| Issue |
JNWPU
Volume 44, Number 1, February 2026
|
|
|---|---|---|
| Page(s) | 125 - 133 | |
| DOI | https://doi.org/10.1051/jnwpu/20264410125 | |
| Published online | 27 April 2026 | |
Study on load prediction methods of embedded container-based applications
面向嵌入式容器应用的负载预测方法研究
1
School of Software, Northwestern Polytechnical University, Xi'an 710072, China
2
AVIC the First Aircraft Institute, Xi'an 710089, China
Received:
16
May
2025
Abstract
Currently, the use of virtual container architectures in embedded computing environments is becoming increasingly popular, offering new possibilities for resource scheduling to balance load fluctuations. However, effective scheduling relies heavily on accurate load prediction, and existing research in this area suffers from a lack of dedicated datasets and inadequate adaptation of existing prediction methods to the characteristics of embedded applications. Focusing on an avionics embedded application scenario, a dataset tailored to containerized embedded environments is constructed. To address the issues of low prediction accuracy and computational inefficiency, a lightweight load prediction model is proposed by integrating the CEEMDAN algorithm with the Informer model. The CEEMDAN algorithm enhances the modeling accuracy by decomposing the time series data, while the Informer model reduces the computational complexity and memory consumption through a sparse self-attention mechanism. Experimental results demonstrate that, comparing with the mainstream time series prediction methods, the present model achieves an average reduction of about 10% in prediction errors and is well-suited for embedded application scenarios.
摘要
当前随着虚拟容器架构在嵌入式计算环境中的广泛应用, 调度资源优化得以实现对负载动态变化的自适应, 但其效果高度依赖容器负载预测的准确性, 目前相关研究面临数据集匮乏和已有预测方法不适应嵌入式应用特征等问题。面向航空机载嵌入式应用场景, 构建了符合嵌入式容器化环境的应用数据集; 针对负载预测精度和计算效率较低的问题, 提出结合了CEEMDAN算法和Informer模型的轻量级负载预测模型。CEEMDAN算法通过分解时间序列数据, 提升了建模的精度, 而Informer模型利用稀疏自注意力机制, 有效降低了计算复杂度和内存消耗。实验结果表明, 所提出的模型与主流时序预测方法对比, 各项误差指标平均下降约10%, 适合嵌入式应用场景。
Key words: embedded virtual containers / container cloud / load prediction / avionics software
关键字 : 嵌入式虚拟容器 / 容器云 / 负载预测 / 航空机载软件
© 2026 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
目前,国内学术界和工业界正在积极推动云原生理念与嵌入式系统的深度融合[1],通过技术创新和实践探索,丰富嵌入式系统的技术体系[2]。中航工业及下属研究机构对航空机载虚拟容器技术的探索也取得了积极进展。例如,中航工业计算所推出的容器版天脉3操作系统[3]支持应用软件的服务化架构和分布式部署,为航空机载应用提供了灵活与高效的管理能力。
在嵌入式环境中,基于容器的应用部署方式因其轻量化、可移植性和易于管理的特性,逐渐成为主流。容器应用[4]是指运行在容器中的各类嵌入式服务或任务,具有生命周期短、负载动态变化明显的特点。容器部署则是需要通过容器技术(如Docker)[5]将应用及其依赖打包并在嵌入式系统中运行。由于嵌入式设备的计算资源受限,容器应用的资源需求(如CPU、内存等)随着应用行为的变化而波动。因此,如何高效动态分配资源以适应不同需求,并提高资源利用率,成为关键问题。动态资源配置[6]是应对这一挑战的有效手段,而实现动态分配依赖于精准的资源负载预测[3]。通过预测未来负载趋势,可提前调整资源分配,确保负载和资源的匹配。容器资源负载预测本质上属于时序预测[7],但由于嵌入式环境中负载数据复杂性以及云计算领域内负载预测研究起步较晚,缺乏专用负载数据集,且嵌入式应用通常具备实时性、高安全性和资源受限等特征,已有的预测算法难以满足嵌入式环境下动态资源负载预测的特定需求。现有的研究多聚焦于迁移和改进通用时序预测算法,以及机器学习模型融合,旨在提高预测精度。
传统时间序列预测模型方面,如Roy等[8]提出的自回归平均移动模型(autoregressive moving average, ARMA),虽适用于平稳负载数据,但实际中负载受多种因素影响,往往呈现非平稳性。为此,Calheiros等[9]提出了差分整合移动平均自回归模型(autoregressive integrated moving average, ARIMA)以适应非平稳负载数据。混合模型方面,Sudhakar等[10]结合ARIMA与自回归神经网络进行实时资源负载预测,取得了较好的精度。Chen等[11]将长短期记忆网络(long short-term memory, LSTM)与极端梯度提升模型(extreme gradient boosting, XGBoost)相结合进行预测,而Nie等[12]则采用多目标灰狼算法(multi-objective grey wolf optimizer, MOGWO)对多个神经网络模型权重进行优化。Chen等[13]将时间卷积网络(temporal convolutional network,TCN)与全连接层和注意力机制结合。
这些研究多为迁移通用时序预测算法,当前许多基于深度学习的复杂模型虽然在处理多维度、高非线性数据时表现出了较高的预测精度,但其较高的计算复杂度和资源需求使其难以直接应用于嵌入式场景。而单一或简单组合模型对于复杂数据的预测效果有限,且未充分考虑实时性和资源受限等实际因素,导致预测方法难以适用于复杂的嵌入式云原生环境。
目前公开的嵌入式容器应用数据集较少,如基于边缘计算环境的EdgeBenchDatasetD与用于物联网设备的RIOTBenchmarkDataset,在样本规模与场景多样性方面均存在不足。为此,本文基于机载嵌入式环境构建了符合嵌入式云原生特征的容器应用数据集Acore-Data,并结合Alibaba-Cluster-Trace-Microservices-v2022的特征进行数据对比与优化,以支持负载建模与性能分析。
嵌入式云原生环境具有低延迟、高可靠性与强实时性要求,典型机载平台的CPU配额不超过1 C,内存容量约为512 MB~2 GB,预测响应需在200 ms以内。实时操作系统(real-time operating system, RTOS)因此成为关键支撑,以天脉3为代表的高性能RTOS通过任务调度、隔离机制与容器化支持,保证了多任务并发下的实时性与安全性,为嵌入式云原生研究提供了稳定实验平台。
因此,本文引入数据降维[14]和嵌入式环境特性,在减少计算开销的同时提高预测精度,提出基于完全集合经验模态分解与稀疏自注意力机制的轻量级负载预测模型(CEEMDAN-Informer),在有限算力条件下实现高精度、低延迟的预测,为嵌入式容器资源管理与调度提供有效支撑。
1 嵌入式云原生容器应用数据集构建
本文构建的嵌入式云原生容器应用数据集,充分考虑了嵌入式环境的特殊需求,特别是机载系统在资源和实时性方面的严格要求。数据集以云原生应用的数据属性和机载环境下的应用信息为构建原则,参考阿里巴巴、谷歌和华为等公司的公开容器应用数据集架构特征,设定合理的构建原则以确保数据的准确性、可靠性和完整性。参考Alibaba-Cluster-Trace-Microservices-v2022数据集中的数据信息,分析得到本文数据集所需的数据属性。以云原生应用的数据属性和机载环境下的应用信息为构建数据集的基本原则,着重考虑嵌入式系统的可靠性、安全性及资源受限等特征,为后续构建嵌入式云原生容器应用数据集提供了全面的指导基础和实际参考。嵌入式云原生容器应用数据集所需的数据属性如表 1所示。
嵌入式云原生应用数据属性
深入分析嵌入式云原生环境与通用云原生环境的异同。机载嵌入式系统常应用于飞行控制、导航、通信等关键任务中,对系统的可靠性、安全性和资源消耗有着较高要求。因此通过调研分析将任务关键型、数据处理型和通信传输型这3类应用的资源需求信息作为数据集的构建特征,应用的具体信息如表 2所示。
机载环境中的应用信息
在数据集构建过程中,依托飞腾D2000开发板搭载的天脉3操作系统,设计符合嵌入式环境的数据采集方式,并建立高效的存储结构,确保数据来源的真实性与可靠性。飞腾D2000开发板作为国产高性能嵌入式平台,具备强大的计算能力和丰富的接口扩展,而天脉3操作系统提供完善的安全机制、实时响应能力和全面的系统服务,确保了嵌入式应用的安全性、稳定性和高效性。容器通过天脉容器编排系统进行部署,在3类典型机载云原生应用中,每类运行3个实例,每个实例运行3个副本,采集间隔设置为1 s,调用编排系统的API。基于前文所述的数据原则,获取机器信息、容器运行时间、容器名称以及容器CPU、内存等资源的实时使用情况,并实时获取负载信息,最终将这些数据本地存储。
在数据清洗环节,针对数据缺失和冗余问题进行了有效处理。原始数据集包含约50万条容器负载信息,由于容器数据冗杂,分析特定容器负载变化存在困难。为便于分析特定容器的负载变化,按Pod名称将数据分为多个子数据集。由于同一时间戳下可能存在多条重复记录,仅保留每个时间戳的第一条数据。对于容器负载数据中的缺失值,采用了三次指数平滑法进行填补。三次指数平滑法的基本思想是通过历史数据的加权平均计算缺失值,其原理是将时间序列分解为多个部分,根据历史数据与当前数据的距离分配权重,权重随着距离增大呈指数级衰减,并最终趋近零。由于容器资源负载数据的变化幅度较大,平滑系数取值为0.7。
该方法具有较强的适应性,能够根据数据变化自动调整,因此对负载时序数据有较好的填补效果。此外,三次指数平滑法计算简便,其递归特性使得数据填补反需维护极少量的状态参数,有效节省存储空间和处理时间。基于上文中的数据原则,app1-c2-flightsim-uqj47x52qx-ujifo数据集包括机器信息、容器的运行时间、容器名称以及容器CPU、内存等资源的实时使用情况。以其子数据集中的CPU利用率数据为例,基于指数平滑法的填补效果如图 1所示,红色点表示填补计算的结果。可见,提出的缺失数据处理方法能够较好地完成对容器资源负载数据的平滑处理。
 |
图1 基于指数平滑法的缺失值处理 |
最终,本文构建了符合嵌入式需求的3类典型机载云原生应用数据,共包含9个应用实例和27个实时负载数据集,平均每个数据集约有1.8万条样本点,覆盖高、中、低负载阶段的典型特征。实验结果表明,当训练样本减少至30%时,预测误差仅上升约4%,说明该数据规模足以支撑模型训练与验证。
为评估Acore-Data数据集的质量与代表性,本文从完整性、一致性和多样性3个方面进行了分析。完整性方面,采用1 s采样周期与多副本冗余机制,数据缺失率低于0.5%,时序连续性达99.8%;经三次指数平滑填补后,噪声占比降低约15%。一致性方面,利用重复检测与3σ异常剔除法清洗数据,重复率控制在1%以内,保证样本可靠性。多样性方面,数据覆盖任务关键型、数据处理型和通信传输型3类负载,分别代表计算密集、存储密集与通信密集任务,其CPU与内存利用率方差显著(标准差>0.3),体现良好的负载差异性。
综上,Acore-Data数据集具备较高的真实性、稳定性和代表性,可为嵌入式容器负载预测研究提供可靠支撑。后续将进一步扩展至工业控制、车载计算与边缘物联网等场景,以增强数据集的普适性。
2 负载预测模型
在嵌入式容器化应用中,受限的计算资源、实时性要求和复杂多变的负载特性使得精准的负载预测成为挑战。为了解决这一问题,本文在Acore-Data数据集基础上提出了基于信号分解的轻量级负载预测模型,模型架构如图 2所示。该架构设计充分结合了CEEMDAN与Informer模型各自的优势。
 |
图2 CEEMDAN-Informer模型架构图 |
CEEMDAN作为一种优化的信号分解算法,能够将非线性、高复杂度的原始负载数据分解为若干相对平稳、复杂度更低的分量,使得数据中的潜在模式和局部趋势更加清晰,从而为后续的预测提供更具信息量和代表性的输入特征。Informer模型则针对传统Transformer模型在长序列时序预测中的性能瓶颈,提出了基于概率的多头稀疏自注意力机制、蒸馏自注意力机制和并行生成预测序列的优化设计,显著降低了计算复杂度和内存消耗,并有效避免误差积累问题。这使得Informer模型能够在资源受限的嵌入式环境中快速生成高精度预测序列。
CEEMDAN-Informer负载预测模型不仅能够充分挖掘负载数据的深层特征,还能在资源受限的嵌入式场景中实现高效、低延迟的预测,为容器资源调度和系统优化提供了可靠支持,有效提升了嵌入式应用的资源利用率和系统稳定性。
在数据预处理阶段,首先对原始数据进行归一化处理,接着应用CEEMDAN算法对数据进行模态分解。CEEMDAN是一种有效的信号分解方法,它将原始信号分解为多个本征模态函数(IMFs)和一个残差项(Res),从而提取信号中的不同频率成分并去除噪声干扰。通过这种方式,CEEMDAN将复杂信号分解为多个简单成分,使每个IMF分量代表数据中不同的周期性特征,残差项则表示低频趋势。经过分解后,噪声成分被有效去除,为后续预测任务提供更加清晰且有规律的输入。
CEEMDAN算法是对经验模态分解(EMD)的改进,通过引入自适应噪声和迭代过程,解决了模态混叠和端点效应问题。CEEMDAN算法的详细实现步骤如下:
1) 添加高斯白噪声。在初始信号序列x(t)中加入高斯白噪声σ0ωi(t),形成新的信号序列xi(t), i=(1, 2, …, n), 如(1)式所示。
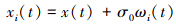 (1)
(1)
式中: i表示加入高斯白噪声的次数; σ为噪声标准差, 与噪声相乘以调整噪声的强度; ωi(t)为第i次添加的高斯白噪声信号。
2) 多次重构。对带有噪声的新信号序列xi(t)进行多次随机重构,每次重构都可能得到不同的信号结果,如进行N次得到N个重构信号序列。
3) EMD分解。对N次重构得到的信号序列进行EMD分解,每次分解都可能得到不同的IMF,至此共得到了N个IMF分量。
4) 取平均。对这N个分量进行取平均操作,得到最终的第一个模态分量IMF1(t),如(2)式所示。
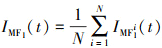 (2)
(2)
5) 残差处理。将最终的IMF1(t)与初始信号序列x1(t)相减,得到第一个残差R1(t),如(3)式所示。
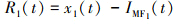 (3)
(3)
6) 重复迭代。将残差作为新的初始信号序列,不断重复步骤1)~5),持续得到IMFs分量和残差余量。设经过n次迭代后,残差不可以再被分解,至此完成了对初始信号序列的分解,如(4)式所示。
 (4)
(4)
在负载预测阶段,CEEMDAN分解得到的各个本征模态函数(IMFs)和残差项(Res)将作为输入特征提供给Informer预测模型。Informer是一种基于自注意力机制的高效时序预测模型,特别适用于处理长序列数据,并能够捕捉数据中的长期依赖关系。与传统的时序预测模型相比,Informer通过其稀疏自注意力机制有效降低计算复杂度,在处理大规模数据时仍能保持高效性。Informer模型首先使用基于概率的多头稀疏自注意力机制(probsparse self-attention),然后在不同自注意力层之间融入蒸馏自注意力机制(self-attention distilling),最后采用解码器(decoder)架构并行生成预测序列(one forward operation)。
具体实现流程如图 3所示,该图清晰展示了数据预处理、模态分解、预测输入以及最终预测结果生成的全过程。
 |
图3 CEEMDAN-Informer模型的算法流程 |
在本模型中,IMFs分量和残差项作为输入,Informer模型通过学习这些输入,能够捕捉负载数据中的周期性波动和潜在趋势,从而进行准确的负载预测。最终,通过累加操作,将各个IMFs分量和残差项的预测结果结合起来,得到最终的负载预测值。此累加过程将预测结果从各个频率成分重建为原始数据的全局预测值。整个预测过程将分解与重建相结合,能够更加精确地捕捉负载数据的变化趋势,并有效减少噪声对预测结果的影响。
3 嵌入式云原生容器负载预测实验
对于嵌入式云原生容器负载预测实验,为衡量模型的预测精确度,本文选择了3种在预测实验中最常被使用的评估指标,即平均绝对误差(mean absolute error, MAE)、均方误差(mean squared error, MSE)和均方根误差(root mean squared error, RMSE),用于评价负载预测效果。由于Acore-Data数据集中的容器数量庞大,为了突出实验的核心和重点,本次实验结果仅对容器app1-c2-flightsim-uqj47x52qx-ujifo的相关数据进行介绍和分析。在实际环境中,集群的性能通常受CPU资源、内存资源、磁盘吞吐率和网络带宽的影响,而在嵌入式云原生环境中磁盘吞吐率和网络带宽对集群的影响较低,为提高核心因素的效果,本文的负载预测仅基于CPU和内存资源。同时,使用文献[13]中层次分析法的CPU与内存比例,计算得到权重向量W =(0.666 6, 0.333 4)T,以此对数据进行降维,根据(5)式计算出负载评价度量值Lt,代表t时刻的负载值。
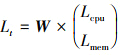 (5)
(5)
式中,Lcpu和Lmem分别代表t时刻CPU利用率和内存利用率进行归一化处理之后的值。
为验证该指标的合理性与有效性,进行了对比实验。结果表明,Lt相较于CPU和内存单项指标的变化更加平滑,能更准确地反映系统整体资源利用率。采用Lt作为统一输入后,CEEMDAN-Informer模型的MAE、MSE及RMSE分别降低约1.3%, 2.8%, 2.0%, 且与CPU、内存利用率的Pearson相关系数分别为0.93和0.87。说明该负载度量方法在提高预测精度的同时降低了特征维度,具有良好的代表性与实用性。
本次实验按4∶1比例将数据集划分为训练集和测试集。使用(5)式对容器app1-c2-flightsim-uqj47x52qx-ujifo的测试集进行负载计算,计算所得结果如图 4所示。
 |
图4 app1-c2-flightsim-uqj47x52qx-ujifo负载数据图 |
3.1 有效性实验
为了验证CEEMDAN-Informer模型的有效性,本文进行了有效性实验。对所有分量的预测结果进行重构,从而得到CEEMDAN-Informer的最终预测结果,如图 5所示。
 |
图5 CEEMDAN-Informer预测结果 |
观察图 5可见,CEEMDAN-Informer的拟合曲线与初始曲线十分贴近,表明CEEMDAN-Informer在嵌入式云原生数据集上有良好的预测效果,在损失率方面也有良好表现,具体如表 3所示。表 3中记录了6个IMF特征分量和残差分量Res的损失率合并后IMFs的损失率。
损失率结果
3.2 对比实验
为验证CEEMDAN-Informer模型在预测精度方面的优越性,本文设计对比实验,引入TCN、Transformer、LSTM-XGBoost[11]和MOGWO[15]4种典型模型进行比较。其中,TCN采用因果卷积结构以保持时间依赖顺序; Transformer利用自注意力机制高效捕获长距离依赖;LSTM-XGBoost结合了LSTM的时序特征提取与XGBoost的回归优势;MOGWO通过多目标灰狼优化在全局与局部搜索间取得平衡。
在进行容器资源负载预测时,预测步长对后续部署优化方案的设计具有重要影响。因此,本文针对不同步长进行了实验,将步长分别设置为4, 8, 16和32,以验证模型在不同步长条件下的预测效果。同时,为了确保实验的严谨性,对比模型尽可能采用了与CEEMDAN-Informer一致的全局变量和参数设置,若网络结构无法完全实现,则根据经验法进行调优,以找到最佳的参数组合。为了证明本文提出的预测方法在嵌入式云原生容器负载预测领域具有较高的准确度和适用性,本节设计了多种对比实验。同时,为了保证实验结果的有效性和可靠性,所有预测模型的输入都是Acore-Data数据集。如图 6所示,可以看出当预测步长分别为4, 8, 16, 32时,CEEMDAN-Informer的预测性能指标均明显优于其他模型,说明该模型在多步预测方面具有更高的精度。
 |
图6 对比试验预测结果 |
如表 4所示,分析对比实验的实验结果后发现本文提出的CEEMDAN-Informer负载预测模型的预测效果最好。
对比实验结果
如表 4所示,分析对比实验结果后发现本文提出的CEEMDAN-Informer负载预测模型预测效果最好。与TCN模型相比,CEEMDAN-Informer的预测精度更高,当预测步长分别为4, 8, 16, 32时,MAE分别降低了4.3%, 4.1%, 6.4%, 9.3%,MSE分别降低了30.1%, 24.1%, 20.5%, 23.1%,RMSE分别降低了16.4%, 12.9%, 10.8%, 12.3%。与Transformer模型相比,CEEMDAN-Informer的预测精度更高,当预测步长分别为4, 8, 16, 32时,MAE分别降低了7.3%, 6.1%, 2.6%, 11.8%,MSE分别降低了26.0%, 16.0%, 9.5%, 10.1%,RMSE分别降低了14.0%, 8.4%, 4.9%, 5.2%。与CEEMDAN-CNN模型相比,CEEMDAN-Informer的预测精度更高,当预测步长分别为4, 8, 16, 32时,MAE分别降低了19.4%, 14.6%, 10.8%, 14.5%,MSE分别降低了43.4%, 32.9%, 21.7%, 14.8%,RMSE分别降低了13.9%, 14.9%, 10.8%, 7.7%。与MOGWO模型相比,CEEMDAN-Informer的预测精度更高,当预测步长分别为4, 8, 16, 32时,MAE分别降低了15.5%, 7.8%, 11.2%, 8.2%,MSE分别降低了29.0%, 24.4%, 17.3%, 19.9%,RMSE分别降低了15.7%, 13.1%, 9.1%, 10.5%。
具体来看,在时序数据预测中,网络模型结构是否适配数据集的特点对预测精度具有重要影响。在大多数情况下,常见的时序预测网络模型如TCN、CEEMDAN-CNN和MOGWO,通常是较为合适的选择,尽管可能存在一定的精度偏差,但整体上仍能表现出良好的预测性能。但是TCN、CEEMDAN-CNN和MOGWO对较长的时间序列的预测能力较弱,表现出一定的局限性,尤其是随着序列跨度的增大,其预测能力显著下降。相比之下,对于Transformer模型而言,其与Informer模型有着相似的架构,对于长序列的预测能力较强,然而,随着序列长度的进一步增加,Transformer的预测能力也会逐渐减弱。不论是TCN、CEEMDAN-CNN、MOGWO还是Transfor-mer,它们的预测效果都不如通过CEEMDAN信号分解算法对数据进行降维处理后再预测的效果好。这表明,先利用CEEMDAN对数据进行分解以提取关键分量,然后结合Informer模型进行预测的策略,可以有效提升预测精度。本文提出的CEEMDAN-Informer模型验证了这一点,其预测结果显著优于单一模型方法,进一步证明了该方法在提高长序列预测精度方面的可行性与有效性。
通过对不同预测步长(4, 8, 16, 32)下的结果比较可知(见表 4和图 6),随预测步长增加,所有模型MAE、MSE和RMSE均呈上升趋势,说明负载序列在长时间跨度下的不确定性更高。相比之下,CEEMDAN-Informer模型在全尺度表现优异:步长为32的MAE(4.5707)优于部分模型步长为4的表现。特别是在16, 32步长区间,其MAE增幅(6.1%)远低于Transformer(17.3%), 展现出更强的长序预测稳定性。其优势来源于CEEMDAN的信号去噪能力与Informer稀疏自注意力对远程依赖的高效建模。
此外,为评估模型在嵌入式平台中的适应性,本文进一步统计了其计算资源占用与推理延迟。实验结果显示,CEEMDAN-Informer在飞腾D2000平台上运行时平均CPU占用率低于28%,单步预测延迟约180 ms,能耗较Transformer降低22%。由此可见,该模型在保证预测精度的同时具备良好的实时性与能效,适用于资源受限的嵌入式环境。
3.3 极端资源受限条件下的性能实验
为验证CEEMDAN-Informer模型在极端资源受限环境下的适应性,本文在飞腾D2000平台上利用cgroups限制CPU配额和内存上限,设置R0(1.0 C/2048 MB)、R1(0.5 C/1024 MB)、R2(0.25 C/512 MB)和R3(0.125 C/256 MB)4种资源配置。在各配置下,对3类典型嵌入式负载(任务关键型、数据处理型、通信传输型)进行测试,并与Transformer、TCN和CEEMDAN-CNN模型对比。
实验结果表明,随着资源限制增强,所有模型的预测精度均有所下降,但CEEMDAN-Informer的MAE与RMSE增长最小。在R3极端条件下,模型MAE仍保持4.71、RMSE为6.08,较Transformer分别降低约11%和9%,单步预测延迟178 ms,截止期违约率(DMR)仅0.7%,满足200 ms实时性要求。资源消耗方面,平均CPU占用27%,峰值内存480 MB,比Transformer低约25%,单次预测能耗减少22%。在预测-调度闭环实验中,系统CPU与内存利用率分别提升12%和15%,服务等级协议(SLA)违约率下降18%。
综上,CEEMDAN-Informer模型在负载预测精度、实时性及能效方面均表现优异,能在极端资源受限的嵌入式环境中稳定运行,具备良好的工程可部署性。
4 结论
现有通用容器部署方案难以应对嵌入式云原生环境中负载的复杂性与实时性需求。针对当前缺乏高质量嵌入式容器应用数据集的现状,本文以航空机载为典型场景,基于天脉3操作系统与飞腾D2000平台,构建了机载嵌入式基础环境,并完成了Acore-Data数据集的采集与清洗,为相关研究提供了真实、可用的数据支撑。
在此基础上,本文提出了一种结合CEEMDAN与Informer的轻量级负载预测模型,兼顾预测精度、实时性与资源约束,在嵌入式云原生环境中表现出良好的适应性和实用性,为后续的资源管理与容器调度提供了有效支撑。
References
- LiS, XuL D, ZhaoS. The internet of things: a survey[J]. Information Systems Frontiers, 2015, 17: 243–259. [Article] [CrossRef] [Google Scholar]
- MarwedelP. Embedded system design: embedded systems foundations of cyber-physical systems, and the internet of things[M]. New York: Kluwer Academic Publishing, 2021: 21–22 [Google Scholar]
- ZhangFeng, YangYuetao, GaoWeilin, et al. Design and implementation of miniaturized low-power airborne display graphic systemTelecommunication Engineering, 2022, 62(6): 813–819 (in Chinese) [Google Scholar]
- LiYang, MiaoZhangwang. Development and challenges of the cloud computing industry in the digital economy era[J]. Digital Economy, 2023(S2): 78–83 (in Chinese) [Google Scholar]
- GannonD, BargaR, SundaresanN. Cloud-native applications[J]. IEEE Cloud Computing, 2017, 4(5): 16–21. [Article] [Google Scholar]
- XuShengchao, XiongMaohua. Resource allocation optimization of container cloud based on genetic algorithm[J]. Computer and Modernization, 2022, 1(1): 108–112 (in Chinese) [Google Scholar]
- Liang Ronghua. Research on elastic scaling strategy of container cloud based on resource load prediction[D]. Guilin: Guilin University of Technology, 2022. (in Chinese) [Google Scholar]
- Roy N, Dubey A, Gokhale A. Efficient autoscaling in the cloud using predictive models for workload forecasting[C]//2011 IEEE 4th International Conference on Cloud Computing, New York, 2011: 500–507. [Google Scholar]
- CalheirosR N, MasoumiE, RanjanR, et al. Workload prediction using ARIMA model and its impact on cloud applications′ QoS[J]. IEEE Trans on Cloud Computing, 2014, 3(4): 449–458 [Google Scholar]
- Sudhakar C, Kumar A R, Siddartha N, et al. Workload prediction using ARIMA statistical model and long short-term memory recurrent neural networks[C]//2018 International Conference on Computing, Power and Communication Technologies, New York, 2018: 600–604. [Google Scholar]
- ChenZ, LiuJ, LiC, et al. Ultra short-term power load forecasting based on combined LSTM-XGBoost model[J]. Power System Technology, 2020, 44(2): 614–620 [Google Scholar]
- NieY, JiangP, ZhangH. A novel hybrid model based on combined preprocessing rnethod and advanced optimization algorithm for power load forecasting[J]. Applied Soft Computing, 2020, 97: 1068089–106811 [Google Scholar]
- Chen W, Lu C, Ye K, et al. RPTCN: resource prediction for high-dynamic workloads in clouds based on deep learning[C]//2021 IEEE International Conference on Cluster Computing, Portland, 2021: 59–69 [Google Scholar]
- JiaW, SunM, LianJ, et al. Feature dimensionality reduction: a review[J]. Complex & Intelligent Systems, 2022, 8(3): 2663–2693 [Google Scholar]
- LiangQiang, XuYonghang, LiYongliang, et al. Multi-objective optimization of laser polishing process parameters for 45# steel surface based on MOGWO[J]. Surface Technology, 2024, 53(10): 173–182 (in Chinese) [Google Scholar]
All Tables
All Figures
|
图1 基于指数平滑法的缺失值处理 |
| In the text | |
|
图2 CEEMDAN-Informer模型架构图 |
| In the text | |
|
图3 CEEMDAN-Informer模型的算法流程 |
| In the text | |
|
图4 app1-c2-flightsim-uqj47x52qx-ujifo负载数据图 |
| In the text | |
|
图5 CEEMDAN-Informer预测结果 |
| In the text | |
|
图6 对比试验预测结果 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.