| Issue |
JNWPU
Volume 37, Number 2, April 2019
|
|
|---|---|---|
| Page(s) | 407 - 416 | |
| DOI | https://doi.org/10.1051/jnwpu/20193720407 | |
| Published online | 05 August 2019 | |
Group Formation Basd on SATC-ALO and SOM Neural Network
基于SATC-ALO和SOM神经网络的机群编队分组
1
Air Traffic Control and Narigation College Force Engineering University, Xi’an 710038, China
2
959939 PLA Troops, Cangzhou 0617136, China
Received:
26
January
2018
Abstract
Firstly, the problem of group-air grouping is analyzed to introduce the aircraft attribute grouping model and aircraft fuel consumption grouping model. Then, SATC-ALO optimized by Chaos optimization algorithm and Tournament Selection strategy and SOM neural network are used to solve the formation grouping model. Finally, comparative experiments of similarity calculation method and formation grouping method were performed with 50 groups of data. The experimental results show that hybrid method is superior to Euclidean distance method. SATC-ALO algorithm has the highest grouping accuracyand meets the real-time requirements. However, the number of groups needs to be specified in advance. The accuracy of SOM neural network grouping is slightly lower than SATC-ALO algorithm, but the grouping time is lower than SATC-ALO algorithm, and there is no need to specify the number of groups. Both SOM neural network and SATC-ALO algorithm can perfectly solve the problem of group-air grouping and have practical application value.
摘要
首先,分析机群编队分组问题,同时考虑了飞机属性分组模型和飞机油耗分组模型。然后,使用混沌优化算法和锦标赛选择策略优化后的SATC-ALO算法和SOM神经网络求解编队分组模型。最后,使用50组数据进行相似度计算方法和编队分组方法对比实验。实验结果表明,混合计算法方法优于欧式距离法,SATC-ALO算法分组精度最高,并且满足实时性要求,但需要事先指定分组数目,而SOM神经网络的分组精度稍低于SATC-ALO算法,但分组时间优于SATC-ALO算法,并且不需要指定分组数目。2种方法均可以更好地解决编队分组问题,具有实际应用价值。
Key words: group-air grouping / hybrid calculating method / self-adaptive tent chaos search ant lion optimizer algorithm(SATC-ALO) / self organizing maps network(SOM)
关键字 : 机群编队分组 / 混合计算方法 / 自适应Tent混沌搜索蚁狮优化算法(SATC-ALO) / SOM神经网络
© 2019 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
机群编队分组是将类型相似、数据相近且来源于多传感器的空战目标信息进行可靠有效的分组。在信息化作战条件下,空战目标类型和数量日益增多,战场态势瞬息万变,指挥员和飞行人员需要在时间异常紧迫的情况下迅速做出决定,然而大量的战场信息极大地影响了遂行战斗任务的质量。机群编队分组可以提高信息辨识度,解决信息炫目问题的同时有助于指挥员和飞行人员快速把握空战态势,从而做出正确决策。因此,研究机群编队分组问题具有重要意义。
近几年,国内外学者对编队分组问题进行了较深入的研究,不断提升编队分组方法的可靠性。其中,Blackman等[1]首次提出使用聚类的方法实现机群编队分组。之后,虽然聚类方法不断被优化,但仍存在需要预先给定聚类数目[2]、手动输入阈值[3-4]、无法满足实时性[5]等问题。除了聚类方法,Schubert等[6-7]提出D-S证据理论和构建模板相结合的方法,但存在不易建立准确率较高的模板问题;蔡益朝[8]使用遗传算法搜索编队分组最优解,但出现分组结果不稳定的问题;李伟生等[9]应用模糊理论解决目标编群问题,实时性较高,但由于考虑因素较少,分组准确性受到影响。
针对以上问题,首先,在分析机群编队分组问题的基础上,提出了编队分组模型,确定了用于判断编队分组情况的飞机属性,并使用混合计算方法计算目标间的相似度。之后,提出了2种方法求解分组模型,一种是自适应Tent混沌搜索的蚁狮优化算法(self-adaptive tent chaos search ant lion optimizer algorithm, SATC-ALO),即使用Tent混沌搜索[10]、锦标赛选择策略[11]和Logistic混沌搜索[12]改进蚁狮优化算法。另一种是SOM(self organizing map)神经网络[13],通过自学习对飞机编队进行分组,并使用CV值评估分组结果。实验结果表明,SATC-ALO算法和SOM神经网络均具有很好的分组精度,具有实际应用价值。
1 机群编队分组模型建立
1.1 分组问题分析
在信息化战争中,歼击机若想成功完成任务,取得空战的胜利,组成若干个编队协同作战是关键。战术战斗机突击编队通常编有:突击编队、空空掩护编队(直接掩护编队,必要时还需要间接掩护编队)、佯动编队和地面防空兵器压制编队。面对这种新的编队作战方式,我方指挥人员和飞行员只有在战场中实时掌握敌方空中编队分组情况和分布态势,才能清晰地了解空战态势,以便及时做出正确决定。
作为意图识别过程的一个关键部分,机群编队分组通过获取敌方飞机的属性数据,从战略战术角度将类型相似、属性相近的空战目标进行有效分组。其意义在于为指挥员和飞行人员提供:①空战目标态势和属性;②敌方飞机编队分组情况;③编队协同作战方式;④作战意图。
机群编队分组是一个逐层推理的过程,根据获取的敌方飞行数据,采取有效的方法自底向上逐层抽象,实现对机群编队的划分。机群编队分组主要分为4个层次,如图 1所示[9]:
目标对象:作战飞机,包括歼击机、直升机、运输机、预警机和干扰机等。
空间群:类型相似、位置相近的一群飞机。
相互作用群:执行相同任务的空间群,如2个编队协同完成攻击地面目标的任务。
敌/我/中立方群:根据相互作用群的国籍等因素划分成的3个阵营。
研究机群编队分组需要层层推理,从空战目标到空间群,最后得到相互作用群和敌/我/中立群。本文在获取空战目标数据的基础上,寻求一种可以快速准确得到空间群的方式。
 |
图1 编队分组抽象层次 |
1.2 分组问题模型
1.2.1 飞机属性分组模型
为了描述编队分组问题,使用一维向量代表飞机,向量中的元素代表飞机属性。主要包括:
1) 飞机敌我属性A;飞机的敌我属性是区分飞机是否在同一编队中的前提。
2) 飞机类型T;不同类型飞机完成的任务类型一般不同, 所处的编队也不同。比如, 直升机一般用于实施火力支援, 进行空中侦察和运输; 电子战飞机用于压制敌方火力系统, 配合我方突击部队。
3) 飞机航向θ;同一编队飞机的航向一般不会相差太大, 并且航向往往体现整个编队的作战意图。
4) 飞机位置{x, y, z};同一编队飞机的空间位置比较接近, 以便于形成突击队形或者搜索队形等形式。
5) 飞机速度v;同一编队飞机为了保持一定的队形, 飞机间速度应在一定的范围内。
6) 飞机间通信C;飞机间和编队间的协同需要长机和僚机之间以及长机之间互相通信, 如果可以获得敌方通信信息, 将有助于进行编队分组。但在大多数条件下无法获取通信信息。
由上可知, 每架飞机可以用以上6种属性表示, 数学描述为:
 (1)
(1)
 (2)
(2)
式中, S表示空中所有飞机属性集合; Pi表示第i架飞机的属性集合。
1.2.2 飞机油耗分组模型
飞机油耗一般与飞行性能、飞行距离和飞行环境等因素相关。由于同一编队的飞机性能、飞行距离和飞行环境大致相同, 油耗相差不大, 而不同编队的飞行环境和飞行距离等一般不同, 导致油耗相差较大。因此, 为了获取准确的分组结果, 在编队分组模型中, 考虑了飞机油耗要素。第i架飞机油耗Mi表达式为
 (3)
(3)
式中,wi为第i架飞机的油耗代价, 主要与飞机性能和飞行环境等因素有关。L为航迹长度。当第i架飞机以某一速度飞行时, Mi与L成正比, 因此, 为了简化油耗模型, Mi可以表示为
 (4)
(4)
1.3 目标相似度计算
为了对机群编队进行分组, 在综合考虑飞机多种属性的基础上, 尝试使用混合计算方法计算飞机间的相似度。
由于飞机属性既包含连续值, 如飞机位置、速度、航向等指标, 又包含离散值, 如飞机类型、敌我属性等指标。因此, 不能简单地使用马氏距离和欧式距离等方法计算, 需要分别处理连续值和离散值。
为了避免不同属性间数量级和物理意义的差异对分群结果造成影响, 在计算距离之前需要进行归一化处理。飞机相似度的定义为
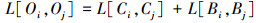 (5)
(5)
式中, L[Oi, Oj]表示飞机i和j之间的相似度值, L[Ci, Cj]表示连续属性的相似度值, L[Bi, Bj]表示离散属性的相似度值。考虑到飞机的不同属性在不同情况下对相似度值的贡献度是不同的, 需要确定不同属性的权值。因此, 结合专家意见, 使用层次分分析法(analytic hierarchy process, AHP)确定不同属性的权值[6]。具体定义如下:
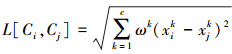 (6)
(6)
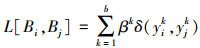 (7)
(7)
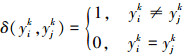 (8)
(8)
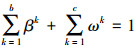 (9)
(9)
式中, ωk表示连续属性的权值, xik表示连续属性值, βk表示离散属性的权值, yik表示离散属性值。
2 自适应Tent混沌搜索的蚁狮优化算法
蚁狮优化算法是2015年由澳大利亚学者Seyedali提出的一种新的群智能优化算法, 它具有调节参数少, 全局搜索能力强、收敛速度快和易实现等优点[14]。但在寻优进化过程中, 算法也存在一些不足, 比如:算法初期的轮盘赌搜索方法影响种群的寻优性能和收敛速度; 在迭代过程中, 蚂蚁可能向适应度较差的个体进行学习, 使算法陷入局部最优, 影响算法效率; 算法后期接近全局最优时, 种群多样性随搜索步长和搜索速度的下降而减少, 从而导致算法易陷入局部最优值。针对上述类似问题, 主要进行以下改进。
2.1 Tent混沌序列
Tent混沌变量具有随机性、遍历均匀性和规律性等优势[10], 利用其进行优化搜索, 可以提高种群多样性, 并使算法跳出局部最优。因此, 使用Tent混沌序列初始化蚂蚁和蚁狮种群。
Tent映射表达式如下
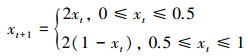 (10)
(10)
经过贝努力移位变换后为
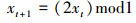 (11)
(11)
在可行域中产生Tent混沌序列的步骤如下:
步骤1 产生(0, 1)之间的随机数x0作为初值(避免x0在小周期内(0.2, 0.4, 0.6, 0.8)), z(1)=x0, i=j=1;
步骤2 根据(8)式迭代, 生成x(i+1), i=i+1;
步骤3 若x(i)={0, 0.25, 0.5, 0.75}, 或x(i)=x(i-k), k={0, 1, 2, 3, 4}, 则按x(i)=z(j+1)=z(j)+ε改变迭代初值, ε为随机数, j=j+1, 否则转向步骤2;
步骤4 若达到最大迭代次数, 程序结束, 保持x序列, 否则转到步骤2。
2.2 自适应Tent混沌搜索
使用自适应动态调整混沌搜索策略为适应度较差的蚂蚁和蚁狮个体产生适应度较好的新解, 以改善种群的整体性能。即在每一次迭代中, 分别求出种群第j维的最小值Xminj和最大值Xmaxj作为混沌搜索空间, 以目前为止搜索到最优值为基础产生Tent混沌序列。主要步骤如下:
步骤1 xk归一化处理:
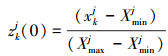 (12)
(12)
式中, k=1, …, n, j=1, …, D。
步骤2 利用(8)式产生混沌序列zkj(m), 并利用(11)式将zkj(m)还原到解空间的邻域内:
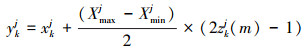 (13)
(13)
步骤3 计算新的适应度值, 并与原来的值进行比较, 保留更好的解;
步骤4 若达到最大迭代次数, 程序结束, 否则转到步骤2。
2.3 锦标赛选择方法
基本ALO算法使用轮盘赌法将适应度值占总适应度值的比例作为选择概率选出被学习的蚁狮, 使得整个蚂蚁进化过程向适应度高的蚁狮群体集中, 破坏了种群多样性, 使算法出现早熟收敛, 陷入局部最优值。锦标赛选择机制[11]是基于局部竞争机制产生的, 即随机选取q个个体进行比较, 从中选取适应度值较大者作为最优个体。本文采用锦标赛选择策略选取被学习的蚁狮个体, 并取q=2。在每次选取的过程中, 奖励适应度值大的1分, 重复n次, 其中得分最高的权重也最大。由于锦标赛选择策略将适应度的相对值作为选择标准, 并且未对适应度值正负做要求, 进而避免了超级个体对进化过程的影响。适应度选择概率为
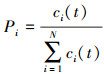 (14)
(14)
式中, ci为每个个体得分。
2.4 Logistic混沌搜索
将典型的Logistic混沌算子与蚂蚁的随机游走结合成混沌蚁群, 使蚂蚁能够进行混沌搜索, 提高了算法跳出局部最优解的能力。混沌变量数学表达式为[12]
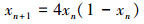 (15)
(15)
式中, xn是0到1之间的一个随机数。
经过以上改进, 可以将混沌蚂蚁的全局探索能力和蚁狮的局部寻优能力结合, 改善了算法的全局寻优速度和精度。
2.5 自适应Tent混沌搜索的蚁狮算法流程
算法的步骤如下:
步骤1 设置参数:蚁狮算法的最大迭代次数Imax、蚂蚁和蚁狮的数目Na和Nav、适应度函数维数d、变量范围u和l以及混沌策略的最大迭代次数m;
步骤2 在搜索区范围内, 利用Tent混沌序列初始化蚂蚁和蚁狮种群, 分别生成Na和Nal个d维向量Xi, I=1;
1) 随机产生Na和Nal个(0, 1)之间d维向量ZiD(t), 根据2.1节Tent混沌映射步骤可以得相应的混沌序列ZiD(t);
2) 利用(14)式将ZiD(t)载波到对应变量的取值范围内, 即
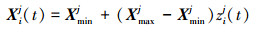
步骤3 利用自适应Tent混沌搜索为种群中适应度较差蚂蚁和蚁狮产生新解;
1) 设置参数:种群中较差个体比例p0, 选出的个数为p0×N, Tent混沌搜索次数为n;
2) 按照2.2节介绍的自适应动态调整混沌搜索空间方法为p0×N个个体产生新解。
步骤4 计算Xi的适应度值并排序, 从中选出适应度值最大的蚁狮作为精英蚁狮个体;
步骤5 通过锦标赛选择方式对蚁狮进行选择, 并更新cit和dit的值;
步骤6 将典型的Logistic混沌算子与蚂蚁的随机游走结合成混沌蚁群, 使蚂蚁能够进行混沌搜索;
步骤7 游走后的蚂蚁与当前位置最好的蚁狮对比, 重新调整最佳蚁狮的位置。如果蚁狮的位置超出了最远边界u或者l, 则按照最远边界处理, I=I+1;
步骤8 判断是否达到算法的最大迭代次数, 如果满足这个条件, 则输出最佳蚁狮位置, 否则转至步骤3。
3 机群编队分组模型
为了对机群编队进行分组, 主要选取2种方法:改进的群智能算法SATC-ALO和SOM神经网络, 以提升机群编队分组的准确性和效率。
3.1 基于SATC-ALO的机群编队分组模型
飞机属性分组模型使用编组内飞机之间的平均距离和编组之间的平均距离的比值作为评价指标, 表达式如下
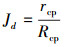 (16)
(16)
式中, rcp表示编组内飞机之间的平均距离, Rcp表示编组之间的平均距离。
飞行油耗模型使用编队内飞机油耗的标准差的平均值与编队间飞机油耗标准差的比值作为评价指标, 其中, 每个编队的油耗使用编队内飞机油耗平均值, 表达式如下
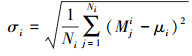 (17)
(17)
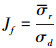 (18)
(18)
式中, Ni表示第i个编组内飞机数目, Mji表示第i个编组第j架飞机油耗, μi表示第i个编组油耗平均值, σi表示第i个编组内飞机油耗的标准差, σr表示编组内飞机油耗标准差的平均值, σd表示编队间飞机油耗标准差。
机群编队分组评价指标表达示为
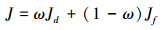 (19)
(19)
式中, ω表示飞机属性分组模型的权值, 因为飞机属性和油耗对于机群编队分组都很重要, ω取0.5。
因此, 选取(19)式作为SATC-ALO适应度值计算公式, 使用SATC-ALO解决机群编队分组问题的流程如图 2所示:
在图 2中, 编队分组数目c∈[2, n/2], n表示飞机数量。蚂蚁和蚁狮个体为c×l维矩阵, l表示飞机属性。
 |
图2 编队分组算法流程图 |
3.2 基于SOM神经网络的机群编队分组模型
SOM神经网络于1995年由Kohonen[13]提出, 是一种非监督神经网络。在训练过程中, SOM神经网络不需要人为干预和预先了解数据特征便能够获得输入数据的规律性和变量间关系, 并根据输入数据特点来组织自身结构。因此, SOM神经网络适合解决分类数目未知的编队分组问题, 结构图如图 3所示。
SOM神经网络可以将高偏差和非线性的高维数据空间映射到一维或是二维的拓扑结构中, 以便相似的数据向量在映射图中能够相邻。竞争层中每一个神经元都通过一个邻居关系纽带与毗邻的神经元相连, 神经元之间的连接关系如图 4所示。
在训练过程中, 每次随机抽取输入向量X, 并计算X与SOM竞争层神经元的权值向量的欧式距离。其中, 距离最近的神经元被称为最佳匹配单元(best matching unit, BMU)。BMU及其附近神经元的权值向量会向输入向量X调整。因此, 具有相似属性的输入量被分到同一类。训练过程中的分类结果如图 5所示。
SOM算法的步骤为:
步骤1 初始化竞争层的权值向量;
步骤2 标准化输入向量;
步骤3 确定BMU。计算输入向量和权值向量之间的距离, 确定与输入向量最接近的神经元为BMU。
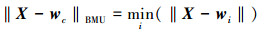 (20)
(20)
式中,wc表示BMU的权值向量。
步骤4 确定BMU的附近神经元;
步骤5 根据(21)式更新BMU和其附近神经元的权重向量;
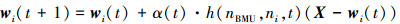 (21)
(21)
式中, h(nBMU, ni, t)表示临近函数, α(t)表示学习率, 0 < α(t) < 1。
步骤6 判断是否达到最大迭代次数, 如果达到, 结束训练; 否则, 返回步骤2。
SOM神经网络的训练流程图如图 6所示。
训练之后, SOM神经元会被聚成几类, 形成一种新的拓扑结构。当测试向量输入到SOM神经网络中时, 通过比较测试向量和BMU权值向量间的距离, 可以衡量输入向量与标准状态间的差距。因此, 可以定义最小量化误差(minimum quantization error, MQE):
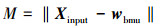 (22)
(22)
式中, Xinput表示输入数据向量, wbmu表示BMU的权值向量。
训练程度可以通过MQE量化和可视化。但是是一个确定的指数, 没有一个相对的指数, 很难确定目前的训练情况。为了能够简洁地反映当前的训练程度, 提出了0~1范围内的标准化置信度值(confidence value, CV), CV的表达式如下
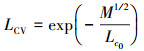 (23)
(23)
式中, Lc0=-M01/2/lnCV0, M0表示标准状态下的MQE, Lc0表示初始LCV值, 一般取0.6, LCV在0~1之间[14]。
根据SOM神经网络学习规则, 目前状态特征与标准状态特征越相似, MQE值越小, CV值越大。当下降或者发生错误分组, 对应的MQE值越高, CV值越小, 由于CV值的相对性, 使用CV值判断编队是否发生错误分组。
SOM神经网络机群编队分组流程如图 7所示:
 |
图3 SOM神经网络映射关系图 |
 |
图4 SOM神经元连接图 |
 |
图5 神经元分类图 |
 |
图6 SOM神经网络训练流程图 |
 |
图7 SOM神经网络映射关系图 |
4 仿真实验
实验仿真的硬件环境为具有12 Inter Xeon(R) E5 CPU和4GB RAM的高性能处理器, 软件平台为MATLAB2012和Google公司最新研发的tensorflow深度学习算法库。
4.1 数据预处理
战机运行环境的多变性以及吊舱数据接收的不稳定性和误差性, 使得飞行数据具有坏值和噪声。因此, 在进行机群编队分组之前, 需要对数据进行清洗。主要步骤如下:
1) 剔除异常值
孤立森林算法是一种基于非参量法和无监督学习的异常值检测算法, 能够快速准确地处理大量数据, 尤其适用于大数据环境。并且孤立森林算法性能优于ORCA[15]、LOF和随机森林。因此, 选取孤立森林算法检测飞行数据中的异常值。
2) 坐标系转换
为了定量分析战机间的相对态势, 将GPS获得的WGS-84大地坐标系转化为我国国家坐标系。
3) 归一化处理
为了保持数据范围的统一性, 对数据进行归一化处理
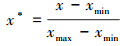 (24)
(24)
作战想定数据是结合实际战场情况想定的数据, 为了验证SATC-ALO算法和SOM神经网络的有效性, 参考实际装备作战实验原则和性能参数, 使用50组作战想定数据集进行实验验证, 共1 547组数据。由于缺少不同飞机的飞行参数以及航迹长度数据, 无法计算不同类型飞机的油耗代价, 在实验仿真时不考虑油耗因素。其中一组典型数据如图 8和表 1所示。
由图 8可知, 敌方分机大致分成5个编队和1架预警机, 其中, 第1编队主要执行低空突防任务, 破坏敌方防空武器, 为第6编队对地轰炸作准备, 第2编队和第4编队从两侧出发, 目的是掩护轰炸机编队安全返航, 并接应第1编队, 第5编队主要执行反潜任务, 预警机主要为所有飞机提供信息和引导。
具体的作战数据如表 1所示。
在表 1中, 类型1表示隐身战斗机, 类型2表示战斗机, 类型3表示预警机, 类型4表示直升机, 类型5表示轰炸机。
 |
图8 作战想定的通用作战图 |
作战想定数据
4.2 SATC-ALO算法分组实验
使用MATLAB2012实现SATC-ALO算法, 设置初始编队数目为2, 编队数目上限为10, 蚂蚁和蚁狮的种群规模为10, 最大迭代次数为100, 搜索维度D为6。实验结果如图 9~11所示。
由图 9可知, 当编队数目达到6时, 适应度函数最优。由图 10可知, 当编队数目为6时, SATC-ALO算法在迭代30次左右基本收敛至适应度最优值, 虽然在迭代第4次和第14次时陷入局部最优, 但经过自适应调整, 使算法跳出局部最优点, 适应度值能够进一步优化, 最终收敛速度和精度均优于ALO算法和ABC算法。当迭代至40次左右, ALO算法和ABC算法的适应度值基本不变, 无法跳出局部最优点, 陷入早熟收敛。由此可以看出, SATC-ALO算法具有较好的全局搜索能力, 可以快速准确地对机群编队进行分组。由图 11可知, SATC-ALO编队分组情况与实际结果一致, 说明SATC-ALO算法在编队分组问题上具有实际应用价值, 准确度较高。
 |
图9 不同编队数目最优适应度值对比 |
 |
图10 编队数目为6的适应度函数曲线 |
 |
图11 编队分组情况 |
4.3 SOM神经网络分组实验
本文使用Tensorflow实现SOM神经网络, 设置输入层神经元个数为6, 竞争层为4×4个神经元组成的平面阵列, 迭代次数为10次。为了提升运算效率, 使用单层SOM神经网络进行训练。训练结果如图 12~图 13所示。
图 12为可视化竞争层的神经元向量, 有助于分析分类编组情况。由图 13可知, 除了第13个点的CV值偏低以外, 其余点的CV值正常, 说明SOM神经网络训练较好, 只有1个点可能是异常分类。下一步结合分类结果进行具体分析, 编队分组结果如图 14所示, 其中纵坐标对应的是BMU的分类。
由图 14可知, 19架飞机共分成6类, 其中一类只有1架飞机(预警机), 即CV值异常的飞机。与图 8相比, SOM神经网络的分类结果与实际编队情况完全一致, 说明该方法可以快速准确地对编队进行编组。同时, 经过分析, CV值异常的飞机为预警机, 起到为其他编队在后方提供信息支援的作用, 在空间上和类型上都与其他编队相差较大。因此, 将其单独编成一类。由此说明SOM神经网络分类准确, 同时CV值起到很好的辅助分析作用。编队分组的三维态势图如图 15所示。
 |
图12 SOM神经元向量可视化 |
 |
图13 分组CV值 |
 |
图14 SOM编队分组结果 |
 |
图15 编队分组三维态势图 |
4.4 对比实验
4.4.1 相似度计算方法对比
分别使用混合计算方法和欧式距离法计算飞机间的相似度, 使用SATC-ALO算法进行分组, 分组结果如表 2所示:
由表 2可知, 混合计算方法的正确率高于欧式距离方法, 2种距离计算方法的运算时间均满足实时性条件。因此, 在进行集群编队分组时, 采用混合计算方法计算飞机间相似度。
距离算法分组结果对比表
4.4.2 分组方法对比
使用混合计算方法计算飞机间相似度值, 分别使用k-means、SOM神经网络、蜂群算法(artificial bee colony, ABC)、ALO算法和SATC-ALO算法4种方法进行50组实验, 分组结果如表 3所示:
由表 3可知,SATC-ALO算法的正确率是所有算法中最高的,并且运算时间满足实时性条件;而SOM神经网络的准确性稍低于SATC-ALO算法,但运行时间优于SATC-ALO算法,因为SATC-ALO无法确定具体的分组数目,需要多次改变分组数目,降低了运算效率。改进后的蚁狮算法和SOM神经网络均可以较好地解决机群编队分组问题,而k-means算法虽然运行时间最短,但准确性较低,无法应用于此问题,ABC算法和ALO算法性能稍弱于SATC-ALO算法和SOM神经网络。
在实际作战时,如果事先知道敌方分组数目,可以使用准确率相对较高的SATC-ALO算法,如果对敌方意图完全不知,建议使用准确度和速度占优的SOM神经网络。也可以结合2种算法的优势,先使用SOM神经网络确定分组数目,然后使用SATC-ALO算法确定具体的分组情况。
分组算法结果对比表
5 结论
本文使用SATC-ALO和SOM神经网络2种方法解决机群编队分组问题。主要创新点为:①使用混合计算方法计算飞机间相似度,替代欧氏距离方法,提升机群编队分组的准确度;②使用Tent混沌序列、自适应Tent混沌搜索、锦标赛选择策略和Logistic混沌序列改进蚁狮优化算法,优化算法的收敛速度和精度,避免算法早熟收敛和陷入局部最优解;③使用CV值评价SOM神经网络的分组准确性,便于提前发现分组错误;④分别尝试使用SATC-ALO群智能算法和SOM神经网络无监督学习方法解决编队分组问题,为后面解决类似分组问题提供了新的思路。
实验结果表明,在收敛速度和精度方面,SATC-ALO优于ALO,多次改变分组数目降低了其编队分组问题运算效率,但准确率较高,可以用于已知敌方编队分组数目的情况或战后评估。SOM神经网络在CV的辅助分析作用下,可以快速准确地对机群编队进行分组。因此,本文提出的2种算法均具有实际应用价值。
References
- Blackman S S, Popoli R. Design and Analysis of Modern Tracking Systems. Artech House, Dedham, 1999 [Google Scholar]
- Zhang Fen, Jia Ze, Sheng Jiagen, et al. Research for Object Clustering in Situation Assessment Electronics Optics & Control, 2008, 15(4): 21–23 (in Chinese) [Article] [Google Scholar]
- Bi Peng. Study on Application of Improved Chameleon Hierarchical Clustering Algorithm in Target Clustering[D]. Hangzhou, Zhejaing University, 2009 (in Chinese) [Google Scholar]
- Qi Linghui, Zhang An, Cao Lu. Double Centroids-Weighted Support Vector Clustering Algorithm for Group-Air Grouping Systems Engineering and Electronics, 2014, 36(11): 2213–2218 (in Chinese) [Article] [Google Scholar]
- Yuan Deping, Zheng Juanyi, Shi Haoshan. Target Grouping Algorithm Based on Multiple Combat Formations Computer Science, 2016, 43(2): 235–238 (in Chinese) [Article] [Google Scholar]
- Schubert J. Reliable Force Aggregation Using a Refined Evidence Specification from Dempster-Shafer Clustering[C]//Proceeding of the 4th Annual Conference on Information Fusion Montreal, Canada, 2012 [Google Scholar]
- Cantwell J, Schubert J, Walter J. Conflict-Based Force Aggregation[C]//Proceeding of the 6th International Command and Control Research and Technology Symposium. Annapolis, USA, 2009 [Google Scholar]
- Cai Yichao. Reseach on Foree Aggregation Technology inm Situation Assessment[D]. Changsha, National University of Defense Technology, 2006 (in Chinese) [Google Scholar]
- Li Weisheng, Wang Baoshu. Target Classification Method for Situation Assessment Based on Fuzzy Sets System Engineering and Electronics, 2005, 27(7): 1235–1237 (in Chinese) [Article] [Google Scholar]
- Kuang Fangjun, Jin Zhong, Xu Weihong, et al. Hybridization Algorithm of Tecnt Chaos Artificial Bee Colony and Particle Swarm Optimization Control Theory & Applications, 2015, 30(5): 839–846 (in Chinese) [Article] [Google Scholar]
- Bao L, Zeng J C. Comparison and Analysis of the Selection Mechanism in the Artificial Bee Colony Algorithm[C]//The 9th International Conference on Hybrid Intelligent Systems, Los Alamitos, CA, 2009: 411–416 [Google Scholar]
- Gao W F, Liu S Y. A Modified Artificial Bee Colony Algorithm[J]. Computer & Operations Research, 2012, 39(3): 687–697 [Article] [CrossRef] [Google Scholar]
- Kohonen T. Self-Organizing Maps[J]. Springer Series in Information Science, 1995, 13(2): 47–55 [Article] [Google Scholar]
- Mirjalili S. The Ant Lion Optimizer[J]. Advances in Engineering Software, 2015, 83(9): 80–98 [Article] [CrossRef] [Google Scholar]
- Bay Sd, Schwabacher M. Mining Distance-Based Outliers in Near Linear Time with Randomization and a Simple Pruning Rule[C]//Proceedings of the 9th ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, New York, 2003 [Google Scholar]
All Tables
All Figures
|
图1 编队分组抽象层次 |
| In the text | |
|
图2 编队分组算法流程图 |
| In the text | |
|
图3 SOM神经网络映射关系图 |
| In the text | |
|
图4 SOM神经元连接图 |
| In the text | |
|
图5 神经元分类图 |
| In the text | |
|
图6 SOM神经网络训练流程图 |
| In the text | |
|
图7 SOM神经网络映射关系图 |
| In the text | |
|
图8 作战想定的通用作战图 |
| In the text | |
|
图9 不同编队数目最优适应度值对比 |
| In the text | |
|
图10 编队数目为6的适应度函数曲线 |
| In the text | |
|
图11 编队分组情况 |
| In the text | |
|
图12 SOM神经元向量可视化 |
| In the text | |
|
图13 分组CV值 |
| In the text | |
|
图14 SOM编队分组结果 |
| In the text | |
|
图15 编队分组三维态势图 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.