| Issue |
JNWPU
Volume 42, Number 3, June 2024
|
|
|---|---|---|
| Page(s) | 453 - 459 | |
| DOI | https://doi.org/10.1051/jnwpu/20244230453 | |
| Published online | 01 October 2024 | |
Operator parallel optimization strategy for distributed databases
面向分布式数据库的算子并行优化策略
School of Computer Science, Northwestern Polytechnical University, Xi'an 710072, China
Received:
30
May
2023
Abstract
With the continuous development of network technology, the scale of data has shown explosive growth, which leads gradually to replacing traditional single machine databases with distributed databases. Distributed databases solve large-scale data storage problems through collaborative work among nodes, but due to increased communication costs between nodes, its query efficiency is not as good as a standalone database. In a distributed architecture, the data of storage nodes is only used as redundancy for multiple backups, providing data recovery in case of system failure, and it is not utilized to improve query efficiency. In response to the above issues, this article proposes an operator parallel optimization strategy for distributed databases. By splitting key physical operators, the split sub requests are evenly distributed to multiple nodes in the storage layer, which are processed in parallel by multiple nodes, thereby reducing query response time. The above strategy has been applied on distributed database CBase, and experiments have shown that the parallel optimization strategy proposed in this paper can significantly shorten SQL request query time and improve system resource utilization.
摘要
随着网络技术的不断发展, 数据规模呈现爆发式增长, 使得传统的单机数据库逐步被分布式数据库所取代。分布式数据库采用节点协同工作方式解决了大规模数据存储问题, 但由于增加了节点间通信开销, 查询效率却不如单机数据库。分布式架构下, 存储节点的数据仅用作多备份的冗余, 为系统故障时提供数据恢复, 并未被利用起来改善查询效率。针对上述问题, 提出了一种面向分布式数据库的算子并行优化策略, 通过对关键物理算子进行拆分, 将拆分后的子请求均匀分配到存储层多个节点, 由多个节点并行处理, 从而减少查询响应时间。上述策略已经在分布式数据库CBase上进行了应用, 实验表明, 提出的并行优化策略可显著缩短SQL请求查询时间, 并提高系统资源利用率。
Key words: distributed database / parallel query / query optimization / load balancing / data partitioning
关键字 : 分布式数据库 / 并行查询 / 查询优化 / 负载均衡 / 数据分区
© 2024 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
大数据时代, 随着物联网、云计算、人工智能等新型信息技术的飞速发展, 分布式数据库逐渐成为了大存储高性能数据库的主流解决方案[1–2]。在分布式数据库系统中, 数据以及计算资源处于不同的物理节点, 各节点通过网络连接在一起, 对外提供完整的服务。分布式的计算机资源分担了单个节点的计算压力, 分布式的物理存储为系统提供了故障恢复时的备份, 系统中节点之间通过Paxos协议或Raft协议保证数据的一致性[3]。
分布式的架构解决了数据规模爆炸式增长的难题, 但也面临着新的挑战。随着数据规模的不断扩大, 业务规模快速扩张, 却出现了即使动态增加了很多资源, 用户SQL语句的执行时间还是越来越长的现象, 显而易见, 虽然新增了很多资源, 但这些资源并没用被充分利用[4]。这对数据库的优化能力以及数据库的执行模式提出了更高的要求, 最直接的解决方法就是通过多线程并行执行降低包括IO以及CPU计算在内的处理时间, 以实现响应时间的大幅下降[5–7]。
开源关系数据库PostgreSQL[8]通过并行执行算子的方式提高查询效率,通常有3种方式。①并行扫描, 将原本单个Worker的工作逐块分发给互相协作的多个Worker, 充分利用数据库中的计算资源。②并行连接, PostgreSQL支持3种连接算法: NestLoop, MergeJoin以及HashJoin。其中NestLoop和MergeJoin仅支持左表并行扫描, 右表无法使用并行。多个进程并行获取部分数据并做Join操作, 再通过Gather算子将子计划的结果向上层算子输出。③并行聚合函数, PostgreSQL通过分2个阶段聚合支持并行聚合。首先, 参与查询的并行部分的每个进程作为计划中的一个Partial Aggregate节点执行一个聚合步骤, 生成部分结果; 然后, 部分结果通过Gather传递给Leader节点; 最后, Leader重新汇总所有Worker的结果, 以产生最终结果。
OceanBase[9]是阿里巴巴研发的国产分布式数据库。近年来, 在TPC-C和TPC-H测试上都刷新了世界纪录, 同样在并行查询方面做了很多研究。OceanBase数据库的执行计划在垂直方向上被划分为多个DFO(data flow object), 而每一个DFO可以被切分为指定并行度的任务, 通过并发执行以提高执行效率。一般来说, 当并行度提高时, 查询的响应时间会缩短, 更多的CPU、IO和内存资源会被用于执行查询命令。对于支持大数据量查询处理的DSS(decision support systems)系统或者数据仓库型应用来说, 查询时间的提升尤为明显。
本文深入研究了分布式数据库在大数据量场景下面临的问题及现有关系数据库的算子并行化策略, 以金融级分布式数据库CBase[10–12]为原型, 分析了其在表扫描与哈希连接中存在的性能瓶颈, 提出了对物理算子及执行流程的优化方案并进行了实现。实验表明, 本文所提出的并行优化策略可大幅减少查询响应时间, 提高查询效率。
1 CBase系统架构
CBase是西北工业大学联合交通银行研发的专门用于处理金融业务的分布式NewSQL数据库, 保留了传统数据库ACID和SQL等特性,同时具有良好的扩展性, 能够实现跨行跨表的事务处理。CBase数据库已在交通银行实际业务中上线使用, 在各种压力测试和并发测试中表现良好。
CBase的系统架构如图 1所示。
CBase的基本架构主要包括客户端和4种服务器, 即主控服务器(RootServer)、增量数据服务器(UpdateServer)、基准数据服务器(ChunkServer)和SQL处理服务器(MergeServer)。
1) RootServer中存储了数据库中所有表的元数据和集群中各服务器的状态信息, 主要功能包括: 集群管理、负载均衡、副本管理和数据分布。
2) UpdateServer是集群中唯一能够进行写操作的服务器, CBase采用基于Paxos组的一致性协议, 多台UpdateServer构成一个Paxos组, 最多为9组, 突破了单点写入的瓶颈。为了保证分布式事务的原子性, 系统中所有主UpdateServer需要在事务提交时保持一致, 因此采用了两阶段提交协议。
3) ChunkServer负责海量数据的存储。基准数据被拆分成很多Tablet, 每个Tablet都会保存多个副本, 这些副本存储在不同的ChunkServer上, 即使一台机器损坏也不会造成数据丢失。
4) MergeServer是客户端与CBase系统进行交互的接口, 是处理用户SQL请求的主要模块。MergeServer对用户输入的SQL语句进行词法分析、语法分析, 经过查询优化后生成对应的执行计划, 最后根据执行计划递归调用CBase内部的物理算子。
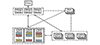 |
图1 CBase系统架构 |
2 CBase查询性能分析
不同SQL语句在生成执行计划时会用到不同的物理算子, 常用的查询包括单表查询和多表查询。对这2种查询中的SQL语句各执行阶段以及各算子的耗时进行统计分析, 从而找到性能瓶颈, 并针对瓶颈点进行优化。
1) 单表查询: 新建测试表t1, 表中c1列、c2列数据类型均为int, 其中c1列为主键, c2列都为大于0的值, 查询语句为select c1 from t1 where c2>0, 3次测试的数据量分别为10万, 20万, 40万行。查询语句生成的物理计划如图 2所示。
执行过程中, 首先调用TableScan算子, 扫描t1表中的数据, 接着根据表达式执行投影(Project)和过滤(Filter)操作, 返回的结果只包含c2>0的数据行, 且每行只包含c1, c2 2列。最后调用顶层的Project操作符, 只返回c1列数据。测试结果如表 1所示。
通过测试结果可以看出, 生成计划阶段耗时基本不变, 但是随着表数据量的增长, TableScan算子的扫描时间随之线性增长。并且总耗时的增加几乎全部来源于TableScan算子时间执行的增长。
经分析发现, MergeServer将请求数据的包发送给ChunkServer之后, ChunkServer扫描基线数据时, 会把查询结果逐行存放在一个用于传输的数据结构Scanner中。由于传输协议限制, Scanner的数据量只能在2 MB以内, 因此当返回数据量大于2 MB时, 同一个Tablet上的数据需要分为多次返回给MergeServer。MergeServer需要等待上次ChunkServer的返回结果, 根据返回结果检查是否需要生成更多的子请求获取随后的数据, 进行下次数据的发送, 整个过程是串行执行, 因此数据扫描时间会随着数据量的增加而显示出线性增长。
2) 多表查询: 新建测试表t1, t2, 两表结构相同, 表中c1列、c2列数据类型均为int, 其中c1列为主键, 查询语句为select t1.c1, t2.c1 from t1, t2 where t1.c1=t2.c1, 3次测试的参与连接的数据量分别为10万, 20万, 40万行。查询语句生成的执行计划和执行流程如图 3所示。
多表查询首先调用TableScan读取t1表的数据, 将t1所有复合查询的数据获取到MergeServer, 并生成布隆过滤器和哈希表。然后将参与Join的t1表生成的布隆过滤器作为SQL表达式的一个条件参数, 序列化后传入t2表所在的ChunkServer, 过滤t2表中的数据。当无等值连接条件时, 布隆过滤器为空, 对t2表进行全表扫描。然后拿t2表返回的数据去探测哈希表, 找出哈希表中匹配的行, 进行等值Join操作。然后按照不等值条件进行过滤, 进而输出最终结果。执行时间如表 2所示。
从表 2可以看出, 生成计划阶段耗时基本不变, 但是随着表数据量的增长, Join算子的执行时间随之呈现线性增长的趋势。由于连接操作的子算子都是TableScan, 因此存储层单线程扫描问题依然存在, 扫描时间会随着数据量增长线性增长。此外, 哈希连接中构建、探测哈希表及连接等操作也都是MergeServer单线程处理, 从而限制了性能的提升。
 |
图2 单表查询物理计划 |
单表查询执行时间 s
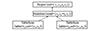 |
图3 多表查询物理计划 |
多表查询执行时间 s
3 算子并行优化策略
3.1 TableScan并行优化策略
1) 并行架构设计
目前CBase中SQL语句的执行计划树生成过程中, 没有将数据的物理分布情况、用户对执行性能的要求等因素考虑在内, 只是简单地将SQL语句中各子句的语义解析之后挂载到语法树对应的子节点, 并根据语法树的结构, 将物理算子按照顺序与其父子算子连接, 执行时依次自上而下地调用。物理算子与执行线程是一对一的关系, 这就决定了计划的执行是串行的过程。这种方式没有利用到分布式数据库中丰富的计算和存储资源, 要对现有执行流程进行并行优化, 就需要在生成阶段对执行计划进行水平拆分, 在分发时将各个互不相交的部分发送到多个功能相同的Server节点, 多节点间的工作线程共同处理, 从而实现对原流程的并行优化。并行TableScan架构如图 4所示。
MergeServer上根据查询涉及的数据量的大小、Tablet的物理分布情况、并行度的大小等多个因素, 将大数据量的查询请求拆分成多个子请求, 将各个子请求分发到所在的ChunkServer上, 尽可能地将原本在MergeServer和ChunkServer中单线程串行完成的任务交由多线程并行执行, 从而起到很好的加速效果。由于改造后的查询计划多了任务切分和结果汇总2个阶段, 因此需要引入2个新的算子: GranuleIterator、Gather, 分别负责任务的切分与汇总, 并在扫描任务拆分之后对这2个物理算子中的各字段进行填充。经过上述处理, 原本的串行执行计划转变成了具有分布式执行能力的并行执行计划。
2) 并行度指定
在CBase中用并行度指定执行物理计划的线程数量。在CBase中通过Parallel这个Hint来指定并行度。并行度的指定需要MergeServer和ChunkServer联合完成。确定并行度后, MergeServer会将并行度拆分到需要执行物理计划的多个ChunkServer上。执行计划中在MergeServer层的Gather算子中会计算并行度需要访问的所有Tablet, 然后根据MergeServer中缓存的Tablet分布信息找到存储这些Tablet的ChunkServer, 分别记为Tablet1, Tablet2, …, Tabletn, 然后将并行度按存储空间占比划分给这些ChunkServer。
在计算比例时, MergeServer需要利用数据库内部收集的统计信息, 根据其中记录的Tablet存储数据行数、列数、列数据类型等信息, 粗略地计算出每行的大小, 再乘以行数, 得出大致的Tablet大小Si。
实际分到各个Tablet中的并行度Di由公式(1)计算得出
 (1)
(1)
式中,D为Hint中指定的并行度, 在计算时向上取整。
3) 子请求切分
对TableScan算子的性能优化依赖于多线程的并行执行, 原查询任务经过切分后的最小执行单位称为子请求。查询的响应时间取决于执行时间最长的线程, 因此请求的切分直接关系到并行优化效果。应尽可能保证切分后的子请求大小均衡、数量适当, 采用合适的调度算法, 使得线程池中的各线程负载均匀。
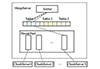 |
图4 并行TableScan架构 |
3.2 HashJoin并行优化策略
对查询语句的优化要基于统计信息中各个数据表的统计直方图信息以及集群的资源统计信息。优化内容包括对查询语句进行变换, 调整基本操作的次序, 选择合理的存取策略, 以及选择代价最小的优化执行等。这部分工作继承于查询优化器, 本文在优化器生成的查询计划基础之上进行并行化处理, 将连接查询语句转换成多个可以分解成在多个线程上并行执行的子查询计划。并行执行框架如图 5所示。
MergeServer将SQL语句解析并生成物理查询计划后, 在MergeServer端开启线程池分发查询计划, 并行地从存储左表的ChunkServer中拉取数据, 然后在MergeServer中各线程独自构建哈希表, 哈希表构建结束后, 再并行地从存储右表的ChunkServer中拉取数据, 各线程在MergeServer中完成对哈希表的探查操作并进行连接, 各线程的结果汇总之后即可返回给客户端。
在OLTP场景下, 连接操作的物理算子不仅仅局限于HashJoin, 还包括Merge Join、Nested-loop Join等其他物理连接算子, 但其底层都需要调用TableScan算子, 所以该算子的并行化对连接查询效率都有不同程度提高。连接算子自身的优化也可以参考HashJoin的并行化策略。
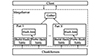 |
图5 HashJoin并行执行框架 |
4 实验结果
实验的目的是验证并行优化策略在面对大数据量查询时的有效性, 主要通过对优化前后在不同数据量、不同并行度下的TableScan和Hash Join查询响应时间进行了测试。
4.1 实验环境
本文所有实验节点采用同一软硬件配置, 详细配置参数如表 3所示。
服务器硬件配置信息表
4.2 不同并行度对TableScan性能的影响
本实验对并行TableScan优化有效性进行了验证, 主要测试单表且全表扫描情形下原流程与并行优化后的响应时间。本次实验使用的测试表test数据量为1 000万行, 使用的数据均为基准数据, 测试表结构如表 4所示,测试结果如图 6所示。
实验结果表明: 与原流程相比, 并行度从2增加到16, 随着并行度的增加, 查询响应时间不断缩短。在并行度不超过8时, 可以获得近似于线性加速比的并行执行效率, 说明在SQL语句执行过程中调度的系统资源都得到了充分的利用。然而并行度进一步增加时, 增加的资源并没有给加速比带来相应的线性提升。这是因为并行度进一步增加导致切分的任务数量大量增多, 对子请求和返回结果的处理复杂性增加。再加上线程间的调度开销和对系统资源的争用, 导致了加速比无法保持继续线性增长。
test表结构
 |
图6 TableScan算子不同并行度响应时间 |
4.3 不同数据量对TableScan性能的影响
实验数据: 本次实验使用的测试表test数据量分别为2万, 4万, 10万, 20万, 40万行, 固定并行度为4。实验结果如图 7所示。
实验结果表明: 在数据量很少时, 并行度为4的响应时间与原流程相同, 这是因为没有达到并行度生效的最低阈值, 仍然执行原流程。在20万行数据时, 并行扫描就已经开始生效, 响应时间没有达到相应的四分之一, 这是因为数据量还是较少, 分割的任务数目不够多, 线程之间任务分配不够均匀, 且线程的调度与最终的汇总存在一定的开销。在40万行数据时, 数据量足够大, 扫描数据用时占用的比重非常大, 其他开销对响应时间的影响减小, 线程之间负载也比较均匀, 因此起到了很好的并行效果。
 |
图7 TableScan算子不同数据量响应时间 |
4.4 不同并行度对Hash Join性能的影响
实验数据: 本次实验使用的测试表为test1和test2, 固定左表test1的数据量为100万行, 固定右表test2的数据量为1 000万行, 左表对右表的连接选择率为10%, 两表结构相同, 表结构和test表相同。实验结果如图 8所示。
实验结果表明: 并行度从2增加到16过程中, 连接操作响应时间呈下降趋势, 从原流程87 s降低到了7 s, 约为原来的十二分之一。依然, 在并行度不超过8时, 哈希连接的加速比接近线性, 资源增加明显提升执行效率。当并行度提升到16时, 性能提升明显小于线性加速比, 因为并行化产生的过多线程引起了系统资源争用, 执行复杂性显著上升。
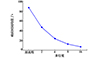 |
图8 HashJoin算子不同并行度响应时间 |
4.5 不同数据量对Hash Join性能的影响
实验数据: 本次实验使用的测试表为test1和test2, 左表test1的数据量为1万行到500万行不等, 右表test2的数据量为10万行到5 000万行不等, 固定左表对右表的连接选择率为10%, 固定并行优化的并行度为4, 实验结果如图 9所示。
实验结果表明: 当两表数据量很少时, 并行度为4的连接并未带来太多的性能提升, 在数据量达到某临界值时, 并行度为4的Hash Join优化的响应时间大幅小于原流程, 优化效果随数据量的增加而增加。这是因为数据量较小时, 如果采用优化后的流程, 数据分片及汇总等操作带来的额外开销大于采用并行带来的收益, 此时可选择采用原流程, 不开启并行优化。当数据量进一步增大, 并行优化过程中的额外开销占比越来越小, 各个线程都获得了较大的数据分片, 扫描和连接操作都同时被多个线程执行, 从而起到了很好的并行效果。
除了上述测试之外, 优化算法还进行了基准测试TPC-C和BenchMarkSQL的性能测试, 测试结果和上述结论一致, 表明并行化技术对于系统的性能有明显提升。
 |
图9 HashJoin算子不同数据量响应时间 |
5 结论
本文以金融级分布式数据库CBase为研究对象, 分析了其在表扫描与哈希连接中存在的性能瓶颈, 提出了对关键物理算子TableScan和HashJoin的并行优化方案并进行了实现。
针对TableScan算子单线程串行化表扫描响应时间过长的问题, 对原有的查询计划进行改造, 将原请求进行切分并包装为多个子请求, 开启线程池, 通过轮询方式将子请求分发到各线程中, 并行化的进行数据分片的扫描, 从而减少了数据扫描时间, 缩短了响应时间。
针对HashJoin算子中构建哈希表并探测连接导致的响应时间过长问题, 通过哈希函数将参与连接的数据分为多个分片, 采用多线程处理分片数据, 独立构建分片内部的哈希表并进行连接操作。该方式充分利用了系统计算资源, 大大提高了连接查询效率。
实验结果表明, 本文提出的策略能大幅降低单表查询和多表连接查询的响应时间, 提供更好的系统可用性。
References
- LU W, ZHAO Z, WANG X, et al. A lightweight and efficient temporal database management system in TDSQL[J]. Proceedings of the VLDB Endowment, 2018, 11(12): 2035–2046 [Google Scholar]
- HUANG D, LIU Q, CUI Q, et al. TiDB: a Raft-based HTAP database[J]. Proceedings of the VLDB Endowment, 2020, 13(12): 3072–3084 [Article] [CrossRef] [Google Scholar]
- CHARAPKO A, AILIJIANG A, DEMIRBAS M. PigPaxos: devouring the communication bottlenecks in distributed consensus[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data, 2021: 235–247 [Google Scholar]
- FUNKE H, TEUBNER J. Data-parallel query processing on non-uniform data[J]. Proceedings of the VLDB Endowment, 2020, 13(6): 884–897 [Article] [CrossRef] [Google Scholar]
- ROMANOUS B, WINDH S, ABSALYAMOV I, et al. Efficient local locking for massively multithreaded in-memory hash-based operators[J]. VLDB Journal, 2021, 30(3): 333–359 [Article] [CrossRef] [Google Scholar]
- FENTPHILIPP, NEUMANNTHOMAS. A practical approach to groupjoin and nested aggregates[J]. Proceedings of the VLDB Endowment, 2021, 14(11): 2383–2394 [Article] [CrossRef] [Google Scholar]
- FEGARAS L, NOOR H. Translation of array-based loops to distributed data-parallel programs[J]. Proceedings of the VLDB Endowment, 2020, 13(8): 1248–1260 [Article] [CrossRef] [Google Scholar]
- CONRAD A. Database of the year: postgres[J]. IEEE Software, 2021, 38(5): 130–132 [Article] [CrossRef] [Google Scholar]
- YANG Z, YANG C, HAN F, et al. OceanBase: a 707 million tpmC distributed relational database system[J]. Proceedings of the VLDB Endowment, 2022, 15(12): 3385–3397 [Article] [CrossRef] [Google Scholar]
- ZHANG Chenyu, LIU Wenjie, PANG Tianze, et al. Optimization of correlate subquery based on distributed database[J]. Journal of Northwestern Polytechnical University, 2021, 39(4): 909–919 [Article] (in Chinese) [CrossRef] [EDP Sciences] [Google Scholar]
- JING Changhong, LIU Wenjie, GAO Jintao, et al. Research and implementation of HTAP for distributed database[J]. Journal of Northwestern Polytechnical University, 2021, 39(2): 430–438 [Article] (in Chinese) [CrossRef] [EDP Sciences] [Google Scholar]
- LIU Wenjie, LI Jianbo, LI Zhanhuai, et al. A massire distribnted relational database for financial application[J]. Journal of Huazhong University of Science and Technology, 2019, 47(2): 121–126 [Article](in Chinese) [Google Scholar]
All Tables
All Figures
|
图1 CBase系统架构 |
| In the text | |
|
图2 单表查询物理计划 |
| In the text | |
|
图3 多表查询物理计划 |
| In the text | |
|
图4 并行TableScan架构 |
| In the text | |
|
图5 HashJoin并行执行框架 |
| In the text | |
|
图6 TableScan算子不同并行度响应时间 |
| In the text | |
|
图7 TableScan算子不同数据量响应时间 |
| In the text | |
|
图8 HashJoin算子不同并行度响应时间 |
| In the text | |
|
图9 HashJoin算子不同数据量响应时间 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.