LASSO, especially when its errors obey heavy-tailed distribution. The paper provides an effective method for analyzing and processing graph data that contains noise or obeys heavy-tailed distribution.
摘要
随着数据中含有噪声或服从重尾分布的现象越来越普遍, 鲁棒回归模型成为了众多研究领域关注和研究的重点内容之一。然而, 现有的鲁棒回归模型大多基于样本独立假设, 忽略了样本之间的相关性, 即并不能有效地用于处理图数据问题。因此, 借助图来表示数据之间的相关性, 展开了面向图数据的鲁棒回归模型研究。具体地, 基于具有鲁棒性的Huber回归, 提出了图Huber回归模型, 所提模型既包含了样本之间的相关性信息, 又具有一定的鲁棒性。在此基础上, 给出了相应的求解算法。实验结果表明所提模型的表现性能远优于图LASSO, 尤其当回归模型误差为重尾分布时。由此说明, 该研究工作为图数据中存在噪声或重尾分布问题提供了一种有效的分析和处理方法。
Key words: robustness / regression model / graph data / graph Huber / heavy-tailed distribution
关键字 : 鲁棒性 / 回归模型 / 图数据 / Huber损失 / 重尾分布
© 2025 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
科学技术的飞速发展使得数据的生成、传输和获取变得尤为便利。丰富的数据资源蕴含着巨大的知识信息, 如何有效地挖掘数据的本质信息, 探索其隐含知识和规律并将其应用于实际生活中, 是当前人工智能、数据科学、统计机器学习等多个学科重要的研究问题之一。作为人工智能的核心技术, 机器学习能够有效地挖掘和探索已知数据的内在规律和模式, 并应用于未知数据的预测、分类、聚类等问题[1]。回归模型作为机器学习中一类重要的基础模型, 被广泛应用于众多领域中。类似于其他机器学习模型, 优质的数据是回归模型建模的重要基础。然而, 不可避免地, 数据中往往会含有噪声或服从重尾分布。国际知名科技咨询公司Gartner的调查报告显示, 全球财富1 000强的企业中, 超过25%的企业信息系统中存在数据不准确问题; 美国医疗系统中有至少10%以上的关键数据存在缺失[2]。另一方面, 在实际应用和生活中, 很多数据会呈现重尾分布的特点[3]。基于上述问题, 鲁棒回归模型引起了众多学者的广泛关注。
鲁棒回归模型的主要任务是构建具有鲁棒性的回归参数估计模型, 减少异常点或噪声对回归模型的影响, 从而提高回归模型的表现性能。经典地, 通常假设模型误差服从高斯分布, 基于此, 最小二乘估计以及基于平方损失的多种正则化方法得到了广泛的研究和应用[4]。然而, 一方面, 高斯分布并不能很好地表示含有噪声或异常点的数据分布; 另一方面由于平方损失函数的敏感性使得上述方法缺乏一定的鲁棒性。因此, 考虑回归模型噪声的鲁棒建模方法得到了广泛关注。例如基于Laplace误差分布下的最小一乘(LAD)估计以及基于绝对值损失的各种正则化方法[5]; 基于重尾误差分布的分位数回归(QR)及相应的正则化方法[6]; 基于重尾和非对称模型误差的Huber回归[7]等。
近年来, 鲁棒回归模型已经取得了众多的研究成果, 且得到了广泛应用。然而, 现有的鲁棒回归模型大多基于样本独立假设, 忽略了样本之间的相关性。与此同时, 图数据已经广泛存在于生活中的方方面面, 如生物制药、智能交通、电子商务以及疫情防控等。不同于传统的数据样本特点, 图数据能够更加有效地刻画数据之间的相关性, 进而为回归模型对未知数据的预测提供更为全面和准确的信息。
目前关于图数据的回归模型, Su等分别研究了Network LASSO[8]和Network Elastic Net[9]估计模型, 但这2种模型均是基于平方损失的, 故而缺乏一定的鲁棒性。鉴于上述情况, 本文针对样本之间的相关性问题, 面向图数据, 展开了鲁棒回归模型的研究和探索, 提出了一种新的鲁棒回归模型。具体地, 在对每个样本进行回归模型构建过程中, 考虑了与每个样本相关联的样本信息; 在此基础上, 基于Huber损失, 提出了包含样本关联信息, 且具有鲁棒性的正则化方法。所提模型不仅充分考虑了样本之间的关联性, 而且有效地缓解了已有模型的敏感性问题, 即当回归模型误差服从重尾分布时, 该方法仍能够给出较为准确的回归参数估计值, 从而减小异常点或噪声对回归模型预测的影响, 进而保证回归模型对未知数据预测的准确度。
1 相关工作
1.1 基于l2损失的回归模型
作为机器学习的基础模型, 回归模型能直观地刻画出数据中输入与输出之间的关系, 而且具有较好的可解释性。通常, 线性回归模型具有如下形式
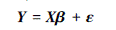
式中:Y = (y1,y2,…,yn) ∈ Rn 为n维输出向量; X=(X1T, X2T, …, XpT)∈Rn×p是由输入变量构成的设计矩阵; β=(β1, β2, …, βp)T是p维待估回归参数向量; ε=(ε1, ε2, …, εn)T是模型误差向量。回归模型的根本任务为估计回归参数β。
经典的回归参数估计方法是最小二乘估计, 其基本思想是通过最小化均方误差(l2损失)得到回归模型参数值。然而, 由于对设计矩阵的严格要求, 使得该方法在很多实际场景中并不适用。1996年, Tibshirani[10]提出的LASSO(least absolute shrinkage and selection operator)回归为解决这一问题提供了新思路。LASSO回归的基本思想是压缩一部分回归系数, 使剩余平方和最小。具体来说, LASSO回归使回归系数的绝对值之和小于某一个常数, 通过将一些回归系数设置为0, 使得回归模型稀疏化, 从而降低模型的复杂度。其模型为
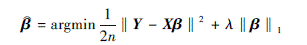
式中等号右边第一项为l2损失函数项, 第二项为l1正则项, λ为大于0的正则化参数。LASSO回归通过对回归参数施加一定的约束, 使得一部分参数尽可能趋于0, 从而实现了特征选择。因此, 自提出后, LASSO回归便得到了广泛研究和应用。在此基础上, 各种不同的正则化项被提出, 如l1/2[11]、Adaptive LASSO[12]、Elastic Net[13]等。
上述基于l2损失的各种正则化方法均具有特征选择的能力, 因而被广泛地应用于多个领域, 如矩阵分解、多标签学习、多目标学习等。然而, 由于平方损失的敏感性, 上述方法缺乏一定的鲁棒性, 无法有效地用来处理含有噪声或重尾分布数据。基于此, 众多学者展开了对鲁棒回归模型的研究与探索。
1.2 鲁棒回归模型
近年来, 随着数据中含有噪声的情况越来越普遍, 鲁棒回归方法越来越受众多领域的关注。常见的鲁棒方法可以分为两大类: ①以数据为中心, 主要思想为对数据进行预处理, 从中选出可信度较高的样本; ②以模型为中心, 构建具有鲁棒性的回归模型。目前, 构建具有鲁棒性的回归模型主要包括如下3种: ①基于加权的方法, 构建加权损失函数, 一方面通过赋予较小损失较大的权值, 提高这类样本对回归参数估计的影响; 另一方面通过赋予较大损失较小的权重值, 减小该类样本对参数估计的影响, 如加权l2损失[14];②基于截断的方法, 其基本思想是通过设置一定的阈值, 将损失太大的样本剔除出去, 如截断最小二乘回归;③构建具有鲁棒性的损失函数, 该类损失函数能够自动调整每个样本的损失值, 对于噪声点, 该类损失能够使其误差值达到最小, 如LAD损失、Huber损失、分位数回归等[15]。
整体而言, 上述方法均是通过减小异常点的损失值来减弱该样本对模型的影响。已有的鲁棒回归模型因具有良好的鲁棒性, 而被广泛应用于聚类分析、人脸识别等多种机器学习任务中。然而, 正如前文所述, 已有的鲁棒回归模型大多基于样本独立假设, 忽略了样本之间的相关性, 并不能有效地用于处理图数据问题。因此本文面向图数据, 展开了鲁棒回归方法的研究与探索。
2 基于Huber损失的鲁棒回归模型
2.1 G-Huber模型构建
给定数据集D={(xi, yi)}i=1n, 假设给定的n个样本通过图G=〈V, E〉连接, 其中V={1, 2, …, n}为图中顶点的集合, 代表n个样本点; E⊂V × V为边的集合, 每一条边代表点与点之间的连接, 即相对应的2个样本之间具有关联性。基于上述讨论, 本文考虑如下回归模型:
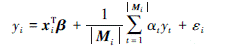
式中,i=1, 2, …, n; j=1, 2, …, n;xi代表第i个预测变量; yi代表第i个响应变量; εi为回归模型误差; β∈Rp为对应的p维待估回归参数; yt(t∈Mi)表示与yi相关联的响应变量; αt为相应的影响系数; Mi表示与yi相关联的响应变量yt构成的集合, 即Mi={t|(yi, yt) ∈E}。
为了便于理解和计算, 本文假设第i个响应变量yi的所有相关变量yt对其有相同的影响, 并令其为α, 即αi=αt=α。从而有
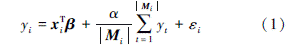
传统地, 通常考虑模型误差εi为高斯分布, 基于此, 构建如下模型
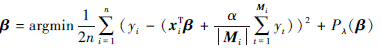
式中等号右边第一项为平方(即l2)损失函数项, 第二项是关于回归模型参数β的正则化项。具体地
1) 若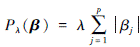 , 上述模型即为Network LASSO(图LASSO);
, 上述模型即为Network LASSO(图LASSO);
2) 若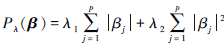 , 上述模型即为Network Elastic Net(图Elastic Net)。
, 上述模型即为Network Elastic Net(图Elastic Net)。
然而正如前文所述, 一方面高斯分布并不能很好地拟合含有异常点的数据分布; 另一方面l2的敏感性使得上述方面缺乏一定的鲁棒性。因此,本文考虑模型误差εi为重尾分布的情况, 提出如下鲁棒回归模型
式中等号右边第一项为Huber损失函数项, 其表达形式为
式中:u表示任意一个变量; η为给定阈值, 确定了二次损失转换为一次损失的位置, 控制着鲁棒性大小, 对异常点的敏感度不高, 具有一定的鲁棒性。可以看出, 当|u|≤η时, Huber函数是二次损失函数, 类似于最小二乘估计, 对大残差比较敏感; 当|u|>η时, ϕHuber(u)是线性增长, 类似于绝对值损失, 对小残差有较好的灵敏度。显然, Huber损失充分结合了平方损失和绝对值损失的优点, 使得所提模型兼具最小二乘和最小一乘估计的优势, 在保证回归模型效果的前提下, 对异常点有较强鲁棒性。(2)式中第二项为l1正则项, 具有特征选择的能力, 可有效提高回归模型的可解释性。λ>0代表正则化参数, 控制模型复杂度, λ越大, 模型越稀疏, 复杂性越低; 反之, λ越小, 对回归参数β惩罚越小, 模型越复杂。
综上所述, 所提模型(2)既具有特征选择的能力, 又具有一定鲁棒性, 即当数据中含有异常的或回归模型误差为重尾分布时, 模型(2)仍能够较为准确地给出回归模型参数β的估计值, 从而减弱异常值对回归模型(1)预测能力的影响。本文将所提模型(2)称为面向图数据的鲁棒回归模型, 简记为G-Huber模型。
2.2 G-Huber求解算法
参考文献[8], 本文给出G-Huber模型的求解算法。目标函数为
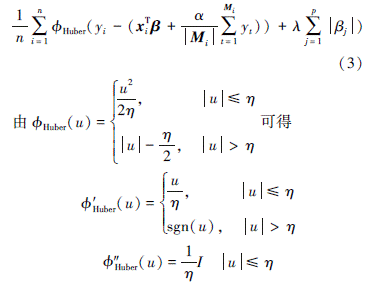
根据KKT条件, 对于任意一个βj(j=1, 2, …, p)有
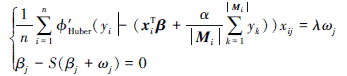
式中,Wj ∈ ∂ |βj|,∂ |· |表示绝对值函数的在βj处的次梯度。\begin{document}$S(z)=\operatorname{sgn}(z)(|z|-1)_{+}= \begin{cases}z, & |z| \geqslant 1 \\ 0, & |z|<1\end{cases}$\end{document}, z表示任意一个变量。从而有
1) 若|βj+ωj|≥1, 则有
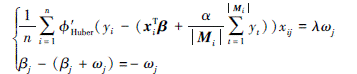
分别对βj和ωj求二次导可得
![Mathematical equation: \begin{document} $ \left[\begin{array}{cc} \frac{1}{n} \sum\limits_{i=1}^n \phi_{\text {Huber }}^{\prime \prime}\left(y_i-\left(\boldsymbol{x}_i^{\mathrm{T}} \boldsymbol{\beta}+\frac{\alpha}{\left|\boldsymbol{M}_i\right|} \sum\limits_{t=1}^{\left|\boldsymbol{M}_i\right|} y_t\right)\right) x_{i j}^2 & \lambda \\ 0 & -1 \end{array}\right] $ \end{document}](/articles/jnwpu/full_html/2025/03/jnwpu2025433p620/jnwpu2025433p620-eq14.gif)
从而
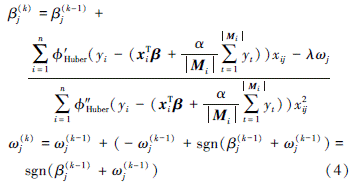
2) 若|βj+ωj| < 1, 则
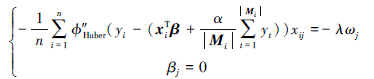
求导可得
![Mathematical equation: \begin{document} $ \left[\begin{array}{cc} \frac{1}{n} \sum\limits_{i=1}^n \phi_{\text {Huber }}^{\prime \prime}\left(y_i-\left(\boldsymbol{x}_i^{\mathrm{T}} \boldsymbol{\beta}+\frac{\alpha}{\left|\boldsymbol{M}_i\right|} \sum\limits_{t=1}^{\left|\boldsymbol{M}_i\right|} y_t\right)\right) x_{i j}^2 & \lambda \\ 1 & 0 \end{array}\right] $ \end{document}](/articles/jnwpu/full_html/2025/03/jnwpu2025433p620/jnwpu2025433p620-eq17.gif)
所以有
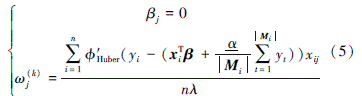
根据上述推导可得如下算法
算法1 G-Huber模型求解算法
输入: 数据D={(xi, yi)}i=1n, 阈值参数η, 正则化参数λ, 迭代次数Iter。
输出: 回归模型参数β
Begin
1) 初始化模型参数β(0);
2) For k=0 to Iter-1 do
(1) 若|βj+ωj|≥1, 则
根据(4)式更新每一个βj;
(2) 若|βj+ωj| < 1, 则
根据(5)式更新每一个βj。
3) End for.
End
3 实验设计与分析
本节通过模拟数据集上的实验来验证所提模型G-Huber的有效性, 并与已有的面向图数据的回归模型G-LASSO[8, 16-17], 以及具有一定鲁棒性的Huber回归进行比较。其原因在于LASSO是一种经典的回归模型参数估计和特征选择方法, 同时面向图数据的G-LASSO受到了广泛的关注; Huber回归是一种经典的鲁棒回归模型, 但传统的Huber回归并未考虑输出变量之间的相关性问题, 即已有的基于Huber回归的方法都是基于数据独立假设的, 因此, 为了更好地验证图结构信息的有效性, 本文将上述2种方法作为对比方法。
此外, 为了更加全面地判断图结构对模型的影响, 本文分别基于Scale-Free(SF)和Erdös-Renyi(ER)2种网络生成图数据。
3.1 数据及评价指标
假定数据个数n=200, 特征维数p=50, 100, 200;预测变量Xi(i=1, 2, …, n)服从正态分布Np(0, Σ), 其中Σ=(σij), σij=0.5|i-j|; 回归参数\begin{document}$\boldsymbol{\beta}_0=(0.5, 1.0, 0.8, 0.2, 0.3, \underbrace{0.5, \cdots, 0.5}_{20}, \underbrace{0, \cdots, 0}_{p-25})$\end{document}基于此, 输出变量yi通过模型(1)生成。任意选取α=2, 模型误差εi分别考虑如下几种情况:
1) 标准柯西分布Cauchy(0, 1);
2) 自由度为1的学生分布t(1)。
定义评价指标为:
1) \begin{document}$\text { MSE: }\left\|\hat{\boldsymbol{\beta}}-\boldsymbol{\beta}_0\right\|_2$\end{document};
2) 特征选择个数N: N=#{j: βj≠0}。
其中评价指标1)用来衡量模型的预测能力, MSE值越小, 说明模型精度越高, 对参数的估计越准确, 性能越好; 评价指标2)指模型所选的特征个数, 表示模型的稀疏性, 用来反映回归模型的可解释性, 其中符号“#”代表集合中元素的个数, 其值越小, 说明模型越稀疏。
3.2 柯西分布Cauchy(0, 1)
本小节研究了模型误差为柯西分布时, G-LASSO, Huber回归以及G-Huber 3种方法在SF和ER 2种网络图结构下, 参数估计的准确度和特征选择两方面的性能比较, 实验结果如表 1~2所示。
表 1显示, 当特征维数固定时, 在SF和ER 2种网络结构图下, 本文所提方法G-Huber均取得了最小的估计误差值, 即对未知参数的估计准确度最高。对于SF网络, 相比于G-LASSO模型, 本文所提模型的估计误差值在不同特征维度下分别降低了近18%, 31%, 6%;对于ER网络, 当p=100时, G-Huber模型比G-LASSO的估计误差值降低了98%左右。此外, Huber回归表现稍弱于G-Huber, 但远远优于G-LASSO, 尤其维数为100时。由此可得, 当模型误差为柯西分布时, 本文所提模型G-Huber在参数预估方面具有远远优于G-LASSO的表现性能。
表 2给出了3种模型分别在不同网络结构和不同特征维度下的特征选择结果。从表 2中可以看出, 对于SF网络, G-Huber和G-LASSO 2种模型在维数为50时所选特征个数几乎相同, 略高于Huber回归所选特征数。当维数为100和200时, G-LASSO所选特征个数最多, G-Huber和Huber回归具有相近的表现。对于ER网络, 当p=200时, G-Huber稀疏性最强; 当p=100和50时, Huber回归所选特征个数最多, G-Huber次之, G-LASSO表现最稀疏。
结合表 1~2可知, 当模型误差为柯西分布时, 本文所提模型在参数估计精度方面具有最好的表现性能; 在特征选择方面, 其特征选择个数会随着特征维数的变化而有所变化。整体而言, G-Huber均取得了较好的实验结果。由此可得, 本文所提模型能够有效分析处理柯西分布或含有异常点的数据。
柯西分布Cauchy(0, 1)下各种方法的MSE值比较(n=200)
柯西分布Cauchy(0, 1)下各种方法的特征选择比较(n=200)
3.3 学生分布t(1)
本小节考虑模型误差为学生t分布时, 3种模型的表现性能。
表 3给出了3种模型在重尾t分布下对模型参数估计的均方误差值。显然, 在2种网络结构下, 本文所提模型G-Huber都取得了最小的误差值, 尤其当维数为200时。另一方面, 当p=50时, 在ER网络下, 相比于G-LASSO的均方误差值为1.703 9, G-Huber的误差值降低近1.62;当网络结构为SF时, 2种模型具有类似的表现结果。而Huber回归的误差值略高于G-Huber模型, 远低于G-LASSO。由此可见, 对于重尾分布数据, G-Huber表现最好, Huber回归次之, G-LASSO最差。
表 4给出了G-LASSO、Huber回归及G-Huber 3种模型的特征选择结果, 从中可以看出, 3种模型在维数为50和100时, 所选特征个数相差较近; 当维数为200时, G-LASSO所选特征个数最多, Huber回归次之, G-Huber所选特征个数最少。
综上所述, 当模型误差为重尾柯西分布或学生分布时, G-Huber均取得了最小的均方误差值, 同时在特征选择方面也具有一定的优势。由此可见, 当数据中含有异常点或服从重尾分布时, 相比于基于平方损失的G-LASSO模型, 本文所提模型具有明显的优势, 由此说明该模型具有一定的鲁棒性, 能够有效地处理含有异常点或服从重尾分布的数据; 相比于具有鲁棒性的Huber回归, 该模型的性能有一定提升, 由此说明在构建回归模型时, 考虑样本之间的图结构(或相关性)信息十分必要。
学生分布t(1)下各种方法的MSE值比较(n=200)
学生分布t(1)下各种方法的特征选择比较(n=200)
4 实际数据分析
本节将所提模型运用于房屋价格数据预测以验证所提模型的有效性。该数据来源于R语言中的igraph包, 主要记录了某地区一周内的房屋交易信息, 共包括纬度、经度、卧室个数、浴室个数、房屋面积以及销售价格等信息的985个交易数据。
实验过程中, 将房屋销售价格记为输出y, 剩余信息为输入特征X。首先将数据进行标准化处理, 使其均值为0, 方差为1。其次, 随机选取200个交易数据作为测试集, 剩余部分作为训练集。进一步, 分别以每所房子的经度和纬度为坐标构建训练集和测试集上的网络结构图, 且对于任一样本, 其相邻个数g分别考虑3, 10或所有这3种情况, 即g=3, 10, all。对于影响系数α, 本文选用与2所房屋之间距离的倒数值进行连接, 即
式中:αij表示与第i个样本相邻的第j个样本对其影响系数; xi1和xj1分别表示第i个样本和第j个样本的横坐标; xi2和xj2分别表示第i个样本和第j个样本的纵坐标。显然, 如果数据j在数据i的最近邻集合中, 则无论i是否在j的最近邻集合中, 二者之间都存在一条无向边。对于评价指标, 本实验采用样本内预测误差(in-sample prediction errors)和样本外预测误差(out-sample prediction errors)。此外, 在原始数据集上加入柯西噪声进一步验证模型的鲁棒性; 最后考虑权重对模型的影响。具体研究如下。
4.1 柯西噪声
为进一步验证所提模型的鲁棒性, 本小节在原始数据基础上加入了柯西噪声, 实验结果如图 1~3所示。
 |
图1 g=3时3种方法在柯西噪声下的实验结果比较 |
 |
图2 g=10时3种方法在柯西噪声下的实验结果比较 |
 |
图3 g=all时3种方法在柯西噪声下的实验结果比较 |
图 1给出了邻近样本个数为3时, G-LASSO、Huber回归, 以及G-Huber在柯西噪声下的实验结果。显然, G-Huber取得了最小的预测误差值, G-LASSO次之, 未考虑邻近样本信息的Huber回归表现最差。随着正则化参数的增大, Huber回归的预测误差值先增大, 之后保持不变; 而考虑样本邻近信息的G-LASSO和G-Huber基本保持不变, 由此可见, Huber回归对于正则化参数选择相对较为敏感。
图 2给出了邻近样本个数为10时, 3种方法在柯西噪声下的实验结果。对于样本内预测误差值, G-Huber取得了最小误差值0.000 7, 而Huber回归的预测误差值接近于0.001;对于样本外预测误差值, G-Huber的预测误差值为0.004, G-LASSO所得结果接近于0.004 5, 而Huber回归的预测误差值接近于0.007。显然, 本文所提方法表现远远优于其余2种方法。
图 3考虑了邻近样本为所有样本的情况。对于样本内预测误差, 当正则化参数λ取值很小时, G-LASSO表现较好, 随着λ的不断增大, 其预测误差值不断增大趋于稳定, 且高于G-Huber。对于样本外预测误差值, 有类似的表现结果。整体而言, G-Huber表现最好, G-LASSO次之, Huber回归表现最差。综上可知当数据中加入柯西噪声时, 本文所提模型表现最好, G-LASSO次之, 未考虑样本邻近信息的Huber回归表现最差。由此可见, 考虑样本邻近信息能够有效提高模型的性能, 尤其当数据中含有噪声或服从柯西分布时, 本文所提模型远远优于G-LASSO, 即本文所提模型具有一定的鲁棒性。
4.2 权重对模型的影响
本文分别以经度和纬度为横纵坐标构建了网络结构图, 在此基础上, 将样本之间距离的倒数作为邻近样本影响系数值。本小节将考虑不同权重的横纵坐标影响情况, 具体为
式中,ω∈(0, 1)表示权重, 其值越大, 表示横坐标对系数产生的影响越小; 反之亦然。为更好地分析权重对模型的影响, 本文分别考虑了ω=0.01, 0.1, 0.9这3种情况, 并对邻近样本个数g为3的情况进行了详细的实验分析。
由图 4可以看出, 在不同的权值下, 本文所提方法均具有最好的表现性能。当权值ω取值较小时, G-Huber与G-LASSO预测误差值相差最大; 当ω=0.1, 0.9时, G-LASSO和G-Huber样本内预测误差值略有减小。此外, 随着权值的增大, Huber回归的样本内预测误差值基本保持不变; G-LASSO和G-Huber的样本内预测误差值均有所下降。
 |
图4 g=3时不同权重下的样本内预测误差值 |
由图 5可知, 当权重ω取值较小或较大时, G-LASSO和G-Huber预测误差值均较大; 当ω=0.1时, 二者之间的预测误差值略有减小; ω=0.1时, G-LASSO的样本外预测误差值最大; 当ω=0.1时, G-Huber的样本外预测误差值最大0.000 4。整体而言, 对于样本内预测误差值, 权重影响相对比较小; 对于样本外预测误差, 权重取值的大小会对模型的性能产生一定的影响。因此, 在构建网络结构图时, 如何选择恰当或自适应地选择权重仍是一个需要探讨的问题。
 |
图5 g=3时不同权重下的样本外预测误差值 |
5 结论
本文基于具有鲁棒性的Huber损失, 提出了G-Huber模型。从数据的角度出发, 考虑了广泛存在于各个领域的图数据; 从模型的角度出发, 以回归模型为基础, 在模型构建过程中加入了邻近相关样本信息。在此基础上, 为缓解噪声或重尾分布所引起的模型性能下降问题, 本文提出了具有鲁棒性的G-Huber模型。结果表明, 当回归模型误差为重尾分布时, G-Huber模型在参数估计准确度和特征选择方面均远优于G-LASSO。
本文所提模型为含噪声或异常点的图数据提供了一种有效的分析方法。然而, 如何利用样本特征信息构建更为丰富全面的网络图, 以及如何利用数据特征之间的相似性或差异性自适应地求解影响系数仍然是需要进一步研究的重要问题。
References
- ZHOU Zhihua. Machine learning[M]. Beijing: Tsinghua University Press, 2016 (in Chinese) [Google Scholar]
- HU Qinghua, WANG Yun. A review of robust regression modeling approaches with noise[J]. Journal of Northwest University, 2019, 49(4): 496–507 (in Chinese) [Google Scholar]
- FAN J Q, WANG W C, ZHU Z W. A shrinkage principle for heavy-tailed data: high-dimensional robust low-rank matrix recovery[J]. Annals of Statistics, 2021, 49(3): 1239–1266 [Google Scholar]
- GUO W, WANG Z, DU W L. Robust semi-supervised multi-view graph learning with sharable and individual structure[J]. Pattern Recognition, 2023, 140: 109565 [Google Scholar]
- WANG H S, LI G D, JIANG G H. Robust regression shrinkage and consistent variable selection through the LAD-LASSO[J]. Journal of Business and CMD Economie, 2007, 25(3): 347–355 [Google Scholar]
- KONERKER R. Quantile regression[M]. Cambridge: Cambridge University Press, 2005 [Google Scholar]
- YI C R, HUANG J. Semismooth newton coordinate descent algorithm for elastic net penalized Huber loss regression and quantile regression[J]. Journal of Computational and Graphical Statistics, 2017, 26(3): 547–557 [Google Scholar]
- SU M H, WANG W J. A network LASSO model for regression[J]. Communications in Statistics-Theory and Methods, 2023, 52(6): 1702–1727 [Google Scholar]
- SU Meihong. Elastic net regression for network data[J]. Journal of Shanxi University, 2023, 46(3): 604–616 (in Chinese) [Google Scholar]
- TIBSHITANI R. Regression shrinkage and selection via the LASSO[J]. Journal of the Royal Statistical Society, Series B, 1996, 58(1): 267–288 [Google Scholar]
- XU Z B, ZHANG H, WANG Y, et al. L1/2 regularization[J]. Science China Information Science, 2010, 53(6): 1159–1169 [Google Scholar]
- ZOU H. The adaptive LASSO and its oracle properties[J]. Journal of the American Statistical Association, 2006, 101(476): 1418–1429 [CrossRef] [Google Scholar]
- ZOU H, HASTIE T. Regularization and variable selection via the elastic net[J]. Journal of the Royal Statistical Society, 2005, 67(2): 301–320 [CrossRef] [Google Scholar]
- MIN W W, XU T S, DING C. Weighted sparse partial least squares for joint sample and feature selection[J]. IEEE Trans on Knowledge and Data Engineering, 2023: 1–12 [Google Scholar]
- SUN Q, ZHOU W X, FAN J Q. Adaptive Huber regression[J]. Journal of the American Statistical Association, 2020, 115(529): 254–265 [Google Scholar]
- HAVID H, LESKOVEC J, BOYD S. Network LASSO: Clustering and optimization in large graphs[C]//Proceeding of the 21th ACM SIGKDD International Conference on Knowledge Discovering and Data Mining, 2015 [Google Scholar]
- ZHU Q Y, QIN A K, ABEYSEKARA P, et al. Decentralised traffic incident detection via network LASSO[J/OL](2024-02-28)[2024-04-10]. [Article] [Google Scholar]
All Tables
All Figures
|
图1 g=3时3种方法在柯西噪声下的实验结果比较 |
| In the text | |
|
图2 g=10时3种方法在柯西噪声下的实验结果比较 |
| In the text | |
|
图3 g=all时3种方法在柯西噪声下的实验结果比较 |
| In the text | |
|
图4 g=3时不同权重下的样本内预测误差值 |
| In the text | |
|
图5 g=3时不同权重下的样本外预测误差值 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.