| Issue |
JNWPU
Volume 37, Number 3, June 2019
|
|
|---|---|---|
| Page(s) | 465 - 470 | |
| DOI | https://doi.org/10.1051/jnwpu/20193730465 | |
| Published online | 20 September 2019 | |
Classification of Few Labeled Images Based on Integrated GMM Clustering
基于集成GMM聚类的少标记样本图像分类
1
School of Astronautics, Northwestern Polytechnical University, Xi’an, 710072, China
2
Air Defense Academy, Air Force Engineering University, Xi'an 710043, China
Received:
4
April
2018
Abstract
In order to improve the classifier classification accuracy of by using convolutional neural network training, a large amount of labeled data is often required, but sometimes labeled data is not easily obtained.This paper proposes a solution based on the idea of integrated GMM clustering and label delivery for classifying images with few labeled samples, assigning tags to unlabeled data through certain rules, and converting unlabeled data into labeled data for training of the model.In this paper, experiments are performed on hand-written digital recognition data sets. The results show that the present algorithm has a great improvement in the accuracy of model classification comparing with the method of using only labeled samples in the case of few labeled samples. The effectiveness of the present algorithm is validated.
摘要
为了提高卷积神经网络训练的分类器分类准确率,往往需要大量的已标记数据,但有时已标记数据并不容易获得。针对少标记样本图像分类问题,提出基于集成GMM聚类与标签传递思想的解决方案,通过一定的规则给未标记数据赋予标签,将未标记数据转换成已标记数据用于模型的训练。在手写数字识别数据集上进行实验,结果表明新算法在少标记样本的情况下,结合集成GMM聚类的方法比只采用有标记样本训练得到的模型分类准确率有着较大提高,验证了该算法的有效性。
Key words: integrated GMM clustering / few labeled samples / voting rules
关键字 : 集成GMM聚类 / 少标记样本 / 投票规则
© 2019 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
自从2012年神经网络之父亨特及其学生使用深度学习技术搭建AlexNet在Image Net比赛中取得比传统方法高出许多的准确率之后[1], 深度学习技术开始得到人们广泛关注并在图像分类、语音识别、自然语言处理中取得了很好的效果[2-4]。卷积神经网络训练出的模型也具有很好的泛化能力。然而, 卷积神经网络要想有较高的准确率及较好的泛化能力, 往往需要大量的已标记样本用于训练, 人工标记样本往往涉及到成本问题, 这对于那些已标记样本数据过少的领域就提出了一定的挑战。随着互联网技术及移动互联网技术的不断发展, 当前我们往往可以通过网络获取到大量的数据, 与此同时, 在许多的应用场景中, 我们还面临着虽然有着大量的数据, 但其中已标记数据占比过少的问题, 以遥感目标检测与识别为例, 可以较为轻松地从谷歌地球等网站获取大量的遥感图像, 但其中有标记的图像占比较小, 这不利于使用深度学习方法去训练模型。因此, 如何充分利用大量的未标记样本与少量的已标记样本去共同训练模型是我们所关心的问题[5]。
有一种利用未标记数据去训练模型的思路是这样的:利用已标记数据与未标记数据的相似度, 对未标记的数据添加标签, 从而获得大量的有标签数据去训练模型。聚类算法往往就是根据数据的相似度实现数据的聚类, 这就使得通过数据聚类再加上一定的赋予标签规则利用未标记数据成为了可能。高斯混合模型(GMM)[6-7]是一种聚类算法, 模型假设观测数据来自于K个m维的高斯分布, 其中K为数据分类的类别数目, m为数据的特征数目。与常用的K均值算法相比, GMM假设的模型分布一般与数据的真实分布更加一致。文献[8]提出基于集成聚类的分类架构并取得了较好的效果, 但是并未给出如何将集成聚类思想应用于解决少标记样本分类问题的方法。本文将结合集成GMM聚类算法与标签传递思想, 提出一种用于解决少标记样本图像分类问题的理论框架, 更好地利用未标记的数据训练网络。
1 基于GMM与标签传递的少标记样本图像分类实现方案
1.1 方案总体框架
本文结合无监督聚类算法与标签传递的思想对未标记数据添加标签, 然后将这些拥有标签的数据用于训练分类器, 方案的总体框架如下:
1) 采用GMM对少标记样本的特征数据进行聚类, 无标签数据与有标签数据都会被用于聚类。
2) 基于标签传递的思想, 确定给无标签数据赋予标签的规则, 采用投票表决的方式对无标签数据赋予标签。
3) 将获得的大量的有标签数据用于训练分类器。
4) 对得到的分类器进行评估。
1.2 EM(期望最大化)算法对GMM进行参数估计
假设观测数据y1, y2, …, yN由高斯混合模型生成
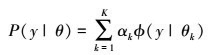 1
1
式中, θ=(α1, α2, …, αK; θ1, θ2, …, θk), 使用EM算法估计高斯混合模型的参数θ。
1) 明确隐变量, 写出完全数据的对数似然函数
可以设想观测数据yj, j=1, 2, …, N, 是这样产生的:首先依概率αk选择第k个高斯分布模型; 然后依第k个高斯分布模型的概率分布ϕ(y|θk)生成观测数据yj, 这时观测数据yj, j=1, 2, …, N, 是已知的; 反映观测数据yj来自第k个分模型的数据是未知的, 以隐变量γjk表示, 其定义如(2)式所示
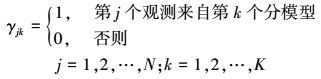 2
2
有了观测数据yj及未观测数据γjk, 那么完全数据是
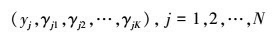
于是, 可以写出完全数据的似然函数如(3)式所示
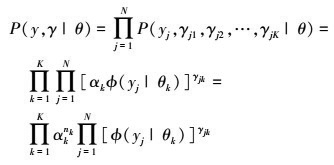 3
3
式中,  。
。
2) EM算法的E步:确定Q函数
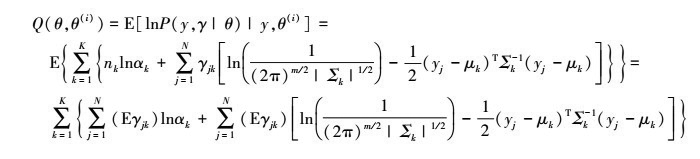 4
4
这里需要计算E(γjk|y, θ), 记为 。由贝叶斯公式, 有
。由贝叶斯公式, 有
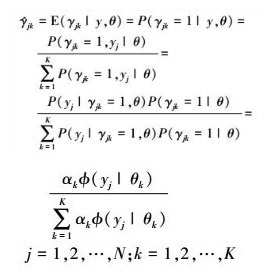 5
5
 是在当前模型参数下第j个观测数据来自第k个分模型的概率, 称为分模型k对观测数据yj的响应度。
是在当前模型参数下第j个观测数据来自第k个分模型的概率, 称为分模型k对观测数据yj的响应度。
将 及
及 代入(5)式可得
代入(5)式可得
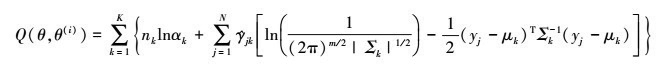 6
6
3) 确定EM算法的M步
迭代的M步是求Q函数对θ的极大值, 即求新一轮迭代的模型参数
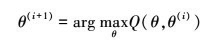 7
7
用 , 表示θ(i+1)的各参数。求
, 表示θ(i+1)的各参数。求 只需要将(6)式分别对μk, Σk求偏导数并令其为0即可得到; 求
只需要将(6)式分别对μk, Σk求偏导数并令其为0即可得到; 求 是在
是在 条件下求偏导数并令其为0得到的。参数更新的公式如(8)式所示。
条件下求偏导数并令其为0得到的。参数更新的公式如(8)式所示。
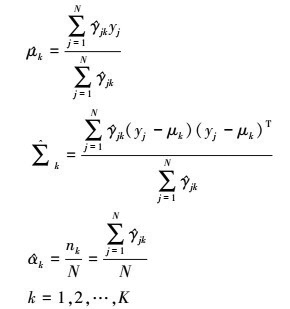 8
8
重复计算E步及M步, 直到对数似然函数值不再有明显变化为止。
1.3 基于标签传递思想的投票规则确定
由于CNN模型的训练需要大量的已标记样本, 因此在少标记样本分类器的训练过程中需要想办法把未标记数据利用起来, 也就是需要给出未标记样本赋予标签的规则。标签传递思想假设拥有类似特征的数据有着相同的标签, 本文基于标签传递的思想, 结合GMM聚类结果, 采用投票表决的方式赋予未标记样本标签。
因为GMM聚类的结果是服从同一个高斯分布的数据聚为一类, 因此可以合理地假设同一类数据有着相同的标签。接下来的问题就是如何给某一类数据赋予标签。本文提出2种投票表决的思路。
思路一 经过GMM聚类之后, 依次在每个类别中查看已标记样本类别标签的比例, 将这一类的标签赋为已标记样本类别标签比例最大的那个标签。以有着少量已标记样本手写数字识别为例, 将聚类的结果编号为1~10, 如果1号类别中的已标记样本类别标签比例最大的标签为5, 那么就将1号类别中的未标记数据标签赋为5。思路一的示意图如图 1所示。
思路二 经过GMM聚类之后, 利用聚好类的模型依次对每一类已标记样本的类别标签进行预测, 可以得到预测类别占比最大的类别编号, 将占比最大的类别编号中的未标记数据赋为本次进行预测的类别标签。以有着少量已标记样本手写数字识别为例, 将聚类的结果编号为1~10, 对已标记样本的0~9分别进行预测, 如果已标记样本中有着标签0的数据预测类别占比最大的类别编号是5, 那么就将聚类结果编号为5的数据标签赋为0。思路二的示意图如图 2所示。
思路一与思路二的比较:由于思路一的判断规则是依次在每个类别中查看已标记样本类别标签的比例, 将这一类的标签赋为已标记样本类别标签比例最大的那个标签, 因此如果已标记样本的标签分布不均时会造成算法的适应性较差。仍以手写数字识别为例, 如果已标记样本中数字5的数量过多, 有可能会出现数字5在多个聚类结果上都是已标记样本中占比最大的从而把多个聚类结果的数据都赋为5的情况。为了解决这个问题, 应当要求已标记样本类别标签分布应是大致均衡的。思路二则不会出现思路一的问题, 算法的适应性要好于思路一, 此外, 思路二也比思路一更加易于实现, 因此, 本文采用思路二确定的投票规则对未标记数据赋予标签。
由于GMM算法易受初始条件的影响, 算法的稳定性不好。为了解决这一问题, 本文采用集成的思想, 综合多个GMM的聚类结果对未标记数据赋予标签, 只有多个GMM的聚类结果中赋予标签的那个众数在GMM总数的占比超过一定阈值时才将对应的数据及标签加入到训练数据集。例如, 采用3个GMM集成聚类, 依据投票规则确定标签, 可以设定只有当2个及以上GMM模型确定的标签为同一值时才将这个数据及对应标签加入到训练集。此外, 为了使集成的结果有利于分类准确率的提高, 应该保证每一个GMM对有标记数据的预测标签准确率大于50%, 本文实验中将这一数值设为60%。
 |
图1 思路一示意图 |
 |
图2 思路二示意图 |
2 实验及结果
2.1 实验数据及评价指标
本文的实验数据集采用python的机器学习工具包sklearn中自带的手写数字集digists, digists数据集采集了43人的手写数字, 共包含1 797个0~9的数字, 每个数字由8*8的矩阵构成, 矩阵中的元素取值范围是0~16, 代表图像的灰度值。
本文以分类器的分类准确率作为评价指标。
2.2 实验流程
1) 将数据集打乱顺序, 形成新的数据集, 以便多次进行验证实验。
2) 将数据集分为训练数据集与测试数据集, 本文中选取打乱顺序之后的新数据集的前1 500个样本作为训练数据集, 后297个样本作为测试数据集。
3) 将训练数据分为有标记数据与无标记数据。
4) 利用集成GMM聚类并结合投票规则对无标记数据赋予标签, 并将有标记数据作为训练数据集1, 将有标记数据与赋予了标签的无标记数据合并为训练数据集2。
5) 将训练数据集1与训练数据集2分别经过具有相同结构的CNN进行分类器的训练, 并对测试集进行分类, 对二者的分类准确率进行比较研究。
本文采用的CNN结构示意图如图 3所示。示意图中C表示卷积层, S表示池化层, F表示全连接层。卷积层的滤波器尺寸为3*3, 在卷积层之后有着激活函数, 本文激活函数均采用ReLU方法, 池化层的滤波器尺寸为2*2, 采用最大值池化。为了避免训练过程中模型的过拟合, 全连接层与输出层之间的连接采用一定比例的随机失活, 本文中的实验随机失活比例设为0.5。本文的损失函数为交叉熵。
 |
图3 本文CNN结构示意图 |
2.3 实验结果及分析
实验一 本次实验选取3个GMM模型作为基聚类器, 当3个基聚类器中有2个及以上依据投票规则对未标记数据赋予的标签相同时, 将这个未标记数据及其被赋予标签的众数作为训练数据添加到训练集中。将有标记样本的数目设置为样本类别数目10的3, 5, 8, 10, 30倍, 分别对只用有标记样本训练和结合集成GMM聚类训练的CNN分类器进行了多次训练, 并对平均准确率进行比较, 实验结果如图 4所示。
实验二 本次实验选取5个GMM模型作为基聚类器, 当5个基聚类器中有4个及以上依据投票规则对未标记数据赋予的标签相同时, 将这个未标记数据及其被赋予标签的众数作为训练数据添加到训练集中。将有标记样本的数目设置为样本类别数目10的3, 5, 8, 10, 30倍, 分别对只用有标记样本训练和结合集成GMM聚类训练的CNN分类器进行了多次训练, 并对平均准确率进行比较, 实验结果如图 5所示。
整体的实验结果如表 1所示。
实验结果分析:从实验结果可以看出, 在有标记样本数目较少时, 结合集成GMM聚类训练得到的分类器要比只用少量有标记数据训练得到的分类器分类准确率有着较大提高, 说明本文提出的用于解决少标记样本图像分类方案的有效性。随着有标记样本数目的提高, 只用有标记样本训练的分类器分类准确率不断提高, 而结合集成GMM聚类所训练的分类器分类准确率则变化不大。当有标记样本数目超过一定值之后, 只用有标记样本训练的分类器分类准确率要高于结合集成GMM聚类所训练的分类器分类准确率, 这是因为GMM算法本身有一定的聚类误差, 当将赋予标签有误的样本作为训练样本时, 导致分类器学到了噪声从而使分类准确率降低。对比实验一与实验二, 通过增加基聚类器数目确实可以增加分类准确率, 但提升效果并不明显。
 |
图4 3个GMM集成准确率对比图 |
 |
图5 5个GMM集成准确率对比图 |
不同方式训练的分类器准确率
3 结论
本文基于集成GMM聚类及标签传递的思想, 提出了用于解决少标记样本图像分类的解决框架, 经过实验验证了在有标记样本数目较少时, 结合集成GMM聚类比只用少量的已标记数据训练分类器得到的分类准确率有了较大的提升。本文一开始想要解决少量标记样本图像分类问题时想到了用聚类的方法去辅助分类, 但没有认识到GMM聚类算法虽然相对而言聚类效果不错, 但聚类结果也存在不稳定的问题, 之后想到可以用集成的思想去减小聚类误差, 经过实验集成聚类的效果确实更加稳定与有效。从实验结果可知, 聚类的准确率对分类器的训练有着较大影响, 因此, 论文以后的研究重点将放在:(1)探索提高聚类效果的方法, 例如将遗传算法用于GMM参数的获取(2)探索如何将已知信息引入到聚类的过程中, 实现有监督聚类的有效途径(3)在更加困难的数据集上进行算法有效性的测试。
References
- KrizhevskyA, SutskeverI, HintonG E. ImageNet Classification with Deep Convolutional Neural Networks[J]. Advances in Neural Information Processing Systems, 2012, 25(2): 1097-1105 [Article] [Google Scholar]
- LuoFan, WangHoufeng. The Chinese Text Sentiment Classification Combined with RNN and CNN Hierarchical Networks[J]. Journal of Peking University, 2018, 54(3)L 459-465 (in Chinese) [Article] [Google Scholar]
- Qian Cheng. Research on Face Recognition Based on Deep Learning[D]. Chengdu, Southwest Jiaotong University, 2017 (in Chinese) [Google Scholar]
- DaiLirong, ZhangShiliang, HuangZhiying. The Present Situation and Prospect of Deep Recognition Based Speech Recognition Technology[J]. Data Acquisition and Processing, 2017, 32(2): 221-231 [Article] [Google Scholar]
- CaiYi, ZhuXiufang, SunZhangli, et al. An Overview of Semi-Supervised Integrated Learning[J]. Computer Science, 2017, 44 [Article] [Google Scholar]
- Stauffer C, Grimson W E. Adaptive Background Mixture Models for Real-Time Tracking[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 1999: 246-252 [Google Scholar]
- Shi Qianyu. Research on Integrated Clustering Algorithm for Complex Data[D]. Taiyuan, Shanxi University, 2017(in Chinese) [Google Scholar]
- LuGang, YuXiangzhan, ZhangHongli, et al. Flow Classification Architecture Based on Integrated Clustering[J]. Journal of Software, 2016, 27(11): 2870-2883 [Article] [Google Scholar]
- XiongBiao, JiangWanshou, LiLelin. Remote Sensing Image Semi-Supervised Classification Based on Gaussian Mixture Model[J]. Engineering Journal of Wuhan University, 2011, 36(1): 108-112 [Article] [Google Scholar]
- LiHang. Statistical Learning Method[M]. Beijing, Tsinghua University Press, 2012 [Google Scholar]
All Tables
All Figures
|
图1 思路一示意图 |
| In the text | |
|
图2 思路二示意图 |
| In the text | |
|
图3 本文CNN结构示意图 |
| In the text | |
|
图4 3个GMM集成准确率对比图 |
| In the text | |
|
图5 5个GMM集成准确率对比图 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.