| Issue |
JNWPU
Volume 38, Number 5, October 2020
|
|
|---|---|---|
| Page(s) | 1030 - 1037 | |
| DOI | https://doi.org/10.1051/jnwpu/20203851030 | |
| Published online | 08 December 2020 | |
A Time Series Prediction Approach Based on Hybrid Tuning for Database Performance Indicator in AIOps
一种基于综合调优的数据库性能趋势预测方法
1
School of Computer, Northwestern Polytechnical University, Xi'an 710072, China
2
Key Laboratory of Big Data Storage and Management, Ministry of Industry and Information Technology, Xi'an 710072, China
3
Bank of Communication, Shanghai 310115, China
Received:
5
November
2019
Abstract
One of the most important applications of the intelligent operation and maintenance of a cloud database is its trend prediction of key performance indicators (KPI), such as disk use, memory use, etc. We propose a method named AutoPA4DB (Auto Prophet and ARIMA for Database) to predict the trend of the KPIs of the cloud database based on the Prophet model and the ARIMA model. Our AutoPA4DB method includes data preprocessing, model building, parameter tuning and optimization. We employ the weighted MAPE coverage to measure its accuracy and use 6 industrial datasets including 10 KPIs to compare the AutoPA4DB method with other three time-series trend prediction algorithms. The experimental results show that our AutoPA4DB method performs best in predicting monotonic variation data, e.g.disk use trend prediction. But it is unstable in predicting oscillatory variation data; for example, it is acceptable in memory use trend prediction but has poor accuracy in predicting the number of database connection trends.
摘要
云数据库智能运维中的重要应用场景之一是对监控采集的大量性能时序数据进行趋势预测。提出一种基于Prophet模型和ARIMA模型的综合调优智能趋势预测方法AutoPA4DB(auto prophet and ARIMA for database)。该方法根据数据库性能监控数据的特征,进行了原始监控数据的预处理、预测模型自动调参和模型优化。采用加权的时序预测准确性度量WMC(weighted MAPE coverage),基于多个企业级数据库实例(包含10种性能指标)进行了实验验证。实验对比了5种不同时序模型的预测效果,结果表明在单调变化模式(如磁盘使用量)的数据中,文中提出的AutoPA4DB方法时序预测准确性最高;然而在震荡模式的数据中,预测效果不太稳定,例如内存使用率趋势预测效果较好,但数据库连接数趋势预测效果不理想。
Key words: intelligent operation and maintenance / time series / prophet / ARIMA / database performance monitor
关键字 : 智能运维 / 时序数据 / Prophet模型 / ARIMA模型 / 数据库性能监控
© 2020 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
近年来,智能运维[1-2]受到了工业界和学术界的广泛关注。智能运维是指在自动化运维的基础上增加一个基于机器学习的大脑,指挥监测系统采集大脑决策所需的数据,做出分析、决策并指挥自动化脚本去执行大脑的决策,从而达到运维系统的整体目标。智能运维的主要应用场景包括:趋势预测、异常检测、预警管理、故障处理以及智能推荐等。在数据库(database, DB)运维的智能化过程中,云数据库[3]作为数据管理领域的新型数据库发展迅速,积极推动着运维的智能化进程。
本文以云数据库智能运维中的性能时序数据变化趋势预测展开研究。时序数据是指按照时间顺序采集的数据序列。它通常是在相等间隔的时间段内,依照给定的采样率,对某种潜在过程进行观测的结果[4]。Jan等[5]总结了传统时序预测的各种模型和方法,包括传统的差分自回归移动平均模型(ARIMA),指数平滑模型等。ARIMA模型[6]同大部分传统时序预测模型相同,一般先对非平稳序列进行差分处理直到序列平稳,本质是适用于平稳序列的模型。建立ARIMA模型通常包括模型定阶,参数估计和模型检验3个步骤。Facebook公司在2018年公开了其最新的时序预测框架Prophet[7],该模型是一个可分解的时间序列预测模型,包含趋势性、季节性和假期性3个主要组件。该模型对趋势性、周期性较强的数据预测效果较好,对节假日和突变点有很强的适应力,对时间序列的平稳性没有要求,易于使用,其形式化描述如公式(1)所示。
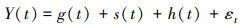 1
1
式中:g(t)表示趋势函数,模拟时间序列值的非周期性变化;s(t)表示周期性变化(如每周/年等的季节性);h(t)表示不定期假期的影响;最后的误差项表示不适用前3项的任何特殊变化。
云数据库监测的数据库实例指标通常包括磁盘使用量、内存使用率、CPU使用率、数据库连接数、网络IO字节数等,可以通过预测这些性能指标在未来一段时间内(如1个月内)的趋势变化,帮助运维人员及时调整云资源,使得资源配置最优,有效节约运维成本。本文针对数据库运维性能指标时序数据提出了一种针对性更强的AutoPA4DB预测方法。该方法以Prophet算法和ARIMA算法为基础,针对数据库监控指标的数据特点进行了综合优化。本文在6个企业级数据库实例数据集上和6个竞赛数据库实例数据集上分别进行了实验验证,结果表明AutoPA4DB模型在磁盘使用量、内存使用率、CPU使用率等部分性能指标趋势性预测中的预测准确度较高,且预测准确度高于优化前模型和其他对比模型。但在TPS(每秒处理的事物数)及数据库连接数等指标中,预测效果并不理想。
1 性能趋势预测方法AutoPA4DB
1.1 方法概述
图 1描述了本文提出的基于Prophet和ARIM-A模型的数据库性能指标综合趋势预测方法AutoP-A4DB的基本框架。图中粗斜体部分是本文重点优化的部分。主要分为数据预处理、数据建模与预测以及动态调参优化三大部分。图 2和图 3展示了使用本方法得到的2种性能指标预测结果。
 |
图1 AutoPA4DB框架图(粗体字部分为本文优化内容) |
 |
图2 磁盘使用量/GB趋势预测图 |
 |
图3 内存使用率/%趋势预测图 |
1.1.1 数据预处理
数据预处理过程包括数据抽样、异常检测[8]、异常值处理、缺失值处理以及数据变换。
1) 数据抽样
由于各种数据库监测平台采集性能数据的时间间隔可能不同,本方法可按照统一的方式按指定时间间隔抽样,例如1分钟, 30分钟, 60分钟等。
2) 异常检测与处理
异常值通常会改变KPI曲线的形状,进而影响趋势预测,因此需要检测并去除异常点。图 4以DS1中的CPU使用率为例展示了异常值分布情况。本文利用常见的箱型图方法进行异常值检测,并将检测出的异常值设为缺失值。
 |
图4 DS1中CPU利用率异常点分布 |
3) 缺失值处理
由于Prophet算法已经包含了关于缺失值的填充处理,本文仅在采用ARIMA方法时针对缺失值通过拉格朗日插值法进行填充。
4) 数据变换
为了使数据更加平稳,本文采用对数变换的方法对原始数据进行变换。
由于不同的数据预处理方法以及各种预处理组合对最终的预测准确度有一定的影响,本文的AutoPA4DB中采用基于1.1.3小节的动态调参的思想对各种预处理组合进行了动态组合调优,具体每种预处理涉及的可调节参数参考第3.2小节。
1.1.2 数据建模与预测
在数据建模与预测中,首先分别基于Prophet模型和ARIMA模型进行建模。在建模过程中,针对数据库监控性能指标数据的特征对Prophet模型进行了优化(参见第2小节)。此外,为了提高预测模型度量的可靠性,本方法采用了与Prophet模型一致的时序交叉验证的方法,将多次时序交叉验证的模型准确性度量平均值作为整个模型的预测准确性。最后,基于自动调优得到的最优模型进行数据库性能指标数据的趋势预测。
1.1.3 动态调参优化
为了获得最优预测结果,机器学习中通常需要进行参数调优。常见的调参方式是网格搜索、随机搜索和贝叶斯搜索。网格搜索速度较慢,随机搜索虽然速度快,但是可能错过重要参数值,本方法使用了基于贝叶斯优化[9]的Hyperopt调参技术。该调参方法将待调参数以及其取值范围设定为参数空间,在参数空间中选择并组合,通过最小化损失函数寻找最佳参数组合。本文调参中的损失函数为公式(4)定义的预测准确性度量WMC(公式中用WMC表示)。当目标函数的返回值最小时,对应的各个参数值则为模型的最佳参数。
1.2 模型预测准确度评估
时序数据趋势预测模型的准确性度量通常包括均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE)。由于MAPE的易理解性,本文采用加权的时序预测准确性作为预测模型的预测准确性度量标准。MAPE在公式中采用EMAP形式表示真实值与预测值之间的绝对误差占真实值的百分比,覆盖率C表示真实值落入预测值的上下界范围内的数据个数占总数据数的百分比。具体如公式(2)~(4)所示:
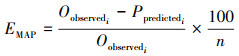 2
2
式中:observed表示观察值;predicted表示预测值。EMAP值越小, 表示预测误差越小, 模型越好。
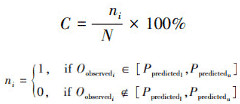 3
3
式中:predictedl表示预测值的下界;predictedu表示预测值的上界; N表示总数据点个数。C值越大, 表示覆盖率越高, 模型越好。
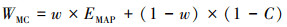 4
4
式中:w表示MAPE所占权重。由于对于预测模型而言, 误差MAPE更加重要, 因此本文中测试了w取值分别为0.5, 0.6, 0.7, 0.8的情况, 结果表明为对本文所有实验数据, w=0.8时预测效果更符合预期。在应用于其他数据集时, 可根据具体情况考虑w的取值。
2 预测模型优化
本部分面向数据库监控性能指标趋势预测的具体问题和具体数据特征, 针对原始的Prophet模型和ARIMA模型进行了优化。
2.1 预测算法调参方法优化
由于资源限制, 基于贝叶斯的自动调参迭代次数不能设定过大, 因此仍然可能会遗漏某些重要的参数取值。为了解决该问题, 本文提供了一种综合调参策略, 将基于贝叶斯的自动调参Hyper模式与人工自定义调参Auto模式进行融合。
Hyper模式表示基于贝叶斯的自动调参模式, 可事先设定AutoPA4DB中的预处理参数以及预测模型的参数, 以及每个参数的调参范围。Auto模式是对Hyper模式的重要补充, 可手动事先设定Hyper模式可能无法覆盖, 但根据经验得出的重要参数组合, 批量执行调参。AutoPA4DB将综合Hyper模式与Auto模式的调优结果, 依据目标函数选出最终的最优参数。
2.2 预测相关参数优化
在Prophet预测模型中, 当趋势增长函数使用逻辑回归模型时, cap参数可设定预测值的上限。本文针对不同影响因素的敏感性分析结果表明, cap值对预测准确性影响较大, 且与原始数据取值范围密切相关。为了使得该参数取值更加有效, 在AutoPA4DB中, 每个数据库性能指标从其对应原始数据中自动获取cap范围。Hyper模式中, cap值的有效调参区间将设置为[0.8*max, 1.2*max], 其中max表示原始数据中最大值。在Auto模式中, 由于cap值只能设定为一个确定值, 将设置cap=1.2*max。
此外, 在数据预处理和数据预测中, 由于数据库监控指标的真实值一定是大于0的正数。当数据处理得到负数时, 将强制设为0.01。
3 实验设计
本文期望根据历史监控数据预测云数据库性能指标在未来短时间内(如1个月内)的变化趋势, 以指导运维人员动态调整资源。
3.1 实验数据集
实验中使用了某企业2019/01/25-2019/06/25的6个云数据库实例的性能指标监控数据和运维竞赛的6个数据库实例性能监控数据作为实验对象, 如表 1所示。
KPI数据集描述
DS1是企业真实数据集, 包含10种指标, 分别是磁盘使用量(GB), CPU利用率(%), 内存使用率(%), 网络输入吞吐量(byte/s), 网络输出吞吐量(byte/s), 数据库总连接数(个数), 当前活跃连接数(个数), IOPS(次数/秒), QPS(次数/秒), TPS(次数/秒), 每种指标6个实例。由于性能指标数据采集间隔设置为分钟级时对云数据库厂商的存储造成巨大压力, 因此通常设定为按照小时粒度采集数据。
为了同时验证AutoPA4DB方法在分钟级别采集的性能数据预测上的有效性, 本文还使用一个运维竞赛提供的真实数据集DS2中的内存已用容量(GB)进行了实验验证。
图 5和图 6展示了DS1中部分性能指标数据分布图, 图 7展示了DS2中指标数据的分布图, 由图可知每个KPI数据分布情况差异较大。根据原始数据分布规律, 将指标分为2大类:有显著单调变化趋势, 如磁盘使用量(GB); 无显著单调变化趋势, 有震荡变化, 如内存使用率(%)等。
 |
图5 DS1内存使用率(%)原始数据分布图 |
 |
图6 DS2内存已用容量(GB)原始数据分布图 |
 |
图7 DS1磁盘使用量(GB)原始数据分布图 |
3.2 自动调优参数及调参取值范围
本小节描述实验中自动调优的主要参数及其调参范围。表 2列出了数据预处理的主要调优参数。此外, 由于Prophet模型的默认参数通常不能获得最优预测, 表 3列出了Prophet模型的调优参数。
预处理调优参数
Prophet模型调优参数
3.3 时序交叉验证
本实验中采用Prophet算法中的时序交叉验证方法。DS1根据需求设定每折测试集包含30天数据, 训练集是测试集起始日期之前的所有数据。每折中的测试集向前回退7天, 训练集随之改变, 直到训练集仅包含整个数据集最初的30天数据为止。最终, 经计算共进行13折交叉验证, 即最终采用了13次的平均值作为该模型的预测准确性。DS2设定方法同DS1, 表 4是DS1和DS2交叉验证数据集设定。
DS1和DS2交叉验证数据设定
4 实验结果
由于篇幅限制, 本文主要以DS1中磁盘使用量和内存使用率以及DS2的内存已用容量为代表进行实验结果的展示。
4.1 预测模型优化效果
图 8以DS1中磁盘使用量为例, 展示了Prophet模型在应用了2.1和2.2小节优化策略前后的效果对比。其中横轴表示6个不同的数据库实例, 纵轴表示在预测时长为30天的情况下, 磁盘使用量变化趋势预测的准确性WMC。由图 8可知, 本文提出的优化策略使得在Prophet算法中, 磁盘使用量的预测准确率平均提升了9%左右。其中数据预处理部分的优化提升了2%左右, 预测模型优化提升了7%左右。图 9以DS2中内存已用容量为例, 展示了优化前后效果对比。纵轴表示在预测时长为1小时的情况下, 内存已用容量的预测准确性WMC。由图 9可知, 优化策略使得内存已用容量预测准确率平均提升了8%左右, 其中预处理部分的优化提升了2%左右, 预测模型优化提升了6%左右。
 |
图8 DS1中模型优化前后磁盘使用量预测准确性对比图 |
 |
图9 DS2中模型优化前后内存已用容量预测准确性对比图 |
4.2 不同预测模型对比
图 10展示了DS1的6个数据库实例中磁盘使用量的预测结果, 注意图 10的prophet和auto_arima是经过AutoPA4DB优化后的模型。同时参考论文[6, 10]本文对比了3种常用的时序预测算法:基于指数平滑模型自动预测的ets算法, 基于随机游走模型的snaive算法和基于TBATS模型的tbats算法。实验结果表明优化后的Prophet模型预测准确度最高, 其中MAPE低于5%, 覆盖率在95%左右。
 |
图10 DS1中磁盘使用量预测准确性对比图 |
对于内存使用率, CPU使用率等震荡数据模式, AutoPA4DB预测效果不稳定。在部分性能指标中表现较好, 如内存使用率, 部分指标中表现较差, 如数据库连接数。图 11展示了不同预测算法的内存使用率预测准确性。由该图可知, 即使是预测效果较好的内存使用率, 也是在部分实例中表现较好, 部分实例中表现一般。
 |
图11 DS1中内存使用率预测准确性对比图 |
对于内存已用容量, 如表 5所示, 在其趋势预测结果中, AutoPA4DB优化后的prophet模型的预测准确度WMC平均为0.000 58, 远低于其他预测算法, 预测效果最好。
DS2内存已用容量不同预测模型的加权准确度WMC
4.3 不同预测周期的对比
实验中建立预测模型后, 用每个模型分别预测了7天, 14天, 21天和30天的数据库性能数据, 图 12以DS1中磁盘使用量为例, 展示了不同预测周期下的模型预测准确性。该图显示预测周期越短时, 趋势预测准确性越高。该结果也符合人们的认知常识。因此在实践中, 云数据库厂商可以仅提供较短周期内的预测结果给客户或供内部决策使用。
 |
图12 不同预测周期下DS1磁盘使用量预测准确性对比图 |
4.4 异常点和突变点分析
异常点是指原始数据中的明显离群点, 常会影响数据变化的整体规律, 通常在预处理阶段去除。变化点(changepoint)是指变化率有明显变化的突变点(Prophet模型在默认设置下会自动检测25个变化点)。为了防止异常点去除对突变点检测产生影响, 本小节用实验进行了验证。图 13以DS1中实例1的CPU利用率展示了本算法中检测到的异常点和突变点。由图可知, 本算法的异常点检测基本准确, 且去除异常点对数据中的正常变化点检测没有影响。
 |
图13 DS1中CPU利用率实例1的异常点与变化点分布图 |
4.5 算法消耗时间分析
本小节分析了AutoPA4DB算法耗时数据。表 4以DS1中实例1的CPU使用率(包含3 595条数据, 13次交叉验证)预测为例, 记录了每步处理的时间。实验计算机环境:处理器Inter(R) Core(TM) i7-9700K八核3.6CHz, 内存16G。
从表 6中数据可知, Prophet模型的预测所需时间多于ARIMA模型, 但在2分钟之内可以完成, 属于可接受范围。整体AutoPA4DB的一次预测调优在3分钟之内完成。
AutoPA4DB算法消耗时间
5 结论
本文针对云数据库运维监控获得的性能指标时序数据, 基于Prophet和ARIMA算法设计了一种综合趋势预测方法AutoPA4DB。用实际企业数据DS1和运维竞赛数据DS2对数据库性能指标进行了趋势预测, 并与snaive, tbats, ets算法进行了对比, 主要结论如下:
1) AutoPA4DB针对数据库性能数据进行了预测优化, 比原始Prophet模型预测准确度提高了约9%, 其中预处理部分准确度提高了2%, 预测模型优化准确度提高了7%, 表明该模型优化效果明显。
2) AutoPA4DB方法在单调变化模式的时序数据中预测准确度高, 以磁盘使用量(GB)为例, MAPE误差在2%左右, 覆盖率在95%以上, 且优于其他对比模型。但在震荡模式的数据中预测效果不稳定, 部分指标预测较好, 部分指标预测极差。
本研究中还存在一些不足之处:如异常检测方法应针对数据库性能时序数据有针对性的改进。另外, 实验数据虽然满足预测方法需求, 但是为了提高结果的可扩展性, 还应在数据量更大的数据集上测试。最后, 震荡模式数据中预测效果不稳定的问题将是我们后续研究的重点。
References
- Dang Y, Lin Q, Huang P. AIOps: Real-World Challenges and Research Innovations[C]//Proceedings of the 41st International Conference on Software Engineering: Companion Proceedings, 2019 [Google Scholar]
- Pei Dan, Zhang Shenglin, Pei Changhua, et al. Intelligent Operation and Maintenance Based on Machine Learning[J]. Communications of the CCF, 2017, 13 (12): 68– 72 [Article] (in Chinese) [Google Scholar]
- Lin Ziyu, Lai Yongxuan, Lin Chen, et al. Research on Cloud Databases[J]. Journal of Software, 2012, 23 (5): 1148– 1166 [Article] (in Chinese) [CrossRef] [Google Scholar]
- Yuan Jidong, Wang Zhihai. Review of Time Series Representation and Classification Techniques[J]. Computer Science, 2015, 42 (3): 1– 7 [Article] (in Chinese) [Google Scholar]
- Jan G., De Gooijer, Hyndman ROB J.. 25 Years of Time Series Forecasting[J]. International Journal of Forecasting, 2006, 22 (3): 443– 473 [Article] [CrossRef] [Google Scholar]
- Yang Haimin, Pan Zhisong, Bai Wei. Review of Time Series Prediction Methods[J]. Computer Science, 2019, 46 (1): 21– 28 [Article] (in Chinese) [Google Scholar]
- Taylor S J, Letham B. Forecasting at Scale[J]. The American Statistician, 2018, 72 (1): 37– 45 [Article] [CrossRef] [Google Scholar]
- Han Dongming, Guo Fangzhou, Pan Jiacheng, et al. Visual Analysis for Anomaly Detection in Time-Series:a Survey[J]. Computer Research and Development, 2018, 55 (9): 1843– 1852 [Article] (in Chinese) [Google Scholar]
- Cui Jiaxu, Yang Bo. Survey on Bayesian Aptimization Methodology and Applications[J]. Journal of Software, 2018, 29 (10): 3068– 3090 [Article] (in Chinese) [Google Scholar]
- Rob J H, Anne B K, Ralph D S, et al. A State Space Framework for Automatic Forecasting Using Exponential Smoothing Methods[J]. International Journal of Forecasting, 2002, 18 (3): 439– 454 [Article] [CrossRef] [Google Scholar]
All Tables
All Figures
|
图1 AutoPA4DB框架图(粗体字部分为本文优化内容) |
| In the text | |
|
图2 磁盘使用量/GB趋势预测图 |
| In the text | |
|
图3 内存使用率/%趋势预测图 |
| In the text | |
|
图4 DS1中CPU利用率异常点分布 |
| In the text | |
|
图5 DS1内存使用率(%)原始数据分布图 |
| In the text | |
|
图6 DS2内存已用容量(GB)原始数据分布图 |
| In the text | |
|
图7 DS1磁盘使用量(GB)原始数据分布图 |
| In the text | |
|
图8 DS1中模型优化前后磁盘使用量预测准确性对比图 |
| In the text | |
|
图9 DS2中模型优化前后内存已用容量预测准确性对比图 |
| In the text | |
|
图10 DS1中磁盘使用量预测准确性对比图 |
| In the text | |
|
图11 DS1中内存使用率预测准确性对比图 |
| In the text | |
|
图12 不同预测周期下DS1磁盘使用量预测准确性对比图 |
| In the text | |
|
图13 DS1中CPU利用率实例1的异常点与变化点分布图 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.