| Issue |
JNWPU
Volume 43, Number 1, February 2025
|
|
|---|---|---|
| Page(s) | 119 - 127 | |
| DOI | https://doi.org/10.1051/jnwpu/20254310119 | |
| Published online | 18 April 2025 | |
Exploring non-zero position constraints: algorithm-hardware co-designed DNN sparse training method
探索非零位置约束:算法-硬件协同设计的DNN稀疏训练方法
School of Computer Science, Northwestern Polytechnical University, Xi'an 710072, China
Received:
9
October
2024
Abstract
On-device learning enables edge devices to continuously adapt to new data for AI applications. Leveraging sparsity to eliminate redundant computation and storage usage during training is a key approach to improving the learning efficiency of edge deep neural network(DNN). However, due to the lack of assumptions about non-zero positions, expensive runtime identification and allocation of zero positions and load balancing of irregular computations are often required, making it difficult for existing sparse training works to approach the ideal speedup. This paper points out that if the non-zero position constraints of operands during training can be predicted in advance, these processing overheads can be skipped to improve sparse training energy efficiency. Therefore, this paper explores the position constraint rules between operands for three typical activation functions in edge scenarios during sparse training. And based on these rules, this paper proposed a parev hardware-friendly sparse training algorithm to reduce the computation and storage pressure of the three phases, and an energy-efficient sparse training accelerator that can be executed in parallel with the forward propagation computation to estimate the non-zero positions so that the runtime processing cost is masked. Experiments show that the proposed method is 2.2 times, 1.38 times and 1.46 times more energy efficient than dense accelerator and two other sparse training tasks respectively.
摘要
设备上的学习使得边缘设备能连续适应人工智能应用的新数据。利用稀疏性消除训练过程中的冗余计算和存储占用是提高边缘深度神经网络(deep neural network, DNN)学习效率的关键途径。然而由于缺乏对非零位置的假设, 往往需要昂贵的代价用于实时地识别和分配零的位置以及对不规则计算的负载均衡, 这使得现有稀疏训练工作难以接近理想加速比。如果能提前预知训练过程中操作数的非零位置约束规则, 就可以跳过这些处理开销, 从而提升稀疏训练性能和能效比。针对稀疏训练过程, 面向边缘场景中典型的3类激活函数探索操作数之间的位置约束规则, 提出: ①一个硬件友好的稀疏训练算法以减少3个阶段的计算量和存储压力; ②一个高能效的稀疏训练加速器, 能预估非零位置使得实时处理代价被并行执行掩盖。实验表明所提出的方法比密集加速器和2个其他稀疏训练工作的能效比分别提升了2.2倍, 1.38倍和1.46倍。
Key words: sparse training / non-zero position constraint / DNN / sparse accelerator
关键字 : 稀疏训练 / 非零位置约束 / DNN / 稀疏加速器
© 2025 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
设备上的DNN学习具有多方面的必要性和优势[1–5], 尤其是涉及到航空系统的效率、安全性和响应能力。传统学习模式下, 使用远程服务器在大型数据集上训练DNN之后, 预训练的模型被部署在边缘设备上进行实时推理。然而, 航空系统中由于对实时响应决策和数据隐私安全的极大需求, 传统学习模式不能满足其要求。设备上学习允许飞机或无人机上的计算设备实时处理数据, 及时识别和响应潜在的危险情况, 如引擎故障、气流异常等。设备上学习减少了数据传输到服务器的需求, 从而减少了数据泄露的风险[1, 4–5]。
面向资源约束的边缘设备和设备上学习的资源高需求之间的矛盾, 神经网络中普遍存在的稀疏性已经被广泛利用来设计高效的稀疏训练算法和硬件加速器[6–13]。然而, 目前的稀疏训练加速器的实际加速比距离理想加速比还有很大的差距。稀疏性虽然带来了大量的计算缩减和存储需求降低, 但是往往需要付出昂贵的代价来实时处理稀疏性带来的问题。本文观察到现有加速器难以接近理想加速比的原因是: 由于没有任何对于零的位置的假设, 需要额外且昂贵的代价用于实时地识别和分配零的位置, 以及对不规则计算的负载均衡。即使DNN模型的操作数稀疏度很大, 但是在处理稀疏性的时候往往需要昂贵的硬件结构来维护无约束的具有任意稀疏度的操作数计算, 这些硬件结构使得稀疏性获得的好处被极大掩盖。一些处理结构性稀疏模式的DNN稀疏训练加速器能够将这些硬件代价转移到软件处理(即需要进行结构化的剪枝)。但是他们往往只支持一种或某几种固定稀疏度的处理并且需要进一步训练来恢复精度。
针对上述问题, 本文从DNN的稀疏性来源入手进行分析, 通过外部输入、内部计算产生和激活函数产生三方面,研究操作数之间的非零值位置约束规则。这些约束规则使得硬件更容易识别非零值的位置并将它们均匀地分布到并行硬件组件, 能够兼顾稀疏训练的灵活性和高效性。接着基于发现的非零位置约束规则, 采用算法和硬件协同设计的方法缓解设备上训练和资源受限的边缘设备之间的矛盾。
本文主要贡献如下:
1) 针对稀疏训练过程, 从外部输入、内部计算产生和激活函数产生三方面探索稀疏性的来源, 提出基于激活函数的操作数之间的非零位置约束规则;
2) 面向边缘场景中典型的3类激活函数, 分别提出硬件友好的稀疏训练算法, 不仅跳过了无效的梯度计算, 还能在操作数之间共享掩码和指示信息, 提升训练效率;
3) 为支持稀疏训练算法, 提出了一个能高效利用非零约束规则的稀疏训练加速器, 其在前向计算时进行梯度预估使得昂贵的实时稀疏处理代价被并行的计算掩盖;
4) 和密集训练加速器相比, 本文提出的训练方法最多减少58%的计算量和32%的存储占用。与密集训练和其他稀疏训练工作相比, 本文的能效比分别提升了2.2倍, 1.38倍和1.46倍。
1 相关工作和动机
1.1 训练过程
如图 1所示, 以ResNet为例, 相比于推理, 训练过程需要更多的计算和存储资源。
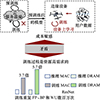 |
图1 成本敏感的边缘设备和设备上学习的资源高需求之间的矛盾 |
这是因为DNN的训练过程分为3个阶段: FP(前向推理), BP(反向传播)和WU(权重更新)。首先, 通过一些隐藏层(激活X和权重W的卷积层、全连接层和激活层等)从输入图像中提取出数据激活特征, 如图 2a)所示。接着一层一层地往后传递并在分类步骤之后计算最终损失。BP是传播损失的过程, 通过输入损失梯度∂X和转置过的权重W的卷积操作来获得输出损失梯度, 接着从后往前一层一层地传输损失梯度。最后在WU阶段, 损失梯度∂X和激活O卷积计算得到每一层的权重梯度, 并进行更新。
 |
图2 DNN训练过程 |
1.2 相关工作
对于资源受限的边缘设备, 许多稀疏加速器致力于利用结构或者非结构的稀疏性来加速训练过程。其中非结构稀疏加速器[6–9, 12–13]支持操作数中零的位置是无规则不受约束的排布, 因此需要昂贵的处理代价。例如文献[9]使用复杂的数据互联和硬件调度器来实时提取激活、权重和梯度中的稀疏性, 来支持任何稀疏度的DNN训练加速。文献[8]采用前缀和逻辑来识别非零计算, 然而占据了总面积的55%。文献[12]使用复杂的数据打包方式来收集和分发非零值。由于不能对非零位置做任何假设, 非结构稀疏的硬件架构处理时需要额外且昂贵的代价来识别和分配零的位置, 并且也不能很好地负载均衡。
结构稀疏加速器[10–11]支持操作数中零的位置以一种规则的模式排布(一般由人为的结构化剪枝操作获得, 不能支持所有稀疏度, 并且往往有精度下降的风险)。英伟达[10]采用2∶4(仅支持50%的稀疏度)的一种固定稀疏度进行稀疏训练。文献[11]利用具有约束的G∶8(仅支持特定几种稀疏度)稀疏模式进行训练加速。虽然支持结构化稀疏的硬件架构在处理的时候, 由于非零位置的提前约束, 减少了识别和分配非零值的处理代价, 往往能够获得比非结构化稀疏硬件更高的能效比,但是其对非零的强制约束使其需要通过额外训练迭代来恢复精度, 并且其对稀疏度的支持非常有限, 这不满足目前DNN稀疏度多样化的需求。
本文分析得到结构稀疏硬件之所以高效是因为对非零值位置的预定约束使得硬件更容易识别非零值的位置并将它们均匀地分布到并行硬件组件。这激励本文在非结构稀疏性下探索操作数之间自然的非零位置约束, 这样就可以兼顾灵活的稀疏度和高能效。也就是说如果能得到操作数之间的稀疏性的相互约束, 不仅能低开销地跳过无效计算, 而且能够在不影响精度的情况下支持不同的稀疏度。因此本文通过分析3个训练阶段的稀疏性来源来研究非零位置约束, 并据此提出高效灵活的稀疏训练算法和加速器架构。
2 稀疏性利用方法
2.1 稀疏性来源分析
本小节通过观察稀疏来源来分析训练过程中的非零位置约束规则。面向边缘环境, 目前典型DNN模型中普遍存在的操作单元为卷积(或者其变体)加激活函数的模式, 常用的激活函数是类ReLU的一些激活函数: ReLU, LeakyReLU(LReLU) 和ReLU6等。因此, 将卷积加激活函数的结构作为本文的研究单元, 如图 3所示。
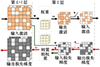 |
图3 本文的研究单元——卷积加激活函数的计算结构 |
具体地, 对于该结构来说稀疏性来源于两部分: 外部输入和内部操作生成。其中外部输入是由上一层的激活(FP)或者损失梯度(BP)作为输入操作数将稀疏性传入该单元的, 一般零值处于无约束状态, 因此不能提前得到某一操作数稀疏模式。卷积计算可以分为矩阵乘法和累加操作。由于零值乘法规则, 输出操作数可以继承输入操作数的稀疏模式(零乘任何数仍然为零)。然而经过累加操作后会失去这一继承关系, 因此不能提前得到某一操作数的稀疏模式。激活函数对输入激活进行缩放得到本层的输出激活。
如图 4所示, 不同激活函数的前向传播规则和反向传播规则都是不同的。对于ReLU来说, 前向时激活值通过ReLU将保留大于0的激活值, 而将小于0的值映射为0。反向时, 只保留激活值大于0的区间的损失梯度, 将其余位置的损失梯度映射为0作为输入损失梯度继续向前传递, 即在绿色圈的区间激活值变化时输入损失梯度值改变不敏感。这会导致前向输入激活的稀疏模式和反向输入损失梯度的稀疏模式相同。也就是说每次训练过程中, 前向计算完成后就能够获得每一层反向时的输入损失梯度的稀疏模式。
 |
图4 3类典型的激活函数的前向和反向传播规则 |
对于ReLU6来说, 前向时将保留0~6区间内的值, 将小于0的值映射为0, 大于6的值映射为6。反向时保留激活值在0~6区间内的对应位置损失梯度, 而将其余位置的损失梯度映射为0,组成输入损失梯度继续向前传播。这会导致前向输入激活的稀疏模式和反向输入损失梯度的稀疏模式部分相同(激活值小于6的部分)。
和ReLU不同的是,LReLU前向时将小于0的激活值乘以α(一般取值较小, 比如0.1或0.2)而不是直接映射为0。反向时该区间的梯度值要乘以α作为输入损失梯度继续传递。因此, LReLU并不像ReLU和ReLU6一样直接能够提前识别某些操作数的零值位置。
此外, 一些典型的DNN会在卷积操作和激活函数之间插入批量归一化操作(BatchNormlization)来标准化激活, 不但能够加速训练过程还能提高模型的稳定性。批量归一化分为2步, 首先是对激活X标准化得到中间激活X′接着是缩放移位得到最终激活Y。根据缩放移位的反向传播规则, X′的梯度稀疏模式会继承Y的梯度稀疏模式, Y的梯度稀疏模式遵从上述分析得到的特征。标准化的反向传播会损失一部分梯度稀疏性并且使得X的梯度稀疏模式失去规则性。因此, 加入批量归一化操作之后中间激活损失梯度X′和最终损失梯度Y的零值位置能够完全ReLU或者部分ReLU6被提前识别。
总之, 对于本文的研究单元来说, 有规则的稀疏性主要通过激活函数的前向映射和反向映射得到。这些规则的稀疏性可以被用来设计高效的稀疏训练方法和与其相适配的硬件加速器架构。
2.2 稀疏性训练算法
本小节给出根据以上分析得到的针对3种激活函数的研究单元的稀疏训练方法。
1) 对于ReLU来说, 前向的输入激活和反向的输入损失梯度之间具有相同的稀疏模式。因此, 在前向时就能得到输入损失梯度的稀疏模式, 从而节省了反向时对0的识别过程。更重要的是, 可以根据这个稀疏模式掩码来选择性地计算输出损失梯度值, 这能跳过大量的无效计算(每个位置都对应多个矩阵乘法和跨通道的累加计算)。因为输出损失梯度的这些位置(即稀疏模式掩码为0的位置)在经过ReLU的反向映射之后注定为零, 因此可以安全地跳过而不影响精度, 如算法1所示。
算法1 使用ReLU激活函数的稀疏训练算法
针对ReLU函数的研究单元, 以第L层为例
输入: 第L层的激活总数M, 输出激活X, 输入激活O, 输出损失梯度∂O, 输入损失梯度∂X, 稀疏模式掩码Mask;
FP阶段:
for j=0;j < =M; j++
if X[j] < 0 then Mask-O[j]=0;
else Mask-O[j]=1;
end if
end for
BP阶段:
for j=0; j < =M; j++
if Mask-O[j]=0 then跳过∂O[j]的计算而直接映射为零, 并且∂X[j]和O[j]共享Mask存储;
else计算∂X[j];
end if
end for
2) 对于ReLU6来说, 不能直接用前向时获得的稀疏模式掩码来直接指导反向的选择性计算。本文将激活值在0~6区间内的值对应的位置设置为1, 其他位置设置为0共同组成指示信息。该指示信息和输入损失梯度的稀疏模式一致。因此可以用来指导反向传播时对输出损失梯度的选择性计算, 如算法2所示。
算法2 使用ReLU6激活函数的稀疏训练算法
针对ReLU6函数的研究单元, 以第L层为例
输入: 第L层的激活总数M, 输出激活X, 输入激活O, 输出损失梯度∂O, 输入损失梯度∂X, 指示信息IN, 稀疏模式掩码Mask;
FP阶段:
for j=0; j < =M; j++
if 0 < =X[j] < =6 then IN-X[j]=1;
else IN-X[j]=0;
end if
end for
BP阶段:
for j=0; j < =M; j++
if IN-X[j]=0 then跳过∂O[j]的计算而直接映射为零, 并且Mask-∂X[j]和IN-X[j]共享存储;
else计算∂O[j];
end if
end for
3) 对于LReLU来说, 没有能够直接识别零值位置具有规则的稀疏性。一般来说, α为一个较小的值, 因此在反向映射时该绿色区间对应位置的输入损失梯度也大概率较小(由输出损失梯度乘以α计算得到)。一般来说绝对值较小的梯度值相对于绝对值大的梯度值对于权重更新更加不重要。因此本文概率性地将该区间对应的梯度值设置为0以降低计算量, 从而组成指示信息作为输入损失梯度的稀疏模式掩码并选择性地计算输出损失梯度值, 如算法3所示。
算法3 使用LReLU激活函数的稀疏训练算法
针对LReLU函数的研究单元, 以第L层为例
输入: 第L层的激活总数M, 输出激活X, 输入激活O, 输出损失梯度∂O, 输入损失梯度∂X, 指示信息IN;
FP阶段:
for j=0; j < =M; j++
Random-Temp=Rand () %10;//生成0~9的随机数
if X[j] < 0 & & Random-Temp < =7 then
IN-X[j]=0;
else IN-X[j]=1;
end if
end for
BP阶段: //和ReLU6函数的BP阶段相同
另外, 本文发现池化(Pooling)和聚合(ADD)操作的前向和反向之间也具有规则的稀疏性。虽然不涉及跳过计算, 但是可以通过共享掩码减少存储压力。具体地, 对于最大池化操作来说, 由于梯度传播规则, 前向时保存的最大位置掩码矩阵(即最大值所在的像素点为1, 其他像素点为0)和反向时的损失梯度具有相同的稀疏模式。因此可以进行共享而减少存储占用。类似地,对于add操作, 前向时激活和反向时的输入和输出损失梯度具有相同的稀疏模式, 因此也可以进行共享。
针对以上提出的针对不同激活函数的3种稀疏训练算法, 本小节给出具体的稀疏优化策略。首先,由于权重的稀疏度很小,因此本文选择具有较大稀疏度的激活和梯度作为单边稀疏训练的目标操作数,这样能够尽可能多地跳过无效计算。其次, 对于使用ReLU作为中间层激活函数的模型, 使用前向时的激活的掩码作为反向时的指示信息选择性计算损失梯度值, 跳过那些注定在下一步将会映射为0的损失梯度。对于ReLU6和LReLU来说, 使用前向时获得指示信息选择性地计算损失梯度, 以跳过无意义计算。最后, 对于3类激活函数中具有规则稀疏模式的操作数, 可以通过共享存储减少无效数据的存储和传输, 以缓解存储压力。
3 稀疏训练加速器
3.1 架构总述
为了支持上一节中提出的针对不同激活函数的稀疏训练方法, 本节提出了一个能够有效预估梯度稀疏模式进而跳过无用的计算和减少稀疏处理成本的稀疏训练加速器(sparse training accelerator with position constraint, STAPC)。架构如图 5所示, 包括1个PE处理阵列用来进行稀疏的矩阵乘法计算, 1个输入缓存来存储激活值和梯度值(包括损失梯度和权重梯度), 1个权重缓存用来存储权重, 1个输出缓存, 1个部分和累加单元用来累加和缓存PE阵列计算得到的部分和, 接着ReLU-V单元来处理3类不同的激活函数并进行压缩存储, 将梯度掩码值和用于选择性计算的指示信息分别存储在掩码缓存器和指示信息缓存器中。另外重排序单元用来缓解稀疏计算带来的负载不均衡的情况。
 |
图5 本文提出的稀疏训练加速器架构 |
具体地, 每个PE阵列包括4个PE单元, 每个单元包括64个MAC。由于本文提出的稀疏训练算法针对输出梯度的像素点, 采用输出固定的数据流模式进行计算。计算时操作数都是被压缩存储, 解码之后选择对应的非零数据对分发到每个PE进行计算。图 5中用箭头展示了权重激活和激活梯度等操作数的数据传播方式。为了减少数据传输引起的能量消耗, 激活数据进行水平方向的重用, 并且每个PE列针对特定的输出通道进行计算。在相同的PE列中, 不同的PE加载不同输入通道的激活和权重的数据块, 输出的部分和将被垂直累加到部分和累加单元得到最后的输出。
训练过程中操作数都是被压缩存储, 解码之后根据掩码选择对应的非零数据块发送到每个PE进行计算。计算完成后再将输出进行压缩存储以节省存储空间。本文采用解耦的压缩方法对数据进行压缩, 即非零值部分和掩码部分被分别存储在输入缓存和掩码缓存中。
3.2 预估梯度稀疏模式的工作流
本节以ReLU6的某一层为例说明利用预估梯度稀疏模式来进行训练加速的工作流。
1) 前向计算激活时, 卷积运算经过PE阵列通过累加单元累加后得到本层的输出激活。将激活送入ReLU-V单元, 一方面得到输出激活的稀疏模式掩码(存入Mask buffer)和非零值(存入Input Buffer), 另一方面通过比较并和稀疏模式掩码进行异或得到指示信息。如图 6所示, 最终获得的指示信息中的零位置代表该位置的激活值小于0或者大于6, 1代表该位置的激活值在0~6之间;
 |
图6 用于生成掩码信息和非零位置指示信息的微架构 |
2) 反向计算损失梯度时, 取出第一步存储的Mask值和指示信息值。其中指示信息值用来指导加速器移除无效的输出损失梯度计算, 即指示信息中指示为0的位置对应的卷积计算可以安全跳过而不影响精度。而Mask值用来选择对应的权重值和非零输入损失梯度相乘。
3) 反向计算权重梯度时, 使用Mask值选择对应的激活值和非零输入损失梯度相乘。
此外, 对于ReLU来说, Mask和指示信息是相同的, 因此使用Mask信息不仅能用来移除无效的输出损失梯度值计算, 还可以在3个训练阶段去选择对应的非零数据对。因此, 在Mask buffer和IN buffer全部用来存储Mask值。对于LReLU来说, 本文使用一个随机数生成器(RNG)概率性地将小于0的区间的梯度值设置为0从而得到指示信息, 指示加速器在维持精度的情况下减少梯度计算量。这些Mask和IN信息的共享减少了无效数据的存储和移动, 降低了能量消耗。
由于使用Mask进行非零对选择时, 每个PE对应的工作负载密度不一致, 这会导致不均衡的PE利用率从而导致性能下降。通过对不同的权重filter进行排序, 使得具有类似工作负载量的数据块被安排在同一个PE阵列上进行计算(即选择具有相似负载的输出通道在同一批次进行计算), 这样可以缓解因为每个PE利用率不同而导致的无效等待问题。一般这个过程需要实时进行, 因为只有得到操作数的非零数之后才能进行。
注意在进行和梯度相关计算时, 由于在前向时就能预估出稀疏模式, 在反向传播时不需要实时地识别非零值的位置并进行分配。由于提前得知了梯度的稀疏模式, 重排序单元可以和前向并行地执行,对权重进行排序并暂存排序结果以在反向需要时取出进行负载均衡。这些原本需要实时进行的稀疏处理工作被前向计算所掩盖, 缩短了训练延时并降低了能量消耗。
4 实验评估
本文构建了一个评估模型对稀疏加速器架构进行建模, 从而对性能和功耗进行灵活高效的评估。本文采用4个适用于边缘学习场景的DNN模型: ResNet-18(ReLU), SqueezeNet(ReLU), MobileNetv2(ReLU6), ResNet-L(LReLU), 并采用ImageNet-1000作为数据集进行评估。学习率采用0.01, 并且每30个epoch衰减为原来的十分之一。
参与评估的加速器架构: ①Baseline: 密集训练加速器, ②ST[12]: 1个单边非结构稀疏训练加速器, 利用权重(FP和WU)和梯度(BP)的稀疏性加速训练; ③SCG[13]: 1个单边非结构稀疏训练加速器, 其仅在BP阶段选择性计算梯度来减少训练所需计算量。④STAPC: 本文提出的利用非零位置约束的单边稀疏训练加速器STAPC。
4.1 计算量和存储占用
如图 7所示, 分训练阶段给出和Baseline相比本文提出的稀疏训练方法的浮点计算量和计算减少百分比,其中w/o PC(position constraint)表示不利用非零位置约束规则的情况, 和Baseline相比本文提出的方法分别能节省48%, 58%, 51%和21%的计算量。在梯度传播阶段利用PC要比不利用PC的稀疏训练方法减少12.5%的计算量。PC的利用与稀疏度相关, 即梯度稀疏度越大则具有PC的位置就有更大概率越多,因此也能获得更大的缩减。
 |
图7 和Baseline相比本文方法获得的MAC计算量的减少 |
由于LReLU会导致激活稀疏性很小, 和神经网络相比ResNet-L的计算缩减率较小。图 8展示了和Baseline相比, 训练过程中本文提出方法的存储占用情况。由于压缩信息在不同训练阶段之间共享, 此处给出总的存储占用而不是分阶段的。DNN中自然存在的稀疏性使得不利用PC时的存储占用分别减少了11%, 25%, 13%和6%。此外, 利用PC时的存储占用分别减少了17%, 32%, 18%和9%。
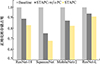 |
图8 和Baseline相比本文获得的存储占用减少 |
4.2 和其他稀疏训练工作相比
为了公平地比较, 所有加速器使用相同数量的MAC单元和存储空间。图 9给出了和Baseline相比, 其他工作和本文提出的稀疏训练加速器所获得的加速比和能效比。
 |
图9 与Baseline和其他工作相比,STAPC所获得的正则化的加速比和能效比 |
在4个DNN模型上, STAPC均获得了最大的加速比和能效比(1.51倍, 2.2倍, 1.56倍和1.15倍)。高能效比来源于本文发现的非零位置约束规则不但跳过了更多的冗余计算和无效数据移动, 还高效共享了存储减少了存储占用。这验证了协同设计稀疏训练算法和加速器架构的好处。注意, ST和SCG不支持ReLU6和LReLU这2个激活函数, 因此不列出MobileNetv2和ResNet-L的相关数据。
4.3 面积和能耗
本文使用Synopsys Design Compiler在台积电45 nm standard cell综合STAPC, 门级网表使用Verilog语言。STAPC的面积开销为9.1 mm2, 功耗为350 mW, 具体明细开销如图 10所示。其中用于支持本文提出训练方法的存储单元(Mask Buffer和IN Buffer)面积占比为21%, 功耗占比为13.9%。此外, 与Baseline相比, STAPC需要额外11.2%的面积开销和9.4%的功率用于稀疏训练支持。
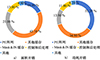 |
图10 面积和功耗开销明细 |
5 结论
本文通过对DNN训练过程进行稀疏性来源分析, 挖掘操作数之间存在的非零位置约束。基于这种约束规则, 本文提出一种算法硬件协同设计方法加速稀疏训练效率,缓解训练的高需求和资源受限的边缘设备之间的矛盾。稀疏训练算法能够利用掩码或者指示信息跳过无效的梯度计算,提升训练速度。稀疏训练加速器对梯度的非零位置预估使得原本昂贵的稀疏处理成本能够被并行掩盖并进行掩码重用,降低能量消耗。与Baseline和其他稀疏训练工作相比, 本文的能效比分别提升了2.2倍, 1.38倍和1.46倍。
References
- LEE J, KANG S, LEE J, et al. The hardware and algorithm co-design for energy-efficient dnn processor on edge/mobile devices[J]. IEEE Trans on Circuits and Systems, 2020, 67(10): 3458–3470. [Article] [Google Scholar]
- CHOI S, SHIN J, KIM L S. A convergence monitoring method for DNN training of on-device task adaptation[C]//2021 IEEE/ACM International Conference on Computer Aided Design, 2021: 1–9 [Google Scholar]
- CHOI S, SHIN J, KIM L S. Accelerating on-device DNN training workloads via runtime convergence monitor[J]. IEEE Trans on Computer-Aided Design of Integrated Circuits and Systems, 2023, 42(5): 1574–1587. [Article] [Google Scholar]
- WANG Z H. Efficient on-device incremental learning by weight freezing[C]//2022 27th Asia and South Pacific Design Automation Conference, 2022: 538–543 [Google Scholar]
- LI B. DQ-STP: an efficient sparse on-device training processor based on low-rank decomposition and quantization for DNN[J]. IEEE Trans on Circuits and Systems, 2024, 71(4): 1665–1678. [Article] [Google Scholar]
- LU J, HUANG J, WANG Z. Theta: a high-efficiency training accelerator for dnns with triple-side sparsity exploration[J]. IEEE Trans on Very Large Scale Integration Systems, 2022, 30(8): 1034–1046 [Google Scholar]
- YANG D, GHASEMAZAR A, REN X, et al. Procrustes: a dataflow and accelerator for sparse deep neural network training[C]//2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture, 2020: 711–724 [Google Scholar]
- GONDIMALLA A, et al. SparTen: sparse tensor accelerator for convolutional neural networks[C]//Proceedings of the 52nd Annual IEEE/ACM International Symposium on Micnarchitecture, 2019: 151–165 [Google Scholar]
- MAHMOUD M, EDO I, ZADEH A H, et al. Tensordash: exploiting sparsity to accelerate deep neural network training[C]//2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture, 2020: 781–795 [Google Scholar]
- NVIDIA. NVIDIA ampere GA102 GPU architecture whitepaper[EB/OL]. (2020-09-16)[2024-10-09]. https://www.nvidia.com/content/PDF/nvidia-ampere-ge-102-gpu-architecture-whitepaper-v2.pdf [Google Scholar]
- LIU Z, WHATMOUGH P N, ZHU Y, et al. S2TA: exploiting structured sparsity for energy-efficient mobile CNN acceleration[C]//2022 IEEE International Symposium on High-Performance Computer Architecture, 2022: 573–586 [Google Scholar]
- WANG M, FAN X, ZHANG W, et al. Balancing memory-accessing and computing over sparse DNN accelerator via efficient data packaging[J]. Journal of Systems Architecture, 2021, 117(C): 102094. [Article] [Google Scholar]
- LEE G, PARK H, KIM N, et al. : Acceleration of DNN backward propagation by selective computation of gradients[C]//2019 56th ACM/IEEE Design Automation Conference, 2019: 1–6 [Google Scholar]
All Figures
|
图1 成本敏感的边缘设备和设备上学习的资源高需求之间的矛盾 |
| In the text | |
|
图2 DNN训练过程 |
| In the text | |
|
图3 本文的研究单元——卷积加激活函数的计算结构 |
| In the text | |
|
图4 3类典型的激活函数的前向和反向传播规则 |
| In the text | |
|
图5 本文提出的稀疏训练加速器架构 |
| In the text | |
|
图6 用于生成掩码信息和非零位置指示信息的微架构 |
| In the text | |
|
图7 和Baseline相比本文方法获得的MAC计算量的减少 |
| In the text | |
|
图8 和Baseline相比本文获得的存储占用减少 |
| In the text | |
|
图9 与Baseline和其他工作相比,STAPC所获得的正则化的加速比和能效比 |
| In the text | |
|
图10 面积和功耗开销明细 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.