| Issue |
JNWPU
Volume 42, Number 5, October 2024
|
|
|---|---|---|
| Page(s) | 959 - 968 | |
| DOI | https://doi.org/10.1051/jnwpu/20244250959 | |
| Published online | 06 December 2024 | |
Supervised pyramid network based on semantic consistency for object detection
基于语义一致性监督金字塔网络的目标检测方法
School of Electronic Engineering, Xidian University, Xi'an 710071, China
Received:
25
September
2023
Abstract
Feature pyramid network is widely used in image understanding tasks based on multi-scale feature learning. The latest multi-scale feature learning focuses on the interactive integration of features in semantic features and detail features. Feature pyramid network complements multi-scale information semantic features and detail features through feature interpolation and summation of adjacent layers. Due to the existence of nonlinear operation and convolution layers with different output dimensions, the relationship among different levels is much more complex, and pixel by pixel summation is suboptimal method. A supervised feature pyramid network based on semantic consistency for object detection is proposed. The present method is composed of asymmetric convolution lateral connection and multi-scale semantic features augmentation. The asymmetric convolution lateral connection improves the generalization of features to various pose objects by learning the feature maps of different receptive fields. The multi-scale semantic features augmentation network improves the detail expression ability of high-level features by supplementing the low-level information for the high-level feature map. Moreover, the present method can provide a better trade-off between accuracy and detection performance. Experiments conduct on the MSCOCO dataset, and the results show that the proposed object detection method's accuracy is improved by 2.6% without increasing extra FLOPs.
摘要
特征金字塔广泛应用于基于多尺度特征学习的图像理解任务中, 最新多尺度特征学习侧重于特征在语义特征和细节特征的交互融合, 特征金字塔通过相邻层特征插值和求和来补充多尺度信息语义特征和细节特征, 由于非线性运算的存在和不同输出维数的卷积层, 不同能级之间关系复杂, 逐像素求和并不是最有效的方法。因此, 提出了基于语义一致性监督金字塔网络的目标检测方法。该网络模型由多语义特征增强模块和非对称卷积侧接模块组成, 其中非对称卷积侧接模块通过学习不同感受野的特征图, 提升特征对各种姿态目标泛化性, 多语义特征增强模块通过为高层特征图补全底层信息, 提升高层特征的细节表达能力, 同时在准确性和检测性能之间实现更好的权衡。在基准测试集MSCOCO上进行的实验结果表明, 所提出的目标检测方法在不增加FLOPs的基础上, 将检测平均精确度提高了2.6%, 显著提高了目标检测的性能。
Key words: object detection / semantic consistency / feature pyramid network
关键字 : 目标检测 / 语义一致性 / 特征金字塔网络
© 2024 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
目标检测是人工智能和计算机视觉的核心基础问题之一, 其任务是找出图像或视频中所有感兴趣的目标, 并确定它们的位置和大小, 如人脸检测[1–2]、行人检测[3–4]、车辆检测[5]等。目前, 目标检测技术在安全、医疗、工业制造等领域均得到广泛的应用[6–8]。为了获得满意的目标检测效果, 如何设计一个高效、切合应用场景的算法成为一个广泛而基本的问题。
传统的目标检测方法采用滑动窗口方式产生目标候选区域, 再利用手工设计的算子进行特征提取, 最后对每一个图像的类别训练一个二分类器, 将每个候选区域特征传递给分类器进行分类判断得出结果[9]。对于单一特定的目标检测, 由于人工设计的滤波器与目标边缘契合明显, 所以这些场景下图像检测精度提升较大, 例如Viola-Jones检测算法提取Haar特征并利用Adaboost分类器进行人脸检测[10–11]; 行人检测算法则利用方向梯度直方图(histogram of oriented gradient, HOG)进行特征提取, 并使用支持向量机(support vector machines, SVM)进行分类[12]; 姿态检测算法利用可形变部件模型(deformable part model, DPM)进行姿态检测、估计与行为分类[13]。但是在复杂场景下, 这些传统方法难以准确匹配目标, 鲁棒性较差。
随着计算设备的快速发展, 依赖大规模计算的神经网络和深度学习也得到迅猛发展, 基于深度学习的目标检测成为了计算机视觉领域的研究热点之一。神经网络通过学习大量的标注训练数据特征提升模型对特征的识别能力; 深度卷积网络可通过学习并融合图像中目标的浅层定位信息与深层语义信息来增强对图像感兴趣区域的激活值, 进而识别目标的显著特征, 提升图像中目标检测性能。基于目标检测算法的设计模式可以分为两阶段方法和单阶段方法。前者将目标分类与回归分开, 形成目标检测的2个阶段, 包括RCNN[14]、SPPNet[15]、Fast RCNN[16]、Faster RCNN[17]等, 相较于传统方法, 非常有效地提升了检测精度。后者则将目标分类和回归合并为一个步骤, 包括YOLO系列[18–21]、SSD[22]、DSSD[23]、RetinaNet[24]、FCOS[25]等, 在保证较高精度的同时提升了目标检测速度。此外, 还有基于Transformer的目标检测算法, 如DETR[26]等, 较前面的方法在精度和速度上都有所提升。在基于深度卷积神经网络的目标检测算法中, 如何设计合理有效的多尺度特征融合模块是其最核心的问题。因为多尺度特征决定对网络图像中不同尺度目标进行定位与辨识, 只有将这些不同尺度的特征合理融合, 得到高语义细粒度特征, 才能实现多尺度精准检测的目的。
特征图像金字塔结构模型[27]首次在图像特征提取过程中引入金字塔结构, 通过使用不同尺度的图像进行特征提取, 有效提升了目标检测的精度, 因此被广泛应用于各类传统检测方法中。但是由于运算量要求过大, 之后各类目标检测模型则采用单尺度特征图预测[15–17], 通过特征提取网络得到最终的特征图进行目标预测。特征图虽然有充足的语义特征, 但是空间特征损失较大, 因此SSD(single shot multibox detector)模型提出金字塔层级特征预测网络[22], 使用不同层级的特征图进行预测, 将后续多级多尺度的特征图分别进行了目标分类和回归, 使得检测准确率有了较大提升。不过由于其是对特征提取网络提取之后的特征图直接进行多尺度化, 在这个过程中没有使用特征提取网络的低层特征图, 因此其可以将高层语义特征分析得很好, 但缺少了空间的细节特征。2017年, Lin等人提出了基于多尺度融合的特征图金字塔网络(feature pyramid networks, FPN)[28]。首先将骨干网络提取的多尺度特征直接融合得到单一尺度特征, 然后对该特征进行不同尺度的采样分离出相同的特征图, 最后将高语义分类特征用于增强底层定位特征, 使底层特征同样具有高语义分析信息, 从而高效地完成了多尺度特征图的融合, 提高了目标检测的精度。基于该特征图金字塔网络, 人们又提出了诸多改进模型, 包括PANet[29]、BiFPN[30]、NAS-FPN[31]、ASFF[32]等。
但是, 这些特征融合网络都存在不足。特征图金字塔网络在各特征层之间的连接仍旧是非常朴素的连接, 导致性能难以提高; 其他网络则通过采用十分复杂的连接与过高的参数量, 可以提高一定的精度, 但是训练十分困难, 同时存在不稳定性。因此, 为了得到一个更加精确和稳定的特征融合网络, 同时保持足够轻便、简洁, 在特征图金字塔网络的基础上提出了一种语义特征一致性监督金字塔网络。该网络的核心采用非对称卷积模块, 其可以在不增加额外超参数情况下, 更加鲁棒地提取特征图的特征[33]。网络结构包括级联的非对称卷积侧接模块和多语义特征增强模块2个部分: 前者将特征提取网络的每层特征图经过非对称卷积模块, 在原有较高空间特征的基础上, 再度增强其空间特征, 将其与特征图金字塔网络自上而下结构中插值的图像相加, 从而更加有效地融合出高语义高空间特征的特征图; 后者同样选取经过非对称卷积模块的每层特征图,通过自适应池化网络级联起来, 再经过3×3卷积精炼且改变通道数, 最后与特征提取网络的高层特征图相加, 由于非对称卷积对于对称特征较好的鲁棒性, 此网络能够显著提升高层特征图的语义信息。
通过实验发现原始特征图金字塔网络中, 最末端用于减轻最近邻插值带来的混叠效应卷积层并没有添加的必要, 当减少这部分卷积模块时, 发现其较原模型预测精度没有太大改变, 但是参数量显著减少, 有利于模型轻量化。由于提出的语义特征一致性网络应用在特征提取网络和候选区域生成网络之间, 并不依赖特定的特征提取网络和预测网络, 所以它可以不经修改地被直接在各类检测器中进行即插即用, 具有灵活性和高效性。同时相比较其他各种多尺度特征融合网络, 语义特征一致性金字塔网络模块清晰, 结构非常简单, 所需参数量较少, 因此所需计算力(FLOPs)同样比较小。在MSCOCO数据集上[34], mAP(mean average precision)为40.0%, 证明了所提出方法的有效性。
1 特征图金字塔网络
1.1 概述
Lin等在2017年提出了一种新的特征图金字塔网络(feature pyramid network, FPN), 在原有特征融合网络的基础上, 将提取到的特征图同时融合较强的空间信息和语义信息, 在不增加额外计算量的情况下, 有效地解决了尺寸差异较大物体的识别问题, 最终达到了较好的识别精度。
1.2 网络结构
特征图金字塔网络模型结构如图 1所示, 左侧为自底向上的特征提取网络, 右侧为自顶向下的小特征图通过插值上采样放大, 中间为左侧不同尺度特征图通过1×1卷积与右侧通道匹配, 而后与右侧上采样的特征图进行像素叠加。最后再经过3×3卷积消除混叠影响得到最终的各个尺度特征图, 而后进行下一步预测。左侧特征提取网络一般选取VGGNet或ResNet, 其通过一系列的卷积层, 有效提取得到不同尺度大小的特征图。
 |
图1 特征图金字塔网络示意图 |
1.3 自底向上结构
此结构是特征提取网络的一部分, 用于提取更高维度、更高语义的特征图, 其内部包含多个卷积层和池化层, 每一个层级经过特征提取后进行步距为2的下采样, 经过5个层级后, 最后输出长宽均缩小至原来的1/32的高维度特征图。之前, 很多目标检测算法就是通过最后输出的高维特征图进行预测, 不过由于高维度的特征图很大程度上丧失了目标特征的空间特征信息, 所以最终结果较差。为了解决这个问题, 在特征图金字塔网络的这部分结构, 选取每一层级最后一层作为本层级的特征图, 每层的特征图都有在其尺度下较为强烈的特征空间信息, 将其保留, 再经过1×1卷积操作微调通道数量, 使得其与右侧特征图通道数匹配, 最后等待与右侧自顶向下结构进行加和操作。
1.4 自顶向下与侧向链接结构
自顶向下结构主要采用最近邻插值的办法, 进行步距为2的上采样, 在保留特征没有显著变化的同时, 将图像边长等比例放大了2倍。为了节省计算资源, 由于自顶而下到最底层特征图对网络效果提升有限, 最后特征图保留从上到下的4个特征图。然后通过侧向链接结构, 将左侧空间特征较强的特征图, 直接与右侧自顶向下上采样的图片进行相加操作, 得到每一层级的特征图同时融合了丰富的语义特征信息及空间特征信息。再经过一个3×3的卷积操作, 消除上采样的混叠效应, 将最后的每一层分别进行预测。
由于后续连接区域生成网络和感兴趣区域池化操作, 需要根据感兴趣区域的特定宽度和高度选取对应的特征图尺度。特征图金字塔网络选择公式为
 (1)
(1)
式中:k0为5, w和h分别对应感兴趣区域(region of interest, ROI)的宽和高, 而224为特征金字塔第五层的大小。
这样就有效地改善了多尺度特征难以发现和融合的问题, 取得到了较好的结果。
2 语义特征一致性监督金字塔网络
2.1 模型简介
针对目标检测的尺度差异大等问题, 基于特征图金字塔网络, 提出了语义特征一致性监督金字塔网络, 如图 2所示。将非对称卷积结构应用于传统特征图金字塔网络模型, 在其自底向上和自顶向下的基础上, 增加了多语义特征增强模块(multi semantic features augmentation, MSFA), 同时将原来的侧接网络, 升级为级联的非对称卷积侧接模块(asymmetric convolution lateral connection, ACLC), 高效解决了顶层语义特征不足和特征融合中空间特征不强问题, 实现了对目标检测准确率的提升。语义特征一致性监督金字塔网络加载在特征提取网络和候选区域生成网络之间。
图像经过左侧特征提取网络, 产生了不同尺度的特征图, 这些特征图经过ACLC模块, 语义特征加强, 而后这些特征网络一方面自适应池化后经过MSFA模块, 空间语义被强化输出到右侧自顶向下结构, 后续与FPN网络相同, 每一阶层特征图通过最近邻差值和左侧另一方面ACLC输出的特征图进行像素相加, 最后对每一层的特征图进行预测(RPN和ROI回归分类)。
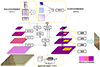 |
图2 语义特征一致性监督金字塔网络 |
2.2 非对称卷积侧接模块
非对称卷积侧接模块主要是为了替代特征图金字塔网络中的1×1卷积。1×1卷积虽然可以很好地进行升维降维操作, 但是由于其本质上为通道加权平均, 无其他操作, 感受野仅仅1个像素, 丧失了与周围的关联, 再对底层特征直接相加会造成一定程度的语义损失。因此, 本文使用非对称卷积, 可以在底层较强的空间特征基础上再度增强, 很好地与自上而下结构中插值上采样得到的特征图特征对齐, 保证输出的特征图能够同时包含高语义信息和空间信息, 最后再附加一个可变形卷积层, 扩大网络感受野, 也同时让网络具备适应目标几何形变的能力。
具体来说, 本网络包含对称卷积层、横向非对称卷积层、纵向非对称卷积层和可变形卷积层。其中对称卷积层的卷积核大小为3×3, 卷积核数量为256, 卷积核步长为1;横向非对称卷积层的卷积核大小为1×3, 卷积核数量为256, 卷积核步长为1;纵向非对称卷积层的卷积核大小为3×1, 卷积核数量为256, 卷积核步长为1。可变形卷积层的卷积核大小为3×3, 卷积核数量为256, 卷积核步长为1;其中纵向非对称卷积和横向非对称卷积过程中需要进行填充操作, 使得最后通过卷积得到的特征图通道数相同且尺度相同。
当特征图分别通过不同的3个卷积层后, 尺度相同, 通过相加操作, 加和在一起, 即得到特征增强的特征图。这部分特征图一路经过多语义特征增强模块, 一路形成侧链接与右侧自上而下结构得到的插值上采样特征图相加, 得到高语义高空间特征, 特征对齐有利于预测特征图。
2.3 多语义特征增强模块
多语义特征增强模块着力增强高层特征图的语义信息, 非对称卷积层已经证明可以有效提取翻转旋转的图像信息特征, 经过池化层统一尺度后, 可以作为顶层特征图增加其原本未能识别出的部分特征, 提升了网络鲁棒性。
因此, 本文设计使用与2.2节共用的非对称卷积层并加和得到每层不同尺度的特征图, 而后针对不同尺度大小的特征图, 分别对应配备不同自适应平均池化层, 而后通过一个对称卷积层和一个通道融合层将级联的特征图特征融合并且将通道数与通过特征提取网络得到的顶层特征图通道数匹配, 最后二者相加, 得到最终语义增强后的顶层特征图, 后输出到自顶而下网络。
网络具体参数: 自适应平均池化层的池化区域随设定输入的输出大小变化, 步长为池化区域大小; 对称卷积层的卷积核大小为3×3, 卷积核数量为256, 卷积核步长为1;通道融合层的卷积核大小为1×1, 卷积核数量为256, 卷积核步长为1。
2.4 整体网络训练
选取数据集原始图像为X={x1, x2, …, xn, …, xN}, 其中xn表示第n个训练样本对应的特征图子集, X′={xn1, xn2, …, xnj, …, xnJ}, xnJ表示xn的第j个层级的原始特征图, J≥4。令Y={y1, y2, …, yn, …, yN}, yn表示xn对应语义信息一致的融合特征图。再令P代表语义特征一致性监督网络, E代表多语义特征增强模块, F代表非对称卷积侧接模块。因此特征尺度融合公式为
 (2)
(2)
式中:F′代表对称卷积层;F代表横向非对称卷积层;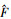 代表纵向非对称卷积层;
代表纵向非对称卷积层;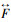 代表可变形卷积层;⊕代表卷积核间并行相加操作;⊗代表卷积核频域相乘操作;F″为一个级联对称卷积层;C为通道融合层;A为自适应平均池化层。
代表可变形卷积层;⊕代表卷积核间并行相加操作;⊗代表卷积核频域相乘操作;F″为一个级联对称卷积层;C为通道融合层;A为自适应平均池化层。
融合特征图结果由语义信息一致性监督网络得到, 是由非对称卷积侧接模块和多语义特征增强模块组合构成的。不同尺度的融合特征图通过不同层级的特征图, 经过多个非对称卷积层、可变形卷积层, 而后通过自适应平均池化、通道融合、级联对称卷积层, 累加而成。
在后续的实验过程中发现, 相较于本文提出的网络模型, 原特征图金字塔网络模型中最后用于消除上采样混叠效应的3×3卷积层对实验结果的影响比较小, 但却导致参数增加。通过将这个模块进行削减, 使得本文提出的网络模型虽然增加了多个模块(MSFA、ACLC), 但其总参数量相比原来特征图金字塔网络模型降低。
3 实验
3.1 其余网络结构
本文实验模型分为两部分, 第一部分是除特征图金字塔网络以外的区域卷积神经网络(R-CNN), 此部分基本上未加改动, 内部包含3个顺次连接的网络: 特征提取网络(feature extraction)、候选区域生成网络(RPN)和感兴趣区域分类回归网络(ROI classification/regression)。第二个部分即加载在特征提取网络和候选区域生成网络之间的语义特征一致性监督金字塔网络。
特征提取网络分别选取ResNet50、ResNet101、ResNeXt101网络用于实验。其一般结构包含数个依次连接的残差单元, 每个残差单元包含3个依次层叠的对称卷积层, 卷积核大小依次为3×3, 1×1, 3×3, 卷积核数量大于64, 卷积核步长为1。
候选区域生成网络对每个语义信息一致的融合特征图yn进行感兴趣区域位置初步预测。其包含一个融合卷积层、前背景分类卷积层、锚点位置卷积回归层。融合卷积层的卷积核大小为3×3, 卷积核数量为512, 卷积核步长为1;前背景分类卷积层的卷积核大小为1×1,卷积核数量为3, 卷积核步长为1;锚点位置卷积回归层的卷积核大小为1×1, 卷积核数量12, 卷积核步长为1。
感兴趣区域分类回归网络对yn的感兴趣区域位置预测结果进行目标分类和位置精确预测, 其中包含感兴趣区域分类层和感兴趣区域位置回归层, 感兴趣区域分类的卷积核大小为3×3, 卷积核数量为81, 卷积核步长为1, 感兴趣区域位置回归层卷积核大小为3×3, 卷积核数量为4, 卷积核步长为1。最终得到预测结果T={t1, t2, …, tn, …, tN}, 其中, tn表示yn对应的包括目标类别tncls和位置tnloc的预测结果, tn=(tncls, tnloc)。
而后使用反向传播算法对误差进行更新,Log损失函数计算感兴趣区域分类回归网络分类预测结果tncls与训练样本的目标类别标签为kncls的分类误差:
 (3)
(3)
Smooth L1损失函数计算感兴趣区域分类回归网络位置预测结果tnloc与训练样本的目标位置坐标为knloc的回归误差, 损失函数公式为
 (4)
(4)
最后, 采用随机梯度下降法来降低分类误差与回归误差, 对实验模型的第一部分,除FPN网络以外的区域卷积神经网络S中卷积核参数ωt、各全连接层节点之间的参数vt进行更新, 得到更新后的St, 角标t代表模型迭代次数, 更新公式为
 (5)
(5)
 (6)
(6)
式中, η表示学习步长, 0.002≤η≤0.02, ωt+1和vt+1分别表示ωt和vt更新后的结果。
3.2 数据集
实验的数据集采用Microsoft COCO: common objects in context图像数据集, 该数据集为大规模标注数据集, 包含目标检测、图像实例分割、图像全景分割、图像关键点检测等任务。本网络所使用训练集与测试集图像输入尺寸为1 333×800。
3.3 评价标准
所有类别的平均精确度mAP(mean average precision)是衡量目标检测模型针对多尺度多类别目标检测效能的指标, 包含: AP、AP50、AP75、AP small、AP medium、AP Large、AR等。
FLOPs(floating point operations)是算法模型的浮点运算数, 是衡量模型复杂度的指标。数值越大代表模型越大, 计算量越大。
3.4 设备与参数设置
仿真实验的硬件测试平台是: Intel(R) Xeon(R) Silver 4114 CPU, 主频为2.20 GHz, 内存128 GB, GPU为4路NVIDIA Tesla V100 32 GB。软件平台是: Ubuntu 16.04.6 LTS操作系统, 编程语言Python 3.8、深度学习框架PyTorch 1.6。
为了保证特征结果一致性, 中间附加的卷积层维度都选择统一的256维, 学习步长η选择0.02, 特征图数J选择4, 最大迭代次数T选择30代。
3.5 实验结果
图 3给出了可视化对比结果, 图 3a)是原始图片, 图 3b)是特征金字塔网络得到的融合后热力图, 图 3c)是语义特征一致性监督金字塔网络得到的融合后热力图, 图 3d)是本文方法的检测分类器根据特征图最终得到的目标框。从图中对比结果可以看出, 原有的特征金字塔网络得到的融合特征图整体热度较高, 包含了大量冗余信息, 导致后续难以区分特征, 造成部分目标遗失。而本文所提方法得到的特征图中非目标区域热度较低, 目标区域与非目标区域分割明显, 冗余信息较少, 不容易产生虚警和漏检。
图 4给出了另一组可视化实验结果, 图 4a)是人工标注的目标框, 图 4b)是基线检测器检测出来的结果, 图 4c)是本文方法的检测器检测出的结果。可以看到相比于基线方法的结果, 本文方法可以更加有效地检测到图中的甜甜圈和棒球手套等小目标, 以及熊这种特征较大但与背景区分不明显的目标。
目标检测平均准确率的对比结果如表 1所示。从中可以看出, 在Microsoft COCO图像数据集上测试, 使用Faster R-CNN方法, 选择ResNet50作为特征提取网络, 学习率调整一次。在平均准确率AP上, 本文方法为40.0%, 较现有类似的最新方法SABL(ECCV2020)、AugFPN(CVPR2020)和PConV(CVPR2020)都有提高, 说明本文提出的方法能够提高检测精度。在其他几个精确率指标上, 整体上也有提升。同时, 从计算复杂度或者说计算时间上, 本文方法的浮点运算数为196G, 相较于对比方法分别降低了27%, 22%和18%。实验结果表明, 本文提出的基于语义特征一致性的监督金字塔网络模型, 能够减少计算量,同时还能提升目标的检测精度。
 |
图3 可视化实验结果1 |
 |
图4 可视化实验结果2 |
基于语义特征一致性监督金字塔网络的目标检测平均准确率 %
4 结论
本文针对特征金字塔网络存在的顶层语义特征不足和特征融合中空间特征不强等问题, 提出了基于语义特征一致性的监督金字塔网络。不同于特征金字塔网络中使用1×1卷积进行侧向连接, 本文引入了非对称卷积侧接模块, 扩大网络感受野同时再度增强底层空间特征, 让网络具备适应目标几何形变的能力。而为了获取顶层更强的语义特征, 本文采用多语义特征增强模块, 增强了顶层特征信息, 提升了网络鲁棒性。实验结果表明, 本文提出的方法能够在不增加计算量的前提下提升目标检测精度, 且在一定程度上改善了对小目标的检测能力。未来, 研究重点将放在如何将模型更加轻量化并且不损失检测精度, 使其能够部署在算力较弱的终端设备中。
References
- YANG Minghsuan, KRIEGMAN D J, AHUJA N, et al. Detecting faces in images: a survey[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2002, 24(1): 34–34. [Article] [CrossRef] [Google Scholar]
- ZHANG C, ZHANG Z. A survey of recent advances in face detection[R]. MSR-TR-2010-66 [Google Scholar]
- WOJEK C, DOLLAR P, SCHIELE B, et al. Pedestrian detection: an evaluation of the state of the art[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2012, 34(4): 743. [Article] [CrossRef] [Google Scholar]
- BENENSON R, OMRAN M, HOSANG J, et al. Ten years of pedestrian detection, what have we learned?[C]//European Conference on Computer Vision Workshops, 2014: 613–627 [Google Scholar]
- LI Mingxi, LIN Zhengkui, QU Yi. Survey of vehicle object detection algorithm in computer vision[J]. Computer Engineering and Applications, 2019, 55(24): 20–28 (in Chinese) [Google Scholar]
- MA Yuzhen, HU Liang, FANG Zhiqiang, et al. Development and application research of computer vision detection technique[J]. Journal of University of Jinan, 2004(3): 222–227 (in Chinese) [Google Scholar]
- HUANG Wenqing, WANG Yaming, ZHOU Zhiyu. Application of computer vision technology in the field of industry[J]. Journal of Zhejiang Institute of Science and Technology, 2002(2): 28–32 (in Chinese) [Google Scholar]
- DUAN Feng, WANG Yaonan, LEI Xiaofeng, et al. Machine vision technologies[J]. Automation Panorama, 2002(3): 62–64 (in Chinese) [Google Scholar]
- ZOU Z, CHEN K, SHI Z, et al. Object detection in 20 years: a survey[J]. Proceedings of the IEEE, 2023, 111(3): 257–276. [Article] [CrossRef] [Google Scholar]
- VIOLA P A, JONES M J. Rapid object detection using a boosted cascade of simple features[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2001 [Google Scholar]
- VIOLA P, JONES M J. Robust real-time face detection[J]. International Journal of Computer Vision, 2004, 57(2): 137–154. [Article] [CrossRef] [Google Scholar]
- DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2005 [Google Scholar]
- FELZENSZWALB P F, MCALLESTER D A, RAMANAN D. A discriminatively trained, multiscale, deformable part model[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2008 [Google Scholar]
- GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580–587 [Google Scholar]
- HE Kaiming, ZHANG Xianggu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904–1920. [Article] [CrossRef] [Google Scholar]
- GIRSHICK R. Fast R-CNN[C]//IEEE International Conference on Computer Vision, Santiago, 2015: 1440–1448 [Google Scholar]
- REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. [Article] [CrossRef] [Google Scholar]
- REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//IEEE International Conference on Computer Vision, 2016 [Google Scholar]
- REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2017 [Google Scholar]
- REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. (2018-04-08)[2021-02-18]. [Article] [Google Scholar]
- BOCHKOVSKIY A, WANG C Y, LIAO H. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23)[2023-09-25]. [Article] [Google Scholar]
- LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]//European Conference on Computer Vision, Amsterdam, Netherlands, 2016: 21–37 [Google Scholar]
- FU C Y, LIU W, RANGA A, et al. DSSD: Deconvolutional single shot detector[EB/OL]. (2017-01-23)[2023-09-25]. [Article] [Google Scholar]
- LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//IEEE International Conference on Computer Vision, 2017 [Google Scholar]
- TIAN Z, SHEN C, CHEN H, et al. FCOS: fully convolutional one-stage object detection[C]//IEEE International Conference on Computer Vision, 2020 [Google Scholar]
- CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]//European Conference on Computer Vision, Cham, 2020: 213–229 [Google Scholar]
- AD ELSON E H, ANDERSON C H, BERGEN J R, et al. Pyramid methods in image processing[J]. RCA Engineer, 1984, 29(6): 33–41 [Google Scholar]
- LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2017 [Google Scholar]
- LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2018: 8759–8768 [Google Scholar]
- TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2020 [Google Scholar]
- GHIASI G, LIN T Y, LE Q V. NAS-FPN: learning scalable feature pyramid architecture for object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2019 [Google Scholar]
- LIU S, HUANG D, WANG Y. Learning spatial fusion for single-shot object detection[EB/OL]. (2019-11-21)[2023-09-25]. [Article] [Google Scholar]
- DING X, GUO Y, DING G, et al. ACNet: strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks[C]//IEEE International Conference on Computer Vision, 2019: 1911–1920 [Google Scholar]
- LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//European Conference on Computer Vision, 2014 [Google Scholar]
All Tables
All Figures
|
图1 特征图金字塔网络示意图 |
| In the text | |
|
图2 语义特征一致性监督金字塔网络 |
| In the text | |
|
图3 可视化实验结果1 |
| In the text | |
|
图4 可视化实验结果2 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.