| Issue |
JNWPU
Volume 40, Number 6, December 2022
|
|
|---|---|---|
| Page(s) | 1414 - 1421 | |
| DOI | https://doi.org/10.1051/jnwpu/20224061414 | |
| Published online | 10 February 2023 | |
Image fusion method based on JBF and multi-order local region energy
基于JBF与MLNE的图像融合方法
1
School of Physics and Electrical Engineering, Weinan Normal University, Weinan 714099, China
2
School of Automation, Northwestern Polytechnical University, Xi'an 710072, China
Received:
15
March
2022
Abstract
针对多模态医学图像融合方法融合质量差、计算效率低等问题。提出了一种基于联合双边滤波(JBF)与多阶局部区域能量(MLNE)的图像融合方法。该方法将输入图像分解成能量层和结构层, 对于能量层与结构层的融合分别提出了基于MLNE和局部区域L2范数取大值的融合方案, 融合能量层和结构层相加获得融合图像。1组不同模态的医学图像融合实验结果证明, 文中提出的方法在融合性能、计算效率、视觉评价等方面都优于其他的对比方法。
摘要
To address the poor fusion quality and low computational efficiency of multimodal medical image fusion methods. In this paper, an image fusion method based on joint bilateral filtering (JBF) and multi-order local region energy (MLNE) is proposed. The method firstly decomposes the input image into energy and structure layers; then for the fusion of energy and structure layers, a fusion scheme based on MLRE and local area L2 norm taking large values is proposed respectively; finally, the fused energy and structure layers are summed to obtain the fused image. The experimental results of medical image fusion with one groups of different modalities prove that the present method outperforms other comparative methods in terms of fusion performance, computational efficiency, and visual evaluation.
Key words: joint bilateral filter / multi-order local regional energy / medical image fusion / L2 norm
关键字 : 联合双边滤波 / 多阶局部区域能量 / 医学图像融合 / L2范数
© 2022 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
随着计算机和高性能计算技术的迅速发展, 多模医学图像在医学领域得到了广泛的应用。多模医学图像主要包括解剖图像和功能图像。解剖图像包括磁共振成像(MRI), 功能图像包括正电子发射断层扫描成像(PET)和单光子发射计算机断层扫描成像(SPECT)。一般来说, 单设备能够产生单模态图像。MRI显示的解剖结构非常清晰。另外, 在解剖学背景下可以清晰显示出病变, 使病变与解剖结构之间的关系更加紧密。PET和SPECT图像能正确反映细胞代谢活动的信息。然而, 由于病变不是独立的, 病变与周围组织异常信息之间有很强的相关性。医学图像融合目的是将2幅或多幅多模态图像组合成一幅图像, 并保留原始信息。因此, 融合图像具有多模态信息, 能准确揭示病变与周围组织的关系, 并为后续计算机辅助诊断、疾病分析和操作等医疗技术提供客观的参考信息[1]。
在过去的20年里, 基于像素级水平提出了许多种医学图像融合方法。其中, 基于多尺度变换(MST)的方法由于其能提取图像多尺度特征而受到广泛的关注。基于MST的方法包括3个步骤: 多尺度分解(MSD), 频域系数选择, 以及通过执行相应的逆MSD进行系数重构。MSD工具的选择和融合方案设计是基于MST方法的2个关键因素。对于MSD来说, 一些具有代表性的工具主要有: 拉普拉斯金字塔(LP)、剪切波(SHT)、复小波变换(CWT)[2]、轮廓波变换(CNT)、平移不变的Contourlet变换(NSCT)和平移不变的剪切波变换(NSST)[3]。由于具有灵活的多尺度、多方向、和平移不变的图像分解方式, 与其他MSD的方法相比, NSCT和NSST具有显著的优势和突出的融合性能。
对于MST的融合方法来说, 频域系数的选择也是应考虑的一个重要问题。通常情况下, 像素的绝对值越大, 所对应的图像像素就越活跃。因此, 常选用系数绝对值取大的方法作为高频系数的融合方案。与之相反, 低频系数提供了粗的图像特征, 常用平均方法来融合低频系数。然而, 最大/平均的融合方案常引入一些不正确的振铃, 并产生令人不满意的融合结果。为此, 近年来提出了一些新的融合规则, Liu等[4]提出了一种基于MST和稀疏表示(SR)的图像融合方法。在该方法中, 构造了一种基于字典学习(DL)的方案, 将LP分解的低频系数融合为医学融合图像。在NSST变换域, Yin等[3]提出了一种基于参数自适应脉冲耦合神经网络(PA-PCNN)的医学图像融合方法。该方法利用PA-PCNN模型和基于能量的融合规则分别融合高频和低频系数。Zhu等[5]提出了一种基于NSCT的医学图像融合方法。在该方法中, 利用基于相位一致性的规则来融合低频成份, 基于局部拉普拉斯能量的规则来融合高频成份。以上方法的融合方案可以很大程度上解决基于MST传统融合规则的不足。然而, 由于多尺度分解和重构过程的内在缺陷[3-5], 会产生冗余信息, 导致融合结果不是最好。
除了MST外, SR理论以其构造超完备字典, 利用原子稀疏线性组合方式表示图像的能力, 在医学图像融合方面得到研究, 并提出了一些基于SR的医学图像融合方法。Kim等[6]首次利用引导核聚类和主成分分析(PCA)的局部回归权重, 提出了一种基于块聚类DL的图像融合方法。该方法虽可以生成一种信息丰富、紧凑的超完备字典, 但是, 输出结果融合图像的对比度显著降低, 源图像中的一些重要亮度信息不能很好地保留在融合结果中。Zhu等[7]提出了一种新字典构造的医学图像融合方法。该方法利用局部稠密峰值聚类技术将图像块分为几类, 并通过相应的K-SVD组生成子字典。为了获得一个紧凑、信息丰富的超完备字典, Zhou等[8]提出采用多尺度图像块选择和增强方法处理训练数据, 并通过基于能量子字典和基于细节子字典构造字典。该方法虽能获得一定的融合效果, 但是在RGB空间融合彩色医学图像时, 存在严重的颜色失真。
随着机器学习(ML)理论的快速发展, 出现了一些基于ML的医学图像融合方法[9]。在文献[9]中, 卷积稀疏表示(CSC)被引入到图像融合领域, 实验结果表明, 基于CSC的方法由于去除块操作而优于基于SR的方法。Liu等[10]提出了基于卷积神经网络(CNNs)的医学图像融合方法。在该方法中, 由CNNs获得来自源图像的活动像素信息权重, 并通过拉普拉斯金字塔完成图像融合过程。随后, Liu等[11]提出了一种基于CSC和形态成分分析的医学图像融合方法。该方法虽能获得较好的融合效果, 但仅对灰度图像测试效果良好。此外, SR字典学习、重建过程和基于CSC的方法通常需要设置的参数过多、耗时较长。为了解决传统的基于MST和SR方法的缺陷, 提高融合性能。Li等[12]提出了基于引导滤波(GFF)的图像融合方法。在此方法中, 引入了基于2种尺度分解模型, 并建立了基于GFF的加权平均方案。Du等[13]提出了一种解剖和功能医学图像的融合方法, 并采用一种基于感兴趣信息区域的融合规则来处理冗余融合图像。Li等[14]提出了一种拉普拉斯重新分解的医学图像融合方案, 该方案利用重叠和非重叠域合并冗余和互补信息。
总之, 与一些传统方法相比, 这些主流的多模态医学图像融合方法虽能在在一定种程度上提高融合的性能, 但也存在一些缺点。例如, 使用平均的融合方案将导致融合结果图像的对比度降低; 多尺度工具分解/重构图像的过程中效率较低, 丢失信息严重; 字典学习, 稀疏编码的融合方案由于迭代次数过多, 所以耗时较长。以上所提到的最先进的医学图像融合方法很难同时满足融合性能、时间效率高等要求。
基于此, 本文提出了一种基于JBF和MLNE的图像融合方法。该方法先利用JBF将医学图像分解为结构层和能量层; 然后引入结构丈量、计算图像MLRE, 并提出一种基于MLRE方案融合细节结构层; 由于能量层结构弱, 亮度强的特性, 提出了一种基于改进区域L2范数的方案融合能量层; 最后, 采用1组不同类型医学图像进行实验测试, 测试实验结果表明, 该方法在主观视觉和客观评价方面都优于主流的融合方法。
1 结构丈量
像素差异可以表示梯度特征。对于多模态医学图像来说, 梯度特征能够精确地反映感知纹理、边缘和器官/组织/纤维的几何机构。在过去的几年里, 结构丈量(ST)已成为局部梯度特征分析的一个重要工具[15]。在许多低级别医学图像分析、图像正则化和聚焦图像融合中得到广泛应用。
假设感兴趣图像g(x, y), 对于任意ε→0+, 在点(x, y)处, 局部窗Θ(x, y)内, 图像g(x, y)在α方向上的变化可以表示为
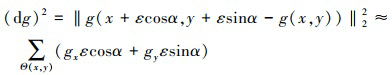 1
1
图像g(x, y)的局部几何特征在位置(x, y)处的变化率C(α)可以表示为
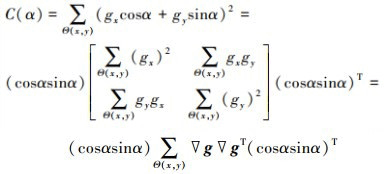 2
2
式中, ▽g=(gx, gy)T, 在方程(2)中, 中间项是一个二阶半正定矩阵, 其被称为结构丈量, 可表示为
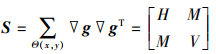 3
3
式中,  。
。
结构丈量▽g▽gT的2个特征值可计算如下
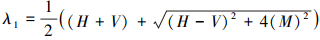 4
4
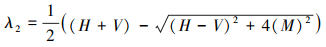 5
5
通过(4)和(5)式计算所得2个特征值, 如果相对较小, 表明局部区域位于各向同性区, 即该地区地势平坦, 没有重要的变化。如果λ1≥λ2, 两者都相对较大, 说明局部区域位于各向异性区域, 并包含一定的梯度特征, 结构张量显著性(STS)检测算子可以定义为
 6
6
2 本文方法
本文提出了一种基于JBF与MLNE的医学图像融合方法, 并详细讨论了该方法实现的过程。其方法实现的原理框图如图 1所示。与许多医学图像融合方案相似, 本文所提出的方法包括分解、融合规则设计和重构3个步骤, 这3个步骤实现的详细细节将在后续部分进行详细介绍。
 |
图1 本文方法实现的原理框图 |
2.1 2种成分分解
图像融合的主要挑战是如何分解源图像之间的互补信息。2种尺度成分分解技术被广泛应用到许多图像融合方法中。利用低通/平均滤波隔离基层和细节层并不是2种最流行的方法。它们产生基层通常由滤波技术进行平滑, 导致全局模糊, 而细节层是基层的互补部分, 并包含丰富的高频信息。然而, 这些平均的方案可能会或多或少地破坏输入图像的边缘, 导致细节层的结构次优特征, 并阻碍了医学图像融合中细节部分的结构检测。在本文中, 采用了一种基于JBF的有效双尺度分解方法。该方法假设亮度信息和梯度结构是医学图像的2个最重要特征, 并采用全局模糊和边缘恢复2个步骤来实现能量结构的分解方案。
2.1.1 全局模糊
图像平滑的主要目的是在最大程度上将输入图像的详细信息传播到分解结构层, 该目标可通过如下所示的高斯滤波来完成
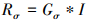 7
7
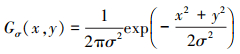 8
8
式中: I是输入图像; Gσ(x, y)是方差v=σ2的高斯滤波; Rσ是在标准方差σ处的平滑结果。基于尺度空间理论; σ2表示为尺度。如果图像结构尺度小于高斯标准偏差σ, 它将在Iσ中被完全删除。如果仅观察到模糊的结果, 将会产生输入图像的细小结构完全出现在结构层当中。
随后, 利用加权平均高斯滤波器生成全局模糊图像, 其实现过程可被定义如下
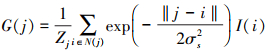 9
9
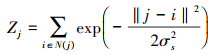 10
10
式中: I和G分别表示输入和输出图像。j和i表示像素索引坐标, N(j)是i的相邻像素集合。σs表示标准偏差, 且Zj表示归一化操作。
2.1.2 边缘复原
在本文中, 利用方程(9)能有效移除小尺度结构, 然而, 在平滑操作期间大于σs的结构将会被破坏。其结果是, 大尺度结构将在一定程度上保留在能量层中, 这可能会导致能量和结构层的不完全分解: 能量层中包含一些结构特征。
为此, 本文利用JBF的思想来复原图像大结构。输入图像I的能量层可以通过以下滤波得到
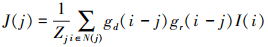 11
11
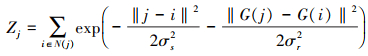 12
12
空间距离函数gd根据像素之间的距离来设置权重, 而强度范围函数gr则根据强度差异设置该范围上的权重。
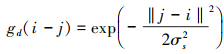 13
13
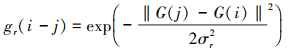 14
14
式中, σs和σr分别控制双边滤波(BF)的空间和范围权重。由于像素值决定范围函数的权重, 所以它是非线性的。重要的是, 它可以保留边缘, 即恢复所提出模型中的大结构。通过执行方程(11), 可以同时考虑空间距离和邻域像素亮度值。值得注意的是, 本文采用的JBF与滚动引导滤波器相似, 但是在该方案中迭代只用了1次。
对于2幅源医学图像A和B, 它们的能量层可以分别表示为EA和EB, 其结构层可以通过以下方式获得
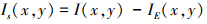 15
15
式中, Is(x, y)是图像I的结构层, I=A, B。
2.2 多阶局部区域能量的结构层融合
经过JBF分解获得的结构层主要包含有源图像的弱纹理信息(如轮廓、边缘、角点等)。传统的方法在融合能量层时, 常采用系数绝对值取大或特征值取大的方法来融合能量层, 该类方法所产生的融合图像边缘比较模糊, 亮度较差。为获得清晰的结构, 减少融合图像信息的损失, 结构丈量显著性检测(STS)的方法被引入到能量层融合当中, 并获得了较好的融合效果, 但是STS缺乏亮度函数, 对于医学图像中的弱小特征无法检测, 为了解决这些缺点, 提高融合图像的性能, 本文引入了MLNE来改善STS的检测性能, 并提出了一种MLNE联合ST的融合方案。
现将MLNE的实现过程介绍如下
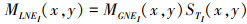 16
16
式中, STi(x, y)是由STS产生的显著性图像, MGNEi(x, y)表示位置在(x, y)处MGNE特征, 并且它可以被定义为
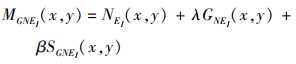 17
17
式中, NEi(x, y)、GNEi(x, y)和SGNEi(x, y)分别表示位置在(x, y)处的局部邻域能量NEi、局部邻域梯度能量GNEi及局部邻域二阶梯度SGNEi。NEi, GNEi和SGNEi分别被定义为
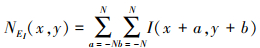 18
18
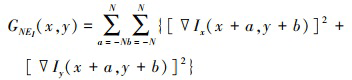 19
19
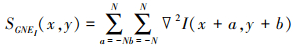 20
20
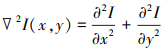 21
21
式中, 的定义如下所示
的定义如下所示
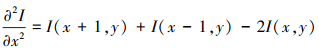 22
22
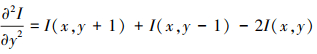 23
23
式中, 邻域的大小为(2N+1)×(2N+1), ▽Ix和▽Iy分别表示图像在水平x方向与垂直y方向上的一阶梯度,  和
和 分别表示图像在水平x与垂直y方向上的二阶梯度。
分别表示图像在水平x与垂直y方向上的二阶梯度。
通过比较输入图像MLNE, 图像A(x, y)的结构显著性检测映射MA(x, y)可以通过以下方式获得
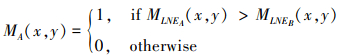 24
24
MB(x, y)可以通过类似的方程产生, 此外, 考虑到对象的完整性, Mi(x, y)可以通过以下操作进行进一步细化
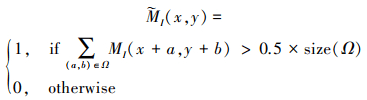 25
25
式中,Ω表示位置在(x, y)处大小为T×T的局部区域。基于源图像的检测映射, 融合能量结构成分可以通过(26)式获得
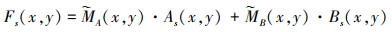 26
26
2.3 L2范数特征的能量层融合
与长度概念相关联的范数, 常用来在向量(或矩阵空间中)测量每一个向量的长度和大小。这种范数的向量空间被称为归一化向量空间。也就是说, 范数是向量空间或矩阵中所有向量正长度(大小)的和, 矩阵(向量)越大, 范数就越大。
在图像融合中, 医学图像的细节特征, 是决定融合图像质量的关键因素, 由像素振幅(系数)以及来自相邻像素(系数)的区域信息表示。图像内的区域或特征区域可以看作是向量空间(矩阵), 像素或系数的值可以看作是向量空间的向量。因此, 本文发现医学图像的特征可以通过范数理论来解决, 该理论为医学图像的特征提取提供了物理基础, 可用于表示医学图像的详细特征。
对于n维特征空间v=(v1, v2, …, vn), 获得的ρ范数可以用Lρ范数表示为
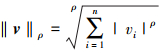 27
27
式中, ρ≥1是整数。比如, L1范数(ρ=1), L2范数(ρ=2)。
L2范数是一种流行的范数, 它经常被应用于许多工程和科学学科。L2范数可被定义为
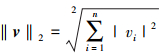 28
28
将L2范数进一步重写为
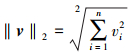 29
29
对于1幅图像, 可得到基于L2范数的特征为
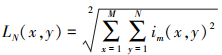 30
30
式中:LN表示基于L2范数的图像特征;M和N表示图像的大小;im(x, y)为图像在第x行, 第y列的像素值。
L2范数常被用来测量向量空间向量差的标准量。
受L2范数和图像区域特征的启发, 基于L2范数的特征能够表示医学图像的细节信息。L2范数主要由行L2范数和列L2范数组成, 其对应的行和列L2范数的计算公式如(31)~(34)式所示。
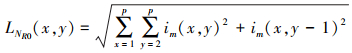 31
31
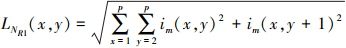 32
32
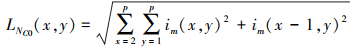 33
33
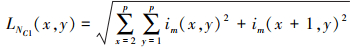 34
34
式中:p是窗的大小;im(i, j)是图像在第i行和第j列的像素值; LNR和LNC分别表示基于L2范数的行和列特征。基于L2范数的特征可计算如下
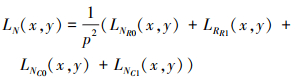 35
35
根据基于L2范数特征的幅度, 将能量层的融合方案定义如下
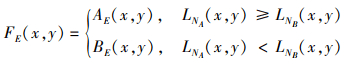 36
36
式中:AE和BE分别表示不同图像的能量层;FE表示融合后的能量层图像。
2.4 图像重构
最后, 将融合的结构层和能量层相加获得融合图像。
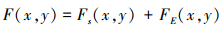 37
37
式中: F表示结构融合图像; Fs和FE分别表示融合后结构和能量层图像。
3 实验结果分析
3.1 实验设置
在本节中, 采用1对大小为256×256的多模医学图像进行测试, 该测试图像都可以从哈佛大学的医学图像图书馆<a href="http://www.med.harvard.edu/aanlib/" target="_blank">http://www.med.harvard.edu/aanlib/</a>下载。为了证明本文所提算法的优越性, 将所提算法与基于CSR融合方法[<xref ref-type="bibr" rid="R9">9</xref>]、基于NSST和PAPCNN的融合方法(NSST-PAPCNN)[<xref ref-type="bibr" rid="R3">3</xref>]、基于卷积稀疏形态成分分析(CSMCA)的融合方法[<xref ref-type="bibr" rid="R11">11</xref>]、基于拉普拉斯重分解(LRD)的融合方法[<xref ref-type="bibr" rid="R14">14</xref>]及基于对比度和结构提取的(CASE)融合方法进行对比[<xref ref-type="bibr" rid="R16">16</xref>]。所有对比方法的参数设置与他们各自公开发表的文章相一致。对比方法的源码由他们各自的作者提供。本文所提方法中, 分别将高斯标准差<italic>σ</italic><sub><italic>s</italic></sub>设置为3, <italic>N</italic>设置为4, <italic>T</italic>设置为21。
3.2 客观评价指标
6种主流的图像融合标准包括互信息(MI), 边缘保留QAB/F, 相关信息熵QNCIE, 多尺度度量标准QM, Piella′s标准Qs, 以及Blum标准QCB, 用于评价不同方法所产生的融合性能。对于这些标准, 值越大表示融合性能越好。其中, Mi和QAB/F是两个常用的医学图像融合指标。同时, 根据Liu等人[17]进行的综合实验, 融合指标可分为基于信息论、基于图像特征、基于图像结构相似度和基于人类视觉感知的4类指标。在本实验中, 最后4个指标QNCIE, QM, Qs和QCB分别对应4个种类。通过结合这6个指标的评价结果, 可以可靠、客观、权威的评价图像融合的质量。
3.3 融合结果与讨论
3.3.1 视觉评价
图 2显示了由不同方法产生的MRI-1和CT-1图像的融合结果。其中图 2a)和图 2b)为MRI-1和CT-1的源图像, 图 2c)~2h)分别为CSR、NSST-PAPCNN、CSMCA、LRD、CASE和本文提出方法的融合结果。为了更直观显示对比方法的差异, 对不同方法所产生的融合结果用红色正方形标记并进行局部放大。从融合结果的红色标记区域局部放大效果可以看出, CSR方法所得结果图像的区域缺失严重(见图 2c)), 视觉效果最差; NSST-PAPCNN方法的边缘出现了少量的伪影效应(见图 2d)); CSMCA和CASE方法得到的图像亮度较弱(见图 2e)和图 2g)); LRD结果中的边缘和纹理非常平滑(见图 2f))。相比之下, 本文所提方法能保留源图像中最多的结构信息(见图 2h)), 并表现出最好的亮度特征。
 |
图2 不同对比方法在MRI-1与CT-1数据集上产生的融合结果图像 |
3.3.2 客观评价
为了更进一步证明所提方法的有效性, 本文选用Mi, QAB/F, QNCIE, QM, Qs和QCB6种客观质量评价指标在MRI-1/CT-1数据集上评价各种对比方法所产生的融合性能。
表 1列出了图 2a)~2h)所示的MRI-1/CT-1融合图像的客观质量评价结果。观察表 1可以看出, 该方法的Mi, QNCIE, QM, QS和QAB/F的值最高, 而该方法的QCB值低于CSMCA方法。这足以说明采用该方法融合MRI-1/CT-1图像能够获得更多的结构和能量信息, 融合图像的边缘保留较好, 在融合过程中所用时间最短, 评价结果与人类视觉感知的结果一致。
MRI-1/CT-1融合图像的客观质量评价结果
4 结论
本文提出了一种基于JBF与多阶梯度能量感知融合方案的多模医学图像融合方法。在该方法中, 医学图像可被认为是结构和功能图像的组合, 针对结构和能量层的融合, 分别设计了基于多阶局部区域能量和区域L2范数的方案进行融合。选用1组不同类型的医学图像进行实验, 5种具有代表性的融合算法进行比较, 并采用6种融合指标进行客观评价, 实验结果证明, 该方法在主观视觉、客观评价和计算效率等方面明显优于主流的图像融合算法。
References
- FU J, LI W, DU J, et al. DSAGAN: a generative adversarial network based on dual-stream attention mechanism for anatomical and functional image fusion[J]. Information Sciences, 2021, 576: 484–506. [Article] [CrossRef] [Google Scholar]
- ZHU Pan, LIU Ze, HUANG Zhanhua. Infrared polarization and intensity image fusion based on dual-tree complex wavelet transform and sparse representation[J]. Acta Photonica Sinica, 2017, 46(12): 1210002. [Article] (in Chinese) [CrossRef] [Google Scholar]
- YIN M, LIU X, LIU Y, et al. Medical image fusion with parameter-adaptive pulse coupled neural network in nonsubsampled shearlet transform domain[J]. IEEE Trans on Instrumentation and Measurement, 2018, 68(1): 49–64 [Google Scholar]
- LIU Y, LIU S, WANG Z. A general framework for image fusion based on multi-scale transform and sparse representation[J]. Information Fusion, 2015, 24: 147–164. [Article] [CrossRef] [Google Scholar]
- ZHU Z, ZHENG M, QI G, et al. A phase congruency and local Laplacian energy based multi-modality medical image fusion method in NSCT domain[J]. IEEE Access, 2019, 7: 20811–20824. [Article] [CrossRef] [Google Scholar]
- KIM M, HAN D K, KO H. Joint patch clustering-based dictionary learning for multimodal image fusion[J]. Information Fusion, 2016, 27: 198–214. [Article] [CrossRef] [Google Scholar]
- ZHU Z, CHAI Y, YIN H, et al. A novel dictionary learning approach for multi-modality medical image fusion[J]. Neurocomputing, 2016, 214: 471–482. [Article] [CrossRef] [Google Scholar]
- ZHOU F, LI X, ZHOU M, et al. A new dictionary construction based multimodal medical image fusion framework[J]. Entropy, 2019, 21(3): 267. [Article] [CrossRef] [Google Scholar]
- LIU Y, CHEN X, WARD R K, et al. Image fusion with convolutional sparse representation[J]. IEEE Signal Processing Letters, 2016, 23(12): 1882–1886. [Article] [CrossRef] [Google Scholar]
- LIU Y, CHEN X, CHENG J, et al. A medical image fusion method based on convolutional neural networks[C]//2017 20th International Conference on Information Fusion, 2017 [Google Scholar]
- LIU Y, CHEN X, WARD R K, et al. Medical image fusion via convolutional sparsity based morphological component analysis[J]. IEEE Signal Processing Letters, 2019, 26(3): 485–489. [Article] [CrossRef] [Google Scholar]
- LI S, KANG X, HU J. Image fusion with guided filtering[J]. IEEE Trans on Image Processing, 2013, 22(7): 2864–2875 [CrossRef] [Google Scholar]
- DU J, LI W, XIAO B. Anatomical-functional image fusion by information of interest in local Laplacian filtering domain[J]. IEEE Trans on Image Processing, 2017, 26(12): 5855–5866. [Article] [CrossRef] [Google Scholar]
- LI X, GUO X, HAN P, et al. Laplacian redecomposition for multimodal medical image fusion[J]. IEEE Trans on Instrumentation and Measurement, 2020, 69(9): 6880–6890. [Article] [CrossRef] [Google Scholar]
- PRASATH V B S, PELAPUR R, SEETHARAMAN G, et al. Multiscale structure tensor for improved feature extraction and image regularization[J]. IEEE Trans on Image Processing, 2019, 28(12): 6198–6210. [Article] [NASA ADS] [CrossRef] [Google Scholar]
- SUFYAN A, IMRAN M, SHAH S A, et al. A novel multimodality anatomical image fusion method based on contrast and structure extraction[J]. International Journal of Imaging Systems and Technology, 2021, 20(12): 124–132 [Google Scholar]
- LIU Z, BLASCH E, XUE Z, et al. Objective assessment of multiresolution image fusion algorithms for context enhancement in night vision: a comparative study[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2011, 34(1): 94–109 [Google Scholar]
All Tables
All Figures
|
图1 本文方法实现的原理框图 |
| In the text | |
|
图2 不同对比方法在MRI-1与CT-1数据集上产生的融合结果图像 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.