| Issue |
JNWPU
Volume 39, Number 3, June 2021
|
|
|---|---|---|
| Page(s) | 641 - 649 | |
| DOI | https://doi.org/10.1051/jnwpu/20213930641 | |
| Published online | 09 August 2021 | |
An intelligent decision-making method for anti-jamming communication based on deep reinforcement learning
一种基于深度强化学习的通信抗干扰智能决策方法
Received:
27
August
2020
Abstract
In order to solve the problem of intelligent anti-jamming decision-making in battlefield communication, this paper designs an intelligent decision-making method for communication anti-jamming based on deep reinforcement learning. Introducing experience replay and dynamic epsilon mechanism based on PHC under the framework of DQN algorithm, a dynamic epsilon-DQN intelligent decision-making method is proposed. The algorithm can better select the value of epsilon according to the state of the decision network and improve the convergence speed and decision success rate. During the decision-making process, the jamming signals of all communication frequencies are detected, and the results are input into the decision-making algorithm as jamming discriminant information, so that we can effectively avoid being jammed under the condition of no prior jamming information. The experimental results show that the proposed method adapts to various communication models, has a fast decision-making speed, and the average success rate of the convergent algorithm can reach more than 95%, which has a great advantage over the existing decision-making methods.
摘要
为解决战场通信智能抗干扰决策问题,设计了一种基于深度强化学习的通信抗干扰决策方法。该方法在DQN算法架构下引入经验回放和基于爬山策略(PHC)的动态ε机制,提出动态ε-DQN智能决策算法,该算法能够根据决策网络状态更优地选择ε值,提高收敛速度和决策成功率。在决策过程中,对所有通信频率是否存在干扰信号进行检测,将结果作为干扰判别信息输入决策算法,使算法可在无先验干扰信息条件下智能决策通信频率,在尽量保证通信不中断的前提下,有效躲避干扰。实验结果表明,所提方法适应多种通信模型,决策速度较快,算法收敛后的平均成功率可达95%以上,较已有方法具有较大优势。
Key words: anti-jamming communication / intelligent decision-making / deep reinforcement learning
关键字 : 通信抗干扰 / 智能决策 / 深度强化学习
© 2021 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
随着战场电磁环境日趋复杂以及电子战技术的快速发展[1],军用无线通信受到的威胁越来越大,提高通信抗干扰能力迫在眉睫,要想尽可能保证通信不受干扰,决策环节至关重要。
通信抗干扰过程是通信系统与干扰系统博弈的过程,由于博弈论解决决策问题具有优势[2],基于博弈论的通信抗干扰决策和认知无线电研究取得一定成果。这些研究主要基于前景理论[3]、Stackelberg博弈[4]和随机学习理论等[5]方法,从频率、功率等[6-7]角度入手,通过构建通信与干扰间的博弈模型,计算出最优通信抗干扰策略。此类方法的特点在于通信方需要获取干扰先验信息,通过数学推导得出结果。当干扰先验信息未知时,此类方法实现较为困难,不足以应对干扰样式不断变化的情况。
近年来,随着对人工智能研究不断深入,一些基于强化学习的通信抗干扰决策方法研究取得成果。这些研究从功率分配[8]、频率选择等[9-10]角度入手,综合运用模式识别[10]、多智能体决策等[11]领域知识,设计基于强化学习的方法进行决策。其中,文献[10]通过信号时频图识别干扰样式,将频谱信息转换为干扰样式信息,根据不同干扰样式分别决策通信频率;文献[11]提出一种基于Q-Learning算法的多智能体协同抗干扰算法,在扫频干扰的情况下抵抗信道中的恶意干扰。此类决策方法最大优势在于能够自动学习干扰信号的规律和特点,自主决策出当前状态下最优的抗干扰策略,大幅度降低决策时间,提高决策准确率。
在抗干扰决策过程中,改变通信频率是经常使用的一种有效手段,本文从通信频率选择角度入手,将通信抗干扰决策与深度强化学习方法相结合,提出动态ε-DQN智能决策算法。利用能量检测法[14]对各通信频率是否存在干扰信号进行检测,得到当前回合的干扰判别信息,输入决策算法,决策下一回合的通信频率,并在干扰信号对准的同时改变通信频率,有效躲避干扰。在不同通信场景下进行仿真实验,并与已有方法的决策效果进行对比,验证本文所提方法的有效性和适用性。
1 系统模型
在通信场景中设置1个通信系统和1台干扰机,如图 1所示,通信系统由信号发射机、接收机,干扰检测模型和智能决策模型组成。
 |
图1 通信抗干扰智能决策方法的体系结构 |
1.1 信道传输模型
在信号传输过程中,用接收机的输入信干比(RSIN)判定本次通信的被干扰程度,评估通信效果,RSIN可用(1)式表示。
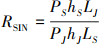 1
1
式中:PS为信号发射机的发射功率;PJ为干扰机的发射功率; hS为信号发射天线增益与接收天线增益之积; hJ为干扰机发射天线与信号接收天线增益之积; LS和LJ分别为信号发射机和干扰机信号传输的空间损耗, 用(2)式表示, r为信号传播距离。
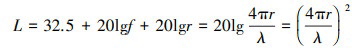 2
2
为适应本文研究的问题模型, 所计算的RSIN用(3)式表示[15], 将(2)式带入可得(4)式。
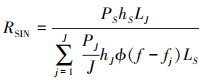 3
3
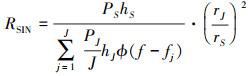 4
4
式中:J为干扰频率个数; ϕ(x)为代表某频率是否被干扰的指示值, 可用(5)式表示; 表示干扰信号在各个频率上的功率之和。
表示干扰信号在各个频率上的功率之和。
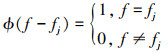 5
5
1.2 通信模型
为多角度验证本文所提出决策算法的有效性和适应性, 设置2个通信场景。通信时间以回合为基准, 每个回合进行1次通信。
·场景1:每个回合仅选择1个频率进行通信, 共有NS个频率可供选择, 该频率上的信号功率为PS[11]。若信干比超过阈值qd, 认为当前回合正常通信。
·场景2:基于跳频通信体制, 每个回合在一个频率集上进行通信, 每个频率集共有h个频率, 共有Nh个频率集可供选择, 每个频率上分配的信号功率为PS/h。若总信干比大于阈值qh, 认为当前回合正常通信。
1.3 干扰模型
根据上述2种不同通信场景, 设置2种有针对性的干扰模型。
在对场景1的干扰模型中, 设置扫频干扰、梳状谱干扰和双频带扫频干扰[11]3种干扰样式, 每20个回合随机切换1次。
·扫频干扰: 干扰机按照频率大小顺序顺次干扰, 每回合干扰固定带宽Bk, 带宽内分配的干扰功率为Pj。
·梳状谱干扰: 干扰机每回合选择mj个干扰谱组成梳状谱干扰, 每个干扰谱带宽为1 MHz, 带宽内分配的干扰功率为Pj/mj。
·双频带扫频干扰: 与扫频干扰类似, 干扰机在2个频带上作相反顺序的扫频干扰, 每个干扰带宽内分配的干扰功率为Pj/2。
对场景2的干扰模型设置2种干扰模式, “侦察-干扰”模式和基于经验的干扰模式, 2种干扰样式每100个回合随机改变1次。
在“侦察-干扰”模式下, 假设干扰机正在干扰频率f0。从某时刻开始, 干扰机对当前通信频率f1进行侦察, 侦察时的干扰频率不变, 仍为f0。经过侦察时间T回合后, 对侦察的频率f1实施干扰。初始侦察时间为Tj回合, 随着对抗回合数增加, 干扰机逐渐熟悉当前通信体制, 侦察时间逐渐减小, 每增加100个回合, 侦察时间减少1个回合, 最短为Tjmin回合。考虑到侦察存在误差的可能性, 设置一个可信概率ph, 有ph的可能干扰频率与通信频率完全相符; 而有(1-ph)的可能存在部分频率侦察错误, 与通信频率不符。
在基于经验的干扰模式下, 干扰机选择最近100个回合里出现次数最多的通信频率进行干扰。
图 2展示了这种模型下的通信和干扰状态, 横轴为频率点数, 纵轴为时间回合数。绿色表示正常通信的频率, 蓝色表示干扰成功的频率, 红色表示干扰失败的频率。
 |
图2 通信场景2的信道状态 |
1.4 干扰检测模型
根据信道内频率个数设置带通滤波器, 分别对不同频率的信号进行滤波, 得到各个频率上的信号功率Pn, 设定一个检测模型[14]
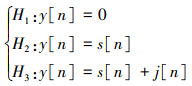 6
6
式中:y[n]表示某频率上的信号, 在不考虑外界环境噪声的情况下, 它有3种可能的组成方式: 无信号, 即y[n]=0;只有通信信号s[n]; 通信信号s[n]和干扰信号j[n]共同组成。
计算每个频率的信号能量D(y), 用(7)式表示[14]。设置门限值λ, 对能量进行判别, 若高于λ, 则认为该频率属于检测模型中的H3, 即存在干扰信号; 否则属于检测模型中的H1或H2, 即不存在干扰信号。将每个频率是否存在干扰信号的判别信息作为信道状态, 输入智能决策模型。
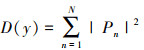 7
7
1.5 智能决策模型
智能决策模型将接收到的信道状态输入动态ε-DQN智能决策算法, 根据当前回合的干扰频率, 给出下一回合通信频率, 输出决策模型。效能评估模块根据信道状态和决策结果, 给出决策奖励值, 传回算法, 引导算法训练更新。
2 动态ε-DQN智能决策算法
2.1 强化学习框架
强化学习离不开智能体和环境2个基本条件, 智能体作为动作执行者, 与环境交互, 获取所需信息, 推动算法的训练更新。解决强化学习问题一般有5个关键要素: 动作空间A, 状态空间S, 即时奖励r(s, a), 转移概率空间P和策略π。
当转移概率空间P未知时, 无法预测智能体与环境的交互情况, 这种强化学习被称为无模型的强化学习, 解决此类问题的传统算法是Q-Learning算法。该算法建立一个Q表, 用表格的形式来存储每个状态-动作价值Q(s, a), Q(s, a)的计算过程可用(8)式表示。
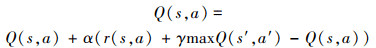 8
8
在算法训练阶段, 通常将ε-greedy策略作为策略π进行训练更新。在该策略下, 有1-ε的概率个体选择Q值最大的动作, 有ε的概率随机选择动作。
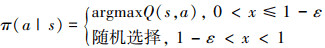 9
9
当处理状态、动作空间较小的问题时, Q-Learning算法的效果较好, 但当处理状态、动作空间较大的问题时, 搜索Q(s, a)值会耗费大量时间, 导致收敛速度降低, 且算法很多时候不能探索到所有可能的动作, 收敛得到的策略π并非全局最优, 此时该算法便不再合适。
2013年提出的DQN算法将图像或大数据集等信息作为状态s输入神经网络, 再输出动作空间A中各个动作对应的Q(s, a)值, 代替了Q表的运行机制, 巧妙解决了上述问题。
2.2 动态ε-DQN智能决策算法
本文提出动态ε-DQN智能决策算法, 运算流程如图 3所示。在强化学习框架下, 将算法所需基本元素定义如下:
 |
图3 智能决策算法运算流程 |
1) 状态空间: 分别将每个频率上的干扰判别信息用Sn表示, 若无干扰信号, Sn=1;若有干扰信号, Sn=-1。将集合S=[S1, S2, …, Sn]作为状态空间输入算法。
2) 动作空间: 每个可选频率An组成的集合A作为动作空间。
3) 即时奖励: 以当前回合信干比RSIN为基础, 根据不同通信模型下的阈值q设置奖励函数。当RSIN < q时通信被成功干扰, RSIN=0;当RSIN≥q时通信正常, RSIN=1。为尽可能保证在同一频率上稳定连续通信, 引入频率转换因子Ctr[15], 若与上一回合相比, 通信频率改变, 则Ctr=0.6, 否则Ctr=0, 即时奖励r可用(10)式表示。
 10
10
传统的ε-greedy策略有固定的ε概率随机选择动作, 使算法在任何回合的随机性相同。然而算法在起始阶段和收敛阶段需要的随机性不同, 固定的ε值会导致算法向局部最优收敛且难以保持稳定的收敛状态。本文基于PHC算法[17], 提出动态ε策略, 根据奖励值与回合数动态调整ε值, 使算法收敛到稳定的全局最优状态。PHC算法在已知动作概率π(s, a)的条件下, 根据价值Q动态调整概率, 尽可能提高最大Q值所对应动作的概率。
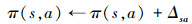 11
11
式中
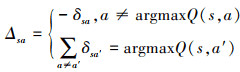 12
12
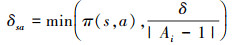 13
13
当选择Q值最大的动作时, 也相应增大该动作的概率值; 当选择其他动作时, 则相应减小该动作的概率值。本文结合PHC算法的动态调整方式, 将ε初始值设置为1, 算法每迭代一个回合, ε值动态调整1次, 直至ε值为0。若r≤0, 说明上一回合决策失败, 则将ε值减小, 增加其选择最优动作的概率, 减小策略的随机性, 加速算法收敛; 若r>0, 说明上一回合决策成功, 则不改变ε值, 使策略继续保持原有随机性。动态ε策略可用(15)式表示, 在0~1内随机生成数x, 若x≤1-ε, 则选择Q值最大的动作; 若x>1-ε, 则随机选择动作。
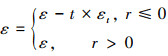 14
14
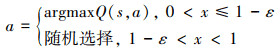 15
15
这里引入一种经验回放机制[18], 把最近回合的经验e= < s, a, r, s′>存入经验池E中, 在更新权重值θ时, 随机抽取部分经验样本进行更新, 以最大程度破除相邻数据间的相关性并提高样本利用率。
算法中包含2个神经网络, 分别作为估值神经网络和目标神经网络。估值神经网络负责给出当前状态s的估计价值Q(s, a; θn), 引导动作a的选择。目标神经网络负责给出目标价值Q(s′, a′; θn-)。其中, θn为在n回合估值神经网络的权值参数, θn-为在n回合目标神经网络的权值参数。
定义误差函数L(θ), 由(16)式表示。对参数θn作梯度下降计算, 以更新估值神经网络。每经过L个回合, 将估值神经网络的权值参数赋给目标神经网络, 使2个网络参数相同, 这样就不必实时更新目标价值, 减小了对目标价值选取的相关性。
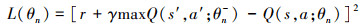 16
16
本文基于动态ε-DQN提出的智能决策算法, 设置初始通信频率为A0, 算法根据当前回合的状态St, 决策下一回合的通信频率At+1。设置经验池大小为NE, 选取的经验样本大小为NB。此时, 估计价值和目标价值分别为Q(St, At+1; θ)和Q(St, At+1; θ-), (16)式可写为
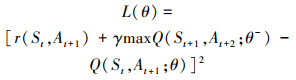 17
17
神经网络参数更新的过程可分别用(18)、(19)式表示。
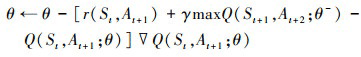 18
18
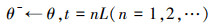 19
19
算法 动态ε-DQN智能决策算法
1) 分别建立2个神经网络: 权值参数为θ的估值神经网络和权值参数为θ-的目标神经网络
2) 随机初始化权值参数θ, 令θ-=θ
3) 初始化选择通信频率作为初始动作A0, 设置总回合数Z
4) t≤Z时, 重复执行步骤5)~13);
5) 获得信道状态集合St
6) 按照(14)式计算ε
7) 根据动态ε策略选择下一回合通信频率At+1
8) 按照通信频率At+1进行信号传输
9) 获得即时奖励r(St, At+1)
10) 获得下一回合的信道状态集合St+1
11) 将经验样本et= < St, At+1, r(St, At+1), St+1>存入经验池E中
12) 从经验池中随机选取经验样本NB个, 代入到(15)
式中更新估值神经网络的参数θ
13) 每L个回合, 令θ-=θ, 使目标神经网络与估值神经网络参数相同
14) t>Z时, 执行完毕
算法中神经网络使用全连接网络, 激活函数设置为ReLU。将状态集合中的各个元素作为输入层的各个元素, 其神经元个数为状态集合St中的元素个数NS; 神经元个数为动作集合At+1中的元素个数NA; n个全连接层神经元个数均为NF, 总的神经元个数为(NS+NA+nNF)。
该算法计算复杂度与神经网络有关, 输入层有NS个神经元, 那么第1个隐藏层有NSNF个权重, 第n-1个隐藏层有NF2个隐藏层, 输出层共有NANF个权重, 则整个神经网络共有NF(NS+(n-1)NF+NA)个权重。那么算法每一次迭代的复杂度可用(20)式表示。
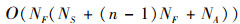 20
20
3 实验与仿真分析
本小节将干扰判别信息和干扰样式信息分别作为算法输入, 对比动态ε-DQN算法、文献[10]中的M-RL决策算法和随机决策算法的决策效果, 表 1为设定的模型参数。
模型参数设置
3.1 通信场景1
根据文献[10], 共有5个通信频率可供选择, 每个带宽为1 MHz。扫频干扰每个回合扫频带宽为200 kHz; 梳状谱干扰每个回合在第1、第3和第5个频率设置共有3个干扰谱的干扰, 即mj=3, 信干比的阈值qd=0.9。
设置估值神经网络和目标神经网络均包括输入层、1个隐藏层和输出层。若干扰模型采用扫频干扰, 其扫频带宽小于通信信号带宽, 为体现干扰状态, 以扫频干扰带宽为准设置输入层神经元数量, 为5×(1 MHz/200 kHz)=20个, 其余2层神经元个数分别为16和5。
图 4所示为输入干扰判别信息时, 3种决策算法10 000个回合下每百回合平均决策成功率对比。动态ε-DQN算法在前2 000个回合的决策成功率略低于M-RL算法, 这是由于算法采用动态ε策略, 收敛前的随机性较强, 导致成功率相对较低。随着随机性减弱, 在2 500个回合后, 动态ε-DQN算法的决策成功率逐渐收敛到100%, 表现出优于其他2种算法的决策效果。
 |
图4 输入干扰判别信息的算 |
图 5所示为输入干扰样式信息时, 3种算法的平均决策成功率对比。与图 4类似, 动态ε-DQN算法在5 000回合左右达到收敛, 成功率稳定在98%以上, 但由于算法的随机性, 在收敛前其决策成功率低于M-RL算法。综合图 6与图 7可以看出, 动态ε-DQN算法在收敛后的决策成功率高于M-RL算法, 其决策效果更好。
 |
图5 输入干扰样式信息的算 |
 |
图6 不同输入信息的算法法平均决策成功率对比法平均决策成功率对比平均决策成功率对比 |
 |
图7 不同ε值的算法决策成功率对比 |
图 6所示为算法分别输入干扰判别信息和干扰样式信息的平均决策成功率对比。从图中可以看出, 由于输入干扰样式信息时, 需要对不同干扰样式所对应的决策网络进行训练, 导致其收敛速度变慢; 相比于输入干扰样式信息, 输入干扰判别信息的算法收敛后决策成功率更高, 稳定在100%。如果是一种未知的干扰信号, 将无法识别其干扰样式, 而干扰判别信息从能量角度入手检测, 不存在上述问题, 所以结合图 6, 输入干扰判别信息的方法适应性更强, 决策效果更优。
表 2给出了输入不同信息时, 2种智能决策算法10 000回合内的决策时间对比。无论输入何种信息, 动态ε-DQN算法决策速度均更快, 且输入干扰判别信息的算法决策速度最快, 仅需15.48 s。
10 000回合决策时间对比 s
图 7展示了分别采用动态ε策略和不同ε值的ε-greedy策略时, 算法的决策成功率对比。可以看出随着ε值不断增大, 算法采用ε-greedy策略收敛后的平均成功率不断减小, 而采用动态ε策略的算法平均成功率稳定在100%, 这说明相比于采用ε-greedy策略, 动态ε策略既提高了算法的收敛能力, 又提高了算法的决策成功率。
由于动态ε-DQN算法采用了动态ε策略, 其随机性随着迭代次数增加不断降低, 算法收敛后的决策成功率稳定在最优值上; 而M-RL算法由于一直存在随机性, 其决策成功率在最优值下方不断波动, 这使得动态ε-DQN算法的决策成功率高于M-RL算法。
以输入干扰判别信息为例, 对2种智能决策算法的计算复杂度进行比较。由(20)式可计算出当前场景下动态ε-DQN算法1次迭代的计算复杂度为O(400)。由于M-RL算法是基于Q-Learning的决策算法, 所以M-RL算法是遍历求解的, 可用O(SA)表示其计算复杂度[19]。其中S为输入算法的状态总数, A为可供算法选择的动作总数, 可计算得到当前场景下算法的计算复杂度为O(205)。
虽然动态ε-DQN算法的计算复杂度略高于M-RL算法, 但由于神经网络各层之间通过矩阵计算能够降低算法的时间复杂度, 所以动态ε-DQN算法的决策速度依然较快。
3.2 通信场景2
这一部分评估了动态ε-DQN算法在更复杂的通信场景2下的性能。设置信道带宽为60 MHz, 共有60个频率。有5个跳频频率集可供通信方选择, 每个频率集共32个频率, 每个回合干扰机可干扰12个频率。一般情况下, 若频率集中有30%的频率被干扰, 则认为无法正常通信, 基于此设置阈值qh=0.33;可信概率ph=0.8, 最初的侦察时间Tj=20, 最小侦察时间Tjmin=5。
设置估值神经网络和目标神经网络均包括输入层、2个隐藏层和输出层, 各层神经元数量分别为60,42,42和5。
与通信场景1一样, 图 8展示了输入干扰判别信息时, 3种算法的每百回合平均决策成功率。可以看出, 虽然M-RL算法收敛较快, 平均成功率在85%上下波动, 但动态ε-DQN算法的平均决策成功率更高, 在3 000回合后平均成功率可达98%以上。
 |
图8 输入干扰判别信息的算 |
图 9所示为输入干扰样式信息时, 3种算法的平均决策成功率对比。动态ε-DQN算法在4 000回合左右达到收敛, 成功率稳定在95%以上, 综合图 8与图 9可以看出, 动态ε-DQN算法在收敛后的成功率要高于M-RL算法, 其决策效果更好。
 |
图9 输入干扰样式信息的算 |
图 10所示为算法分别输入干扰判别信息和干扰样式信息时, 平均决策成功率对比。输入干扰样式信息的算法收敛后的决策成功率在90%~100%间波动, 而输入干扰判别信息的算法收敛速度更快且成功率稳定在95%以上, 决策效果更好。
 |
图10 不同输入信息的算法法平均决策成功率对比法平均决策成功率对比平均决策成功率对比 |
表 3显示了动态ε-DQN算法和M-RL算法在通信场景2下、输入不同信息时, 10 000回合的决策时间, 与通信场景1相比, 2种算法的决策速度均有所减慢。但相比于M-RL算法, 动态ε-DQN算法的决策速度快70%以上, 且输入干扰判别信息时决策速度最快, 仅需28.28 s。
10 000回合决策时间对比 s
图 11展示了采用动态ε策略和不同ε值的ε-greedy策略时, 算法决策成功率对比。与通信场景1类似, 可以看出随着ε值不断增大, 收敛后的平均成功率不断减小, 而采用动态ε策略的算法平均成功率在3 000回合后, 可达95%以上, 再次证明了动态ε策略较好的决策效果。
 |
图11 不同ε值的算法决策成功率对比 |
由于在该场景下干扰频率不是固定的, 会产生大量不同的状态, 使得M-RL算法的训练不够充分, 在一些状态下决策出的通信频率不是最优的; 而动态ε-DQN算法通过神经网络的拟合可以在任意干扰状态下决策通信频率, 且保证准确率较高。同时, 采用了动态ε策略的动态ε-DQN算法随着迭代进行, 决策成功率将逐渐稳定在最优值上。
与场景1一样, 以输入干扰判别信息为例, 对2种智能决策算法的计算复杂度进行比较。由(20)式可计算出当前场景下动态ε-DQN算法的计算复杂度为O(4 494);而干扰模型从32个频率中选择12个频率进行干扰, 可能产生的干扰状态最多有C3216个, M-RL算法的计算复杂度为O(5C3216), 远超过动态ε-DQN算法, 所以动态ε-DQN算法在决策速度上的优势更为明显。
综合2个通信场景的算法结构和计算复杂度来看, 模型越复杂, M-RL算法的决策效果越低于动态ε-DQN算法。在复杂模型下, 只要将动态ε-DQN算法中的各类参数进行优化调整, 就能够解决当前的决策问题, 虽然计算复杂度成倍增加, 但算法仍然能够较为快速、准确地收敛到最优状态。
4 结论
本文设计一种通信抗干扰智能决策方法, 该方法基于DQN算法架构, 提出动态ε-DQN算法, 将当前回合的干扰判别信息作为输入, 决策下一回合的通信频率以躲避干扰。
综合2个典型通信场景下的仿真实验结果可分析得出, 无论输入何种干扰信息, 动态ε-DQN算法在收敛后的决策成功率均可达95%以上, 当输入干扰判别信息时, 决策成功率能够趋近100%;同时通过对比10 000回合的决策时间, 可以发现动态ε-DQN算法的决策速度远高于M-RL算法, 当模型越复杂时, 这种优势越显著, 综合来看动态ε-DQN算法的性能优于M-RL算法。对比输入不同干扰信息的算法可以得出, 输入干扰判别信息的算法无论决策成功率还是决策速度均优于输入干扰样式信息的算法; 由于干扰判别信息可直接通过干扰检测法获得, 无需进行模式识别等复杂的处理步骤, 该种信息的获取更容易且适应性更强, 所以将干扰判别信息输入决策算法可获得事半功倍的效果。
综合决策性能指标来看, 本文所提出的将干扰判别信息输入动态ε-DQN算法的决策方法决策成功率较高、速度较快, 决策效果较其他方法有较大提升。
References
- Vardhan S. Information jamming in electronic warfare: operational requirements and techniques[C]//International Conference on Electronics, 2015: 49–54 [Google Scholar]
- Xiao L, Chen T, Liu J, et al. Anti-jamming transmission stackelberg game with observation errors[J]. IEEE Communications Letters, 2015, 19 (6): 949– 952 [Article] [Google Scholar]
- Xiao L, Liu J, Li Q, et al. User-centric view of jamming games in cognitive radio networks[J]. IEEE Trans on Information Forensics & Security, 2015, 10 (12): 2578– 2590 [Article] [CrossRef] [Google Scholar]
- Xia T, Piny R, Qingh D, et al. Securing wireless transmission against reactive jamming: a stackelberg game framework[C]//IEEE Global Communications Conference, 2016: 1–6 [Google Scholar]
- Jia L, Xu Y, S UN, et al. A game-theoretic learning approach for anti-jamming dynamic spectrum access in dense wireless networks[J]. IEEE Trans on Vehicular Technology, 2018, 68 (2): 1646– 1656 [Article] [CrossRef] [Google Scholar]
- Yang D, Xue G, Zhang J, et al. Coping with a smart jammer in wireless networks: a stackelberg game approach[J]. IEEE Trans on Wireless Communications, 2013, 12 (8): 4038– 4047 [Article] [CrossRef] [Google Scholar]
- Jia L, Yao F, S UN, et al. A hierarchical learning solution for anti-jamming stackelberg game with discrete power strategies[J]. IEEE Wireless Communications Letters, 2017, 6 (6): 818– 821 [Article] [CrossRef] [Google Scholar]
- Nasir Y S, Guo D. Multi-agent deep reinforcement learning for dynamic power allocation in wireless networks[J]. IEEE Journal on Selected Areas in Communications, 2019, 37 (10): 2239– 2250 [Article] [CrossRef] [Google Scholar]
- Liu X, Xu Y, Jia L, et al. Anti-jamming communications using spectrum waterfall: a deep reinforcement learning approach[J]. IEEE Communications Letters, 2017, 22 (5): 998– 1001 [Article] [CrossRef] [Google Scholar]
- Liu S, Xu Y, Chen X, et al. Pattern-aware intelligent anti-jamming communication: a sequential deep reinforcement learning approach[J]. IEEE Access, 2019, 7: 169204– 169216 [Article] [CrossRef] [Google Scholar]
- Yao F, Jia L. A collaborative multi-agent reinforcement learning anti-jamming algorithm in wireless networks[J]. IEEE Wireless Communication Letters, 2019, 8 (4): 1024– 1027 [Article] [CrossRef] [Google Scholar]
- Machuzak S, Jayaweera S K. Reinforcement learning based anti-jamming with wideband autonomous cognitive radios[C]//IEEE/CIC International Conference on Communications, 2016: 1–5 [Google Scholar]
- Aref M A, Jayaweera S K, Machuzak S. Multi-agent reinforcement learning based cognitive anti-jamming[C]//2017 IEEE Wireless Communications and Networking Conference(WCNC), 2017: 1–6 [Google Scholar]
- Lopez-Benitez M, Casadevall F. Improved energy detection spectrum sensing for cognitive radio[J]. IET Communications, 2012, 6 (8): 785– 796 [Article] [NASA ADS] [CrossRef] [Google Scholar]
- Zhang Lin, Tan Junjie, Liang Yingchang, et al. Deep reinforcement learning-based modulation and coding scheme selection in cognitive heterogeneous networks[J]. IEEE Trans on Wireless Communications, 2019, 18 (6): 3281– 3294 [Article] [CrossRef] [Google Scholar]
- He Ying, Zhang Zheng, Yu Richard, et al. Deep-reinforcement-learning-based optimization for cache-enabled opportunistic interference alignment wireless networks[J]. IEEE Trans on Vehicular Technology, 2017, 66 (11): 10433– 10445 [Article] [CrossRef] [Google Scholar]
- Yang Bo, L EI, et al. A novel multi-agent decentralized win or learn fast policy hill-climbing with eligibility trace algorithm for smart generation control of interconnected complex power grids[J]. Elsevier Energy Conversion & Management, 2015, 103: 82– 93 [Article] [CrossRef] [Google Scholar]
- Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518: 529– 533 [Article] [CrossRef] [PubMed] [Google Scholar]
- Chi Jin, Zeyuan Allenzhu, Sebastien Bubeck, et al. Is Q-learning Provably Efficient?[C]//32nd International Conference on Neural Information Processing Systems, 2018: 4868–4878 [Google Scholar]
All Tables
All Figures
|
图1 通信抗干扰智能决策方法的体系结构 |
| In the text | |
|
图2 通信场景2的信道状态 |
| In the text | |
|
图3 智能决策算法运算流程 |
| In the text | |
|
图4 输入干扰判别信息的算 |
| In the text | |
|
图5 输入干扰样式信息的算 |
| In the text | |
|
图6 不同输入信息的算法法平均决策成功率对比法平均决策成功率对比平均决策成功率对比 |
| In the text | |
|
图7 不同ε值的算法决策成功率对比 |
| In the text | |
|
图8 输入干扰判别信息的算 |
| In the text | |
|
图9 输入干扰样式信息的算 |
| In the text | |
|
图10 不同输入信息的算法法平均决策成功率对比法平均决策成功率对比平均决策成功率对比 |
| In the text | |
|
图11 不同ε值的算法决策成功率对比 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.