| Issue |
JNWPU
Volume 39, Number 5, October 2021
|
|
|---|---|---|
| Page(s) | 1122 - 1129 | |
| DOI | https://doi.org/10.1051/jnwpu/20213951122 | |
| Published online | 14 December 2021 | |
The manifold embedded selective pseudo-labeling algorithm and transfer learning of small sample dataset
流形嵌入的选择性伪标记与小样本数据迁移
1
College of Information and Computer, Taiyuan University of Technology, Taiyuan 030024, China
2
School of Marine Science and Technology, Northwestern Polytechnical University, Xi'an 710072, China
Received:
1
February
2021
Abstract
Special scene classification and identification tasks are not easily fulfilled to obtain samples, which results in a shortage of samples. The focus of current researches lies in how to use source domain data (or auxiliary domain data) to build domain adaption transfer learning models and to improve the classification accuracy and performance of small sample machine learning in these special and difficult scenes. In this paper, a model of deep convolution and Grassmann manifold embedded selective pseudo-labeling algorithm (DC-GMESPL) is proposed to enable transfer learning classifications among multiple small sample datasets. Firstly, DC-GMESPL algorithm uses satellite remote sensing image sample data as the source domain to extract the smoke features simultaneously from both the source domain and the target domain based on the Resnet50 deep transfer network. This is done for such special scene of the target domain as the lack of local sample data for forest fire smoke video images. Secondly, DC-GMESPL algorithm makes the source domain feature distribution aligned with the target domain feature distribution. The distance between the source domain and the target domain feature distribution is minimized by removing the correlation between the source domain features and re-correlation with the target domain. And then the target domain data is pseudo-labeled by selective pseudo-labeling algorithm in Grassmann manifold space. Finally, a trainable model is constructed to complete the transfer classification between small sample datasets. The model of this paper is evaluated by transfer learning between satellite remote sensing image and video image datasets. Experiments show that DC-GMESPL transfer accuracy is higher than DC-CMEDA, Easy TL, CMMS and SPL respectively. Compared with our former DC-CMEDA, the transfer accuracy of our new DC-GMESPL algorithm has been further improved. The transfer accuracy of DC-GMESPL from satellite remote sensing image to video image has been improved by 0.50%, the transfer accuracy from video image to satellite remote sensing image has been improved by 8.50% and then, the performance has been greatly improved.
摘要
特殊场景分类和识别任务面临样本不易获得而造成样本缺乏,利用源域(或称辅助域)数据构建领域自适应迁移学习模型,提高小样本机器学习在这些困难场景中的分类准确度与性能是当前研究的热点与难点。提出深度卷积与格拉斯曼流形嵌入的选择性伪标记算法(deep convolution and Grassmann manifold embedded selective pseudo-labeling,DC-GMESPL)模型,以实现在多种小样本数据集间迁移学习分类。针对目标域特殊场景,如森林火灾烟雾视频图像的本地样本数据缺乏情景,使用卫星遥感图像异地样本数据作为源域,基于Resnet50深度迁移网络,同时提取源域与目标域的烟雾特征;通过去除源域特征间的相关性,并与目标域重新关联,最小化源域与目标域特征分布距离,使源域与目标域特征分布对齐;在格拉斯曼流形空间中,用选择性伪标记算法对目标域数据作伪标记;构建一种可训练模型完成小样本数据间迁移分类。通过卫星遥感图像与视频影像数据集间迁移学习,对文中模型进行评估。实验表明,DC-GMESPL迁移准确率均高于DC-CMEDA、Easy TL、CMMS和SPL等方法。与作者先期研究的DC-CMEDA算法相比,新算法DC-GMESPL的准确率得到进一步提升;DC-GMESPL从卫星遥感图像到视频图像迁移准确率提高了0.50%,而从视频图像到卫星遥感图像迁移准确率提高了8.50%,且在性能上有了很大改善。
Key words: transfer learning / domain adaptation / deep convolution neural networks / small sample dataset / forest fire smoke features
关键字 : 迁移学习 / 领域自适应 / 深度卷积神经网络 / 小样本数据集 / 森林火灾烟雾特征
© 2021 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
特殊场景分类和识别任务常常因样本不易获得而造成样本缺乏,即产生所谓小样本问题。如何提高小样本机器学习在这些困难场景中的分类准确度与性能是当前研究的热点与难点1-3。其中领域自适应迁移学习方法,利用源域信息对目标域数据进行标注分类具有较好效果。通常领域自适应迁移学习方法有子空间学习法和概率分布适配法等。
子空间学习方法主要由统计特性变换与流形学习两方面组成。在统计特性变换方面,子空间对齐法(SA)4通过优化将辅助域子空间转换为目标子空间的映射函数来使辅助域子空间和目标域子空间靠近,直接减小2个域之间差异;子空间分布对齐(SDA)5则是通过增加子空间方差自适应扩展了子空间对齐法,但未考虑子空间局部属性,忽略了条件分布对齐;关联对齐法(CORAL)6用二阶统计量对子空间对齐,但未考虑分布对齐;散点成分分析(SCA)7是通过将样本转化为一组子空间,再最小化子空间之间的散度。在流形学习方面,采样测地线流方法(SGF)8把领域自适应看成是一个增量式"行走"问题,在流形空间中采样有限点,构建测地线流;测地线流式核方法(GFK)9则扩展了流形中采样点方法,提出了域间测地线流核学习方法;域不变映射(DIP)10是通过使用格拉斯曼流形进行域自适应,但其忽略了条件分布对齐;统计流形法(SM)11则是利用海林格距离近似黎曼空间中的测地线距离。
概率分布适配法主要由边缘分布适配、条件分布适配以及联合分布适配等3种方法构成。最早将条件分布适配应用到迁移学习,是通过特征子集对条件概率模型的域自适应实现的,后期通过对条件转移成分(CTC)12进行建模,使条件分布适配方法得到发展。迁移成分分析(TCA)13法是将边缘分布适配应用到迁移学习中,后经多位学者对迁移成分分析进行了扩展,如ACA14、DTMKL15、DME16、CMD17方法等。联合分布对齐(JDA)取边缘分布与条件分布的等量权值,但未考虑边缘分布与条件分布的侧重性。平衡分布适配(BDA)18改进了联合分布对齐,该方法考虑了域间分布适应性,能够自适应地改变每个类的权重。流形嵌入分布对齐法(MEDA)19结合概率分布适配与子空间学习方法,为定量计算自适应因子提供了一种可行方法。关联式流形分布配准算法(DC-CMEDA)2则针对上述问题,利用深度学习方法对源域与目标域图像数据提取高层语义特征,然后用子空间学习方法学习源域辅助信息,对目标域数据标注分类,提高了从卫星遥感图像到视频图像迁移准确率,且解决了目标域数据不足问题。但该算法在视频图像迁移至卫星遥感图像时,准确率仍较低。
现有烟雾图像检测技术主要为基于深度学习类的烟雾识别方法20。该类方法对具体样本数据依赖性较强,要求样本满足独立同分布,且需要足够多的训练样本。
针对森林火灾烟雾本地样本数据缺乏的目标域特殊场景,本文提出一种结合深度迁移网络和改进的格拉斯曼流形空间中选择性结构伪标记算法(deep convolution and Grassmann manifold embedded selective pseudo-labeling, DC-GMESPL),试图建立一种精度高、耗时少的基于小样本数据的迁移模型。
1 算法描述
以下详细描述DC-GMESPL算法中特征提取模型及格拉斯曼流形选择性伪标记算法。算法基本流程如图 1所示。
 |
图1 DC-GMESPL流程图 |
1.1 基于Resnet50特征提取模型
本文基于Resnet50网络搭建深度迁移特征提取模型。该模型由卷积层和下采样层交替构成,包含49个卷积层、4个下采样层。其中,第一段由7×7×64卷积核构成一层卷积层;第二段由3个瓶颈结构构成,每个瓶颈结构分别包含1×1×64,3×3×64,1×1×256卷积核构成的3层卷积层;第三段由4个瓶颈结构构成,每个瓶颈结构分别包含1×1×128,3×3×128,1×1×512卷积核构成的3层卷积层;第四段由6个瓶颈结构构成,每个瓶颈结构分别包含1×1×256,3×3×256,1×1×1 024卷积核构成的3层卷积层;第五段由3个瓶颈结构构成,每个瓶颈结构分别包含1×1×512,3×3×512,1×1×2 048卷积核构成的3层卷积层。图 2为基于Resnet50网络的迁移学习模型图。
 |
图2 基于Resnet50网络迁移学习模型 |
1.2 格拉斯曼流形选择性伪标记法
本文将特征分布关联对齐法6、流形特征变换法9及选择性伪标记法4三者结合,提出格拉斯曼流形选择性伪标记方法。
1.2.1 特征分布关联对齐
特征分布关联对齐是在原始空间中进行的。本文使用A对原始空间中源域特征作线性变换, 其中, CovS表示源域特征变换后的协方差矩阵, CovT表目标域协方差矩阵。使用Frobenius范数作为矩阵距离度量, 表示如下:
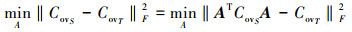 (1)
(1)
通过求解线性变换矩阵A, 令(1)式为0, 得
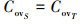 (2)
(2)
分别对CovS与CovT进行奇异值分解, 得
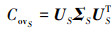 (3)
(3)
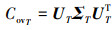 (4)
(4)
式中:ΣS, ΣT为奇异值矩阵; US, U为左奇异向量; UTS, UTT为右奇异向量。因此
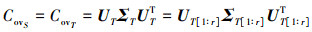 (5)
(5)
式中, 秩r取源域和目标域协方差矩阵秩的最小值, 即
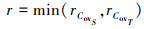 (6)
(6)
由(1)式、(4)式得
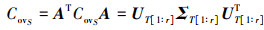 (7)
(7)
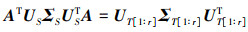 (8)
(8)
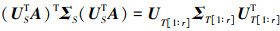 (9)
(9)
令E=ΣS+1/2UTSUT[1∶r]ΣT[1∶r]1/2UTT[1∶r], 则
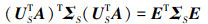 (10)
(10)
式中,ΣS+为ΣS的广义逆。
由(10)式, 得
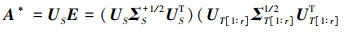 (11)
(11)
式中, USΣS1/2UTS可视为去除源域特征相关性, UT[1∶r]ΣT[1∶r]1/2UTT[1∶r]视为对目标域重新关联, 并将目标域的关联添加到源域特性中。此时, 源域与目标域输入特征分布已粗略对齐。
1.2.2 流形空间特征变换
经原始空间的输入特征分布对齐后, 可通过流形空间的流形特征学习消除退化的特征变换。
在学习流形特征变换时, 先用d维子空间建模数据领域, 然后将这些子空间嵌入到流形G中。用S和T分别表示源域和目标域经过主成分分析(PCA)之后的子空间。G可视为所有d维子空间集合, 每个d维原始子空间都可看作G上的点, 因此原始空间中源域子空间S、目标域子空间T在Grassmann流形空间中可视作2个点, 而两点之间的测地线{Φ(t): 0≤t≤1}可以在2个子空间之间构成一条路径。
如令S=Φ(0), T=Φ(1), 则寻找一条从Φ(0)到Φ(1)测地线等同于将原始空间特征变换到一个无穷维度空间中, 最终减小域之间漂移现象, 如图 3所示。图 3中, 左边表示原始空间中分别用源域S和目标域T表示经主成分分析之后的子空间; 右边表示Grassmann流形空间中源域、目标域及其间的测地线。
将流形空间特征表示为
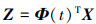 (12)
(12)
变换后特征zi和zj的内积定义了一个半正定的测地线流式核。
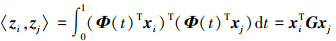 (13)
(13)
因此, 通过 , 原始空间特征可变换至Grassmann流形空间中, 核G由矩阵奇异值分解计算得出。
, 原始空间特征可变换至Grassmann流形空间中, 核G由矩阵奇异值分解计算得出。
 |
图3 流形特征变换 |
1.2.3 选择性伪标记法
为提高域类对齐准确率, 可通过局部保持投影21算法将2个域样本映射至相同子空间, 然后利用结构化预测法挖掘目标域的结构信息, 提高源域、目标域对齐效能以及伪标记的准确性。
1) 有监督局部保持投影法
有监督局部保持投影能够学习定义域不变的判别子空间C。它通过学习投影矩阵P, 将来自2个域样本映射到相同子空间。学习该投影矩阵P的最小化代价函数形式化表达为
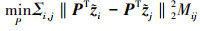 (14)
(14)
P为d1×d2维矩阵, 且有d2≤d1;  是标记数据矩阵
是标记数据矩阵 的第i列, 其中,
的第i列, 其中,  是包含ns个带标记的源数据和n′t个被选择的伪标记目标数据集合。M则是相似度矩阵, 定义如下
是包含ns个带标记的源数据和n′t个被选择的伪标记目标数据集合。M则是相似度矩阵, 定义如下
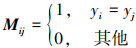 (15)
(15)
当试图提高域不变性, 同时保留域差异性时, 相似度矩阵本质上是对MMD19度量的简化。
(14) 式损失函数可重写为
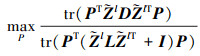 (16)
(16)
式中:L=D-M是拉普拉斯矩阵; D为对角矩阵; tr(PTP)是一个正则化项, 用于惩罚投影矩阵P中的极值。(17)式的广义特征值求解式是(16)式的重定义等价式。
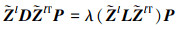 (17)
(17)
求解广义特征值得到最优解P=p1, p2, …, pd2, p1, p2, …, pd2是对应于最大的d2个特征值的特征向量。
在学习并更新投影矩阵P过程中, 首先利用带有标记的源域数据学习投影矩阵P0, 得到P0后可将源域与目标域样本映射到相同子空间, 并通过最近邻类原型和结构化预测为目标域数据分配伪标签22。然后在该公共子空间中, 结合伪标记目标样本和标记源样本, 使用迭代学习过程更新投影矩阵P, 并改进伪标记。
2) 目标域样本伪标记法
为了得到目标域样本的伪标签, 可以分别通过最近邻类原型和结构化预测来对目标域样本进行伪标记。
最近邻类原型伪标记法
最近邻类原型伪标记将未标记目标样本标记在学习子空间G中, 因此, 源样本和目标样本投影可表示为
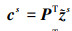 (18)
(18)
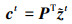 (19)
(19)
使用平均聚类集中化方法以及L2正则化方法等, C空间中不同的类的可分性。
我们定义类y的类原型定义为标签为y的投影源样本的均值向量, 其计算公式为
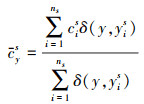 (20)
(20)
式中, y=1, …, |y|, |y|表示类数量
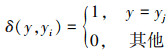 (21)
(21)
对类原型 归一化后, 可计算给定目标样本zt属于y类的条件概率
归一化后, 可计算给定目标样本zt属于y类的条件概率
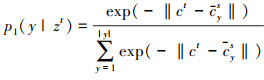 (22)
(22)
结构预测伪标记法
我们使用K-means生成所有目标样本投影向量上的|y|簇。
令B∈{0, 1}|y|×|y|为一对一匹配矩阵, 当Bij=1时, 表示第i个目标簇与第j个源类匹配, 因此, 优化表达式为
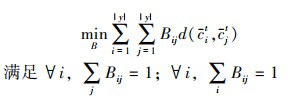 (23)
(23)
使用线性规划可得出(23)式有效解。因此, 可以计算给定目标样本zt属于y类的条件概率为
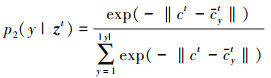 (24)
(24)
改进伪标记法
使用迭代学习策略学习用于区域对齐的投影矩阵P, 并对目标样本的伪标记进行改进。
将最近邻类原型的伪标记与结构化预测伪标记二者结合, 其条件概率表示为
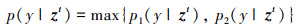 (25)
(25)
给定目标样本zt的伪标签则可以通过以下方法预测:
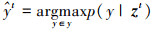 (26)
(26)
伪标签目标样本集 可表示为以下三元组
可表示为以下三元组
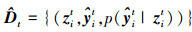 (27)
(27)
由于局部投影学习并不使用 中所有伪标记目标样本, 而是逐步选择其中一部分, 即选择带有伪标签目标样本中的一个子集
中所有伪标记目标样本, 而是逐步选择其中一部分, 即选择带有伪标签目标样本中的一个子集 。为使分类器变得强壮, 需要逐步将置信度高的伪标记样本加入有监督训练集, 参与学习过程。如在第k次迭代中, 可选择包含
。为使分类器变得强壮, 需要逐步将置信度高的伪标记样本加入有监督训练集, 参与学习过程。如在第k次迭代中, 可选择包含 个目标样本子集投影学习, 其中, T为学习过程的迭代次数。
个目标样本子集投影学习, 其中, T为学习过程的迭代次数。
为避免子集选取时, 只从特定类中选择样本, 而忽略了其他类的情况发生。例如, 对于y类, 首先选取伪标记为类别y的nty个目标域样本, 然后可从中选取 个可信度高的伪标签样本加入训练中。
个可信度高的伪标签样本加入训练中。
2 实验结果分析
本节展示了本文方法在不同分辨率烟雾图像小数据集上的迁移学习分类效果。
2.1 数据集
本文选用200张异地卫星遥感图像与200张本地视频影像作为实验数据。其中每个领域分别包括100张有烟图像与100张无烟图像。本地影像数据集来源于山西省林科院引进ForestWatch林火智能监测系统。
2.2 评价标准
本文利用准确率(Raccuracy)、精确率(Rprecision)、召回率(Rrecall)和两者调和均值(RF1)衡量算法性能。令烟雾图像为正类, 非烟雾图像为负类, 公式如下:
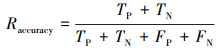 (28)
(28)
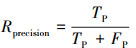 (29)
(29)
 (30)
(30)
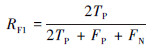 (31)
(31)
式中:TP表示预测正类为正类; TN表示预测负类为负类; FP表示预测负类为正类; FN表示预测正类为负类。
2.3 不同算法对比试验和结果
从表 1中可看出, 当卫星遥感样本集作为源域, 视频影像样本集作为目标域时, 无论从假阳性、假阴性的角度, 还是从准确率角度看, DC-GMESPL的迁移效果均优于Easy TL、CMMS、SPL方法, 其中, 假阳性为4.85%、假阴性为2.07%和准确率为96.50%。与DC-CMEDA相比, DC-GMESPL虽然假阳性相对较高, 但是对森林防火烟雾图像识别并不会造成太大影响; 而DC-CMEDA的假阴性较高, 烟雾图像误判为非烟雾图像的概率较大, 却很容易因监测失误而造成漏警; 此外, DC-GMESPL的准确率相对更高。因此, 综合评估, DC-GMESPL优于DC-CMEDA。从表 2中可看出, 当视频影像样本集作为源域, 卫星遥感样本集作为目标域时, DC-GMESPL的迁移效果远优于Easy TL、CMMS、SPL、DC-CMEDA方法, 其中, 假阳性为2.94%、假阴性为1.02%和准确率为98.00%, 准确率有了较大提升。
1) 在流形空间中进行选择性伪标记更有利于提高源域、目标域对齐效果以及分类准确性。
2) 利用最近邻类原型方法和结构化预测方法分别对目标域样本进行伪标记, 选取概率大的伪标记作迭代可以很大程度提高分类效能。
3) 基于Resnet50特征提取模型可以提取图像深层语义信息, 利用聚类分析可以实现精确的伪标记。
图 4显示, 当卫星遥感样本作为源域, 视频影像样本作为目标域时, DC-GMESPL的召回率、调和均值及准确率都高于Easy TL、CMMS、SPL、DC-CMEDA方法, 精确率略低于DC-CMEDA。因为森林防火应用场景, 希望误判概率尽可能小, 避免因监测失误而造成火灾, 因此, DC-GMESPL优于其他方法。从图 5可看出, 当视频影像样本集作为源域, 卫星遥感样本集作为目标域时, DC-GMESPL在精确率、召回率、调和均值及准确率4个指标中的优势都非常明显, 迁移效果好。
对比图 4与图 5可发现, 在迁移效果提升方面, DC-GMESPL从卫星遥感图像迁移到视频图像与从视频图像迁移到卫星遥感图像上提升的幅度相差较大; 出现这种现象的原因主要在于最近邻类原型方法与结构化预测方法都利用源域内标记样本的类原型完成伪标记, 由于视频图像较卫星遥感图像分辨率更高, 作为源域, 获取的类原型更佳, 通过2种方法获取的最终伪标记结果更准确, 因此, 从视频图像迁移到卫星遥感图像上提升的准确率更高, 而从卫星遥感图像迁移到视频图像上提升的准确率相对较低。
卫星遥感图像到视频影像图像的迁移准确性对比
视频影像图像到卫星遥感图像的迁移准确性对比
 |
图4 卫星遥感图像迁移视频影像图像各方法性能对比 |
 |
图5 视频影像图像迁移卫星遥感图像各方法性能对比 |
3 结论
本文以森林火灾烟雾图像识别分类为例, 提出了DC-GMESPL小样本数据迁移算法解决方案。结果表明, 综合各种检测指标, DC-GMESPL模型优于其他方法。需注意的是, 在使用本方法进行小样本迁移时, 小样本图像需具有足够有效特征, 以便于在格拉斯曼流形空间中对特征进行有效处理; 其次, 源域与目标域的小样本图像特征虽无需满足独立同分布, 但要求源域与目标域的任务对象保持一致。本文虽然以森林火灾烟雾为实验对象验证了DC-GMESPL方法, 但该方法对其他情形仍然适用; 如不同视角、不同背景、不同光照图像的其他对象识别, 即源域与目标域的特征分布具有差异, 但学习与识别的任务一致。未来, 我们将优化模型, 进一步提高算法的泛化性能。
References
- Wang Yaoli, Wang Lipo, Yang Fangjun, et al. Advantages of direct input-to-output connections in neural networks: the Elman network for stock index forecasting[J]. Information Sciences, 2021, 547 : 1066–1079. [Article] [CrossRef] [Google Scholar]
- Wang Yaoli, Liu Xiaohui, Li Maozhen, et al. Deep convolution and correlated manifold embedded distribution alignment for forest fire smoke prediction[J]. Computing and Informatics, 2020, 39(1/2)318–339 [CrossRef] [Google Scholar]
- Karlweiss T K, Wang D. A survey of transfer learning[J]. Journal of Big Data, 2016, 3(9) : 1–40 [CrossRef] [Google Scholar]
- Fernando B, Habrard A, Sebban M, et al. Unsupervised visual domain adaptation using subspace alignment[C]//Proceedings of the IEEE International Conference on Computer Vision, 2013: 2960–2967 [Google Scholar]
- Sun Baochen, Saenko Kate. Subspace distribution alignment for unsupervised domain[C]//Proceedings of BMVC, 2015 [Google Scholar]
- Sun Baochen, Feng Jiashi, Saenko Kate. Return of frustratingly dasy domain adaptation[C]//Proceedings of 30th AAAI Conference on Artificial Intelligence, 2016 [Google Scholar]
- Ghifary M, Balduzzi D, Kleijn W B, et al. Scater component analysis: a unified framework for domain adaptation and domain generalization[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2017, 39(7) : 1414–1430. [Article] [CrossRef] [Google Scholar]
- Gopalan R, Li R, Chellappa R. Domain adaptation for object recognition: an unsupervised approach[C]//Proceedings of the IEEE International Conference on Computer Vision, 2011 [Google Scholar]
- Gong Boqing, Shi Yuan, Sha Fei, et al. Geodesic flow kernel for unsupervised domain adaptation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2012 [Google Scholar]
- Baktashmotlagh Mahsa, Harandi Mehrtash, Salzmann Mathieu. Distribution-matching embedding for visual domain adaptation[J]. Journal of Machine Learning Research, 2016, 17 : 3760–3789 [Google Scholar]
- Baktashmotlagh M, Harandi M T, Lovell B C, et al. Domain adaptation on the statistical manifold[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014 [Google Scholar]
- Gong M, Zhang K, Liu T, et al. Domain adaptation with conditional transferable components[C]//Proceedings of International Conference on Machine Learning, 2016 [Google Scholar]
- Pan S J, Tsang I W, Kwok J T, et al. Domain adaptation via transfer component analysis[J]. IEEE Trans on Neural Networks, 2011, 22(2) : 199–210. [Article] [CrossRef] [Google Scholar]
- Dorri F, Ghodsi A. Adapting component analysis[C]//Proceedings of the IEEE 12th International Conference on Data Mining, 2012: 846–851 [Google Scholar]
- Duan L, Tsang I W, Xu D. Domain transfer multiple kernel learning[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2012, 34(3) : 465–479. [Article] [Google Scholar]
- Zellinger W, Grubinger T, Lughofer E, et al. Central moment discrepancy (CMD) for domain-invariant representation learning[C]//Proceedings of the International Conference on Learning Representations, 2017 [Google Scholar]
- Long M, Wang J, Ding G, et al. Transfer feature learning with joint distribution adaptation[C]//IEEE International Conference on Computer Vision, 2013 [Google Scholar]
- Wang Jindong, Chen Yiqiang, Hao Shuji, et al. Balanced distribution adaptation for transfer learning[C]//Proceedings of the IEEE International Conference on Data Mining, 2017: 1129–1134 [Google Scholar]
- Wang Jindong, Feng Wenjie, Chen Yiqiang, et al. Visual domain adaptation with manifold embedded distribution alignment[C]//Proceedings of the 26th ACM International Conference on Multimedia, 2018 [Google Scholar]
- Bu Fengju, Mohammad Samadi Gharajeh. Intelligent and vision-based fire detection systems: a survey[J]. Image and Vision Computing, 2019, 91(2) : 103803 [CrossRef] [Google Scholar]
- He Xiaofei, Niyogi Partha. Locality preserving projections[C]//Proceedings of the 16th International Conference on Neural Information Processing Systems, 2003: 153–160 [Google Scholar]
- Pei Zhongyi, Cao Zhangjie, Long Mingsheng, et al. Multi-adversarial domain adaptation[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2018 [Google Scholar]
All Tables
All Figures
|
图1 DC-GMESPL流程图 |
| In the text | |
|
图2 基于Resnet50网络迁移学习模型 |
| In the text | |
|
图3 流形特征变换 |
| In the text | |
|
图4 卫星遥感图像迁移视频影像图像各方法性能对比 |
| In the text | |
|
图5 视频影像图像迁移卫星遥感图像各方法性能对比 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.