| Issue |
JNWPU
Volume 37, Number 5, October 2019
|
|
|---|---|---|
| Page(s) | 1070 - 1076 | |
| DOI | https://doi.org/10.1051/jnwpu/20193751070 | |
| Published online | 14 January 2020 | |
Person Re-Identification Net of Spindle Net Fusing Facial Feature
融合面部特征的Spindle Net行人重识别网络
1
School of Computer Science and Technology, Changchun University of Science and Technology, Changchun 130022, China
2
School of Artificial Intelligence, Changchun University of Science and Technology, Changchun 130022, China
Received:
8
October
2018
Abstract
In the field of person re-identification, the extraction of pedestrian features is mainly focused on the extraction of features from the whole pedestrian or limb torso, and the facial features are less used. The facial features is integrated into the network to enhance pedestrian recognition accuracy rate. By introducing the MTCNN facial extraction network in the framework of person re-identification network Spindle Net, and improves the accuracy of person re-identification by improving the weight of facial features in the overall pedestrian characteristics. The experimental results show that the accuracy of Rank-1 on the CUHK01, CUHK03, VIPeR, PRID, i-LIDS, and 3DPeS data sets is 7% higher than that of Spindle Net.
摘要
目前在行人重识别 (person re-identification) 领域对行人特征的提取主要集中在整体行人或肢体躯干分别提取特征 较少使用面部特征。将面部特征融入到网络中以提高行人重识别的准确率。在行人重识别网络 Spindle Net 的框架中引入 MTCNN面部提取网络,通过提高面部特征在整体行人特征中的权重来提高行人重识别的准确率。实验结果表明,文中提出的网络相比于 Spindle Net 在CUHK01,CUHK03,VIPeR,PRID,i-LIDS,3DPeS数据集上Rank-1的准确率平均提升7%。
Key words: person re-identification / facial / convolutional neural network
关键字 : 行人重识别 / 面部 / 卷积神经网络
© 2019 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0
), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0
), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
行人重识别(person re-identification)是指将出现在视角不重叠的多个摄像机下的特定行人进行查找匹配。行人重识别一般存在如下几类难题:不同摄像机视角会产生目标位姿变化、目标相互遮挡、不同行人之间相似度极高难以区分等。对行人重识别的研究始于多相机跟踪[1]。Gheissari等[2]通过研究分析获得不同摄像机中行人外貌的基本稳定区域, 提取稳定区域中的颜色特征和边缘特征, 采用三角模型匹配不同行人图像的距离来判断是否为同一行人。Weinberger等[3]提出了最大近邻分类间隔(LMNN)的思想, 该方法与支持向量机方法类似即同类之间类内紧缩、类外间隔尽可能大。中山大学Zheng等[4]首次将尺度学习算法融入行人重识别问题中, 提出基于概率相对距离比较的距离度量学习算法。Li等[5]定义了几种不同的衣服属性, 将局部现行判别分析方法用于行人重识别技术。
随着行人重识别技术的发展, 对整张行人图像的全局特征提取和使用遇到了瓶颈, 对局部特征的提取和使用应运而生, 主要的思路有将图像分割成几个区域、利用骨架信息来提取人体的关键点等。Varior等[6]将行人水平方向分割成7个区域放入LSTM网络中训练提取其各区域的特征, 再将这7个局部特征进行融合。Zheng等[7]使用姿态估计模型得到人体的14个关键点, 然后通过仿射变换将相同的关键点对齐。Zhao等[8]旨在将人体而不是人的图像框分割成网格或条纹, 以改变人的图像框中不同人体空间分布, Wei等[9]提出的方法与Spindle Net[10]基本相同, 唯一不同的是该论文对分割的不同区域分别计算损失, 而Spindle Net是整体计算损失。
基于上述情况, 本文使用Spindle Net这种能很好处理不同摄像头下行人位姿变化和遮挡问题的行人重识别方法, 提出一种改进的将面部特征加入特征提取和特征融合网络中的方法, 并且将面部放在特征融合阶段的后期以提高面部所占比重。本文将MTCNN[11]网络融入到Spindle Net中, MTCNN主要是提取人的面部区域, 其准确率可以达到95%。
1 网络结构
本文是将面部特征融入到Spindle Net中, 因此我们将此网络称为FS Net, FS Net主要分为3个部分:区域提取网络、特征提取网络与特征融合网络。网络框架流程图如图 1所示, 区域提取网络中CPM(convolutional pose machines)[12]通过骨架将行人分割成7个区域, MTCNN(multi-task cascaded convolutional networks)用于提取行人的面部。将行人的图像、7个区域和面部作为特征提取网络的输入, 分别提取各自的特征, 进而得到9个256维特征。将这9个特征作为特征融合网络的输入, 逐步进行特征融合, 最终得到一个能表征行人的256维特征。虚线框为本文主要贡献。
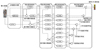 |
图 1 FS网络流程图 |
1.1 区域提取网络
为了便于说明, 本文将MTCNN与CPM放入区域提取网络中。该网络将人体分为8个区域, 其中CPM将行人分为7个区域, MTCNN负责提取行人的面部, 在区域提取网络中MTCCN与CPM同时进行(如图 2所示)。
本文使用CPM而未采用Spindle Net中的骨架提取网络RPN, 是由于虽然RPN是在CPM的基础上进行了网络的精简, 加快算法运行速度, 但如表 1所示, 通过本文所使用的数据集验证, CPM骨架提取的准确率要高于RPN, 至于算法时间复杂度问题, 我们计划在下一步的工作中, 放在整体的算法框架下综合考虑。
CPM是一种基于串行化的全卷积网络结构, 通过使用卷积层来学习纹理信息和空间信息, 以此来进行人体姿态估计, 这种串行化主要体现在网络的多阶段性, 结构如图 3所示。
CPM主要分为4个阶段, 在第一个阶段中将原始图像作为输入, 通过一个基础的卷积网络预测每个部件的响应, 该网络共包含7个卷积层和3个池化层, 输出大小为46×46×15(14个身体部件与1个背景)的信度图; 第二阶段也将原始图像作为输入, 但在卷积网络中加入串联层来融合第一阶段的信度图(空间特征)、第二阶段中阶段性的卷积结果(纹理特征)与高斯模板生成的中心约束这三部分, 串联后的尺度不变, 但深度变为48, 再经过一个卷积层, 输出大小为46×46×15的信度图。从第二个阶段开始加入一个提前生成的高斯函数模板(中心约束), 因为CPM是处理单个人位姿, 当图像中有多个人时则使用中心约束, 告知网络要处理的人的位置, 这样CPM就可以处理多个人的位姿问题; 第三阶段将第二阶段中途提取的深度为128的特征图作为输入, 这主要是为了学习各部件间隐含关系的依赖空间模型。然后与第二阶段相同, 加入串联层来融合空间特征、纹理特征与中心约束, 输出同第二个阶段; 第四阶段与第三阶段相同。以最后一个阶段输出的信度图为准, 最终定位14个人体关节点。如图 2所示, 然后通过这14个关节点将行人裁剪为7个区域(3个宏观区域, 4个微观区域)。行人整体骨架, 宏观区域:头部区域、躯干区域、腿部区域, 微观区域:左臂、右臂、左腿、右腿。如下共8部分。

MTCNN是在深度级联的多任务框架下利用检测与校准之间的相关性提升人脸检测的性能, 网络中使用边框回归向量校正候选窗口并使用非极大值抑制(NMS)合并重叠的候选框, 结构如图 4所示。
MTCNN分为3个阶段:第一阶段为浅层CNN快速提取网络(P-Net), 采用的是全卷积神经网络。首先将原图进行重采样得到不同尺寸的待检测图, 将每张待检测图输入到P-Net中会输出一系列候选窗体, 用NMS去掉一部分候选窗体, 然后将所有待检测图的候选窗体集合合并, 再次使用NMS去除一部分候选窗体, 余下为第一阶段最终输出; 第二阶段是较复杂的CNN精炼网络(R-Net), 同样采用全卷积神经网络, 将P-Net中的输出作为其输入进行训练, 利用边界框向量微调候选窗体, 再利用NMS去除重叠窗体, R-Net可以更精确的选取候选窗体; 第三阶段则使用更为复杂的CNN输出网络(O-Net), 该网络比R-Net多了1个卷积层, 功能与R-Net类似, 最终输出一个最精确的窗体。在特征提取网络1中将MTCNN中提取的行人面部映射到输入的行人图像上, 进行感兴趣区域池化(参照图 1)。
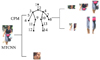 |
图 2 区域提取 |
CPM与RPN准确率对比
 |
图 3 CPM网络框架 |
 |
图 4 MTCNN网络结构 |
1.2 特征提取网络
特征提取网络最终得到包括行人总体区域、面部与7个分割区域的共9个256维特征。该网络主要分为3个部分:特征提取网络1、特征提取网络2、特征提取网络3。
特征提取网络1层由3个卷积层、1个inception模型和2个感兴趣区域池化层构成, 将96×96的原始图像作为输入经过特征提取网络1后得到F01, 将经过感兴趣区域池化后的面部图像作为输入得到F11, 将F2, F3, F4分别与F01进行感兴趣区域池化分别得到F21, F31, F41, 特征提取网络1输出大小为24×24。特征提取网络2由1个inception模型和1个感兴趣区域构成, 在特征提取网络2中将特征提取网络1中输出的特征图作为输入的基础上, 得到F02, F12, F22, F32, F42, 再将F5, F6, F7, F8分别与F02进行感兴趣区域池化分别得到F52, F62, F72, F82, 特征提取网络2输出大小为12×12。特征提取网络3由1个inception模型、1个global pooling层和1个inner product层构成, 在特征提取网络3中将所有特征提取网络2的输出作为输入, 最终输出F03, F13, F23, F33, F43, F53, F63, F73, F83。
1.3 特征融合网络
特征融合网络采用对应元素取最大值方法将特征提取网络中输出的9个256维特征, 融合成1个256维特征, 用该特征表示输入行人的最终特征F。采用最大值融合方法能够很好地保留最重要的特征。如图 1所示, 特征融合部分先将左腿和右腿部分融合得到腿部融合特征, 再将左臂和右臂部分融合得到手臂融合特征, 将腿部特征与手臂特征融合得到下半身特征融合, 将手臂融合特征与躯干区域的特征融合得到上半身融合特征, 再将下半身融合特征与上半身融合特征相融合得到全身融合特征。大量数据表明, 面部特征在总体特征中占有很大比重, 所以本文将面部特征放在倒数第二步与全身融合特征融合得到面部加全身融合特征, 最后再与完整的行人特征融合得到最终的256维的行人特征。
2 实验及结果分析
2.1 数据集
为了对比FS Net与Spindle Net的效果, 我们采取与Spindle Net相同的数据集, 在实验中评估了FS Net在6个现有的使用率较高的行人重识别数据集准确率, 数据集分别为: CUHK01[13], CUHK03[14], VIPeR[15], PRID[16], i-LIDS[17], 3DPeS[18], 同时也采用了Spindle Net论文中提出的数据集SenseReID作为测试集。我们同WARCA-x2, NFST, PersonNet, S-CNN, TCP, JSTL, Joint Re-id, TMA, GOG+XQDA, SCSP, MFA, CMC-top, BoW-best等方法做了对比分析[10], 并采用与JSTL相同的参数设置(迭代次数=70 000, batch size=20)来生成训练、验证和测试图像集/候选图像集样本, 训练和验证集中的行人与所有数据集的测试集行人没有重叠。
2.2 训练及测评方法
在训练过程中我们采取与Spindle Net相同的策略即分步训练, 训练时将所有数据集整合到一起, 然后打乱顺序进行训练。先在区域提取网络中将面部与人体的7个区域提取出来, 然后依次放入特征提取网络中进行特征提取, 再将提取各区域的特征依次放入特征融合网络中进行特征融合, 并且全部网络的训练过程都是有监督的。在特征提取与特征融合网路中, 使用现有的行人重识别数据集并采用Softmax分类损失, 在计算损失函数之前, 将特征向量变换为概率向量。
我们将实验结果与Spindle Net和其他行人重识方法进行对比, 采用CMC曲线[19]测评方法。
2.3 实验结果
由于Spindle Net比较完善, 其论文中已与多种方法进行的对比, 且有明显优势, 所以本文在此基础上与之比较。实验对比结果如表 2~8所示, 其中Top-1是指匹配结果中, 候选行人库中与要查询的行人匹配率最高的行人, 即首位为检索行人, Top-1是一个重要的衡量指标, 其准确率越高, 则代表算法越好。Top-5/10/20分别是指在匹配率最高的前5/10/20张候选行人库的图像中, 存在与查询的行人正确匹配图像的概率。实验结果显示本文提出的方法在如下所示的通用数据集上均取得较高的准确率。
由实验对比结果可知, FS Net在前6个数据集中准确率提高明显, 在CUHK03数据集中提高5.5%、CUHK01数据集中提高4.2%、PRID数据集中提高13%、VIPeR数据集中提高7.4%、3DPeS数据集中提高3.5%、i-LIDS数据集中提高8.7%。大部分数据集上Top-1准确率有平均7%的提升, 但在SenseReID数据集中实验结果不理想。
针对不理想的实验结果, 我们进行了进一步的实验对比分析。首先, 将除SenseReID外的其他数据集都进行了下采样再上采样, 然后放入网络中进行测试, 实验结果如表 9所示, 分别为经过1次下采样加上采样的实验结果、经过下采样加上采样2次的实验结果和原始图片进行对比实验, 我们使用最具有代表性的Top-1进行准确率对比。从表中可知, 准确率并无明显变化。可见, 本文提出的模型具有一定抗干扰性, 对图像质量要求并不明显。其次, 我们详细分析了SenseReID数据集, 发现此数据集中存在大量头部遮挡或背影图像, 因此导致重识别准确率下降。在后续的研究中, 我们会继续针对面部残缺问题进行研究和修正模型。
同时我们还对原始的面部MTCNN网络进行了测试, 将面部以外的其他影响参数设置为0, 单独使用MTCNN网络做重识别, 如我们预期, 准确率不足本文算法的50%, 具体统计数据如表 9所示。该实验表明, 单独使用面部特征进行行人重识别并不能达到较高的准确率。
CUHK03实验结果对比
CUHK01实验结果对比
PRID实验结果对比
VIPeR实验结果对比
3DPeS实验结果对比
i-LIDS实验结果对比
SenseReID实验结果对比
准确率对比
3 结论
在本研究中, 我们将面部特征融入到Spindle Net中, 由于面部特征的重要性, 在融合部分我们提高了面部特征的权重, 这能很好地保留重要的面部特征。从实验结果得, 对比同类方法FS Net的准确率在容易提取面部特征的数据集中准确率较高。
References
- Cai Q, Aggarwal J K. Tracking Human Motion Using Multiple Cameras[C]//International Conference on Pattern Recognition, 1996: 68–72 [Article] [Google Scholar]
- Gheissari N, Sebastian T B. Person Reidentification using Spatiotemporal Appearance[C]//Computer Vision and Pattern Recognition, 2016: 1528–1535 [Article] [Google Scholar]
- Weinberger K Q, Saul L K. Distance Metric Learning for Large Margin Nearest Neighbor Classification[J]. Journal of Machine Learning Research, 2009, 10(1): 207–244 [Article] [Google Scholar]
- Zheng W S, Gong S, Xiang T. Person Re-Identification by Probabilistic Relative Distance Comparison[C]//Computer Vision and Pattern Recognition, 2011: 649–656 [Article] [Google Scholar]
- Li A, Liu L, Yan S. Person Re-Identification by Attribute-Assisted Clothes Appearance[M]. Springer London, Person Re-Identification, 2014: 119–138 [Google Scholar]
- Varior R R, Shuai B, Lu J, et al. A Siamese Long Short-Term Memory Architecture for Human Re-Identification[J]. European Conference on Computer Vision, 2016, 135–153 [Article] [Google Scholar]
- Zheng L, Huang Y, Lu H, et al. Pose Invariant Embedding for Deep Person Re-Identification[J]. Computer Vision and Pattern Recognition, 2017 [Article] [Google Scholar]
- Zhao L, Li X, Wang J, et al. Deeply-Learned Part-Aligned Representations for Person Re-identification[J]. Computer Vision and Pattern Recognition, 2017, 1: 3239–3248 [Article] [Google Scholar]
- Wei L, Zhang S, Yao H, et al. GLAD:Global-Local-Alignment Descriptor for Pedestrian Retrieval[J]. Computer Vision and Pattern Recognition, 2017 [Article] [Google Scholar]
- Zhao H, Tian M, Sun S, et al. Spindle Net: Person Re-Identification with Human Body Region Guided Feature Decomposition and Fusion[C]//Computer Vision and Pattern Recognition, 2017, 1: 907–915 [Article] [Google Scholar]
- Zhang K, Zhang Z, Li Z, et al. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499–1503 [Article] [NASA ADS] [CrossRef] [Google Scholar]
- Wei S E, Ramakrishna V, Kanade T, et al. Convolutional Pose Machines[J]. Computer Vision and Pattern Recognition, 2016, 4724–4732 [Article] [Google Scholar]
- Li W, Zhao R, Wang X, et al. Human Reidentification with Transferred Metric Learning[C]//Asian Conference on Computer Vision, 2012: 31–44 [Article] [Google Scholar]
- Li W, Zhao R, Xiao T, et al. DeepReID: Deep Filter Pairing Neural Network for Person Re-Identification[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014: 152–159 [Article] [Google Scholar]
- Gray D, Tao H. Viewpoint Invariant Pedestrian Recognition with an Ensemble of Localized Features[C]//European Conference on Computer Vision, 2008: 262–275 [Article] [Google Scholar]
- Hirzer M, Beleznai C, Roth P M, et al. Person Re-Identification by Descriptive and Discriminative Classification[C]//Scandinavian Conference on Image Analysis, 2011: 91–102 [Article] [Google Scholar]
- Wang T, Gong S, Zhu X, et al. Person Re-Identification by Video Ranking[C]//European Conference on Computer Vision, 2014: 688–703 [Article] [Google Scholar]
- Baltieri, Davide, et al. 3DPeS: 3D People Dataset for Surveillance and Forensics[C]//Proceedings of the 2011 Joint ACM Workshop on Human Gesture and Behavior Understanding, 2011: 59–64 [Article] [Google Scholar]
- Decann B, Ross A. Relating ROC and CMC Curves via the Biometric Menagerie[C]//IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems, 2013: 1–8 [Article] [Google Scholar]
All Tables
All Figures
|
图 1 FS网络流程图 |
| In the text | |
|
图 2 区域提取 |
| In the text | |
|
图 3 CPM网络框架 |
| In the text | |
|
图 4 MTCNN网络结构 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.