| Issue |
JNWPU
Volume 43, Number 1, February 2025
|
|
|---|---|---|
| Page(s) | 109 - 118 | |
| DOI | https://doi.org/10.1051/jnwpu/20254310109 | |
| Published online | 18 April 2025 | |
Image dehazing based on double branch convolution and detail enhancement
双分支卷积结合细节增强的图像去雾
School of Electronic and Information Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China
Received:
12
January
2024
Abstract
Because of detail loss, color distortion and contrast reduction in the image dehazing process in a haze condition, we proposed the image dehazing network based on double branch convolution and detail enhancement, which consists of image dehazing module and detail enhancement module. First, in the image dehazing module, we designed a double branch convolutional block based on depth-separable convolution and differential convolution and then combined it with the U-Net network, effectively reducing the detail loss in the image dehazing process. In the image dehazing model, we introduced the attention module composed of channel attention mechanism and pixel attention mechanism, which improves its feature extraction ability, suppresses the features that are not related to the current task and further reduces the color distortion and contrast in the image dehazing process. Then, we input the image dehazed with the image dehazing module into the detail enhancement module to further recover image details, so that the image is more similar to that in its real domain. The combination of the image dehazing module with the detail enhancement module improves the generalization ability of the image dehazing network and makes it more adaptable to the haze dataset. We carried out experiments with the public datasets ITS and Haze4K and the public real dataset IHAZE. The quantitative objective analysis and comparison show that the peak signal-to-noise ratio and the structural similarity index reach 39.69 dB and 0.994 respectively, indicating that there is a certain improvement compared with the optimal algorithm in the comparison network model. The subjective visual analysis shows that the image dehazed with the image dehazing network we proposed is more similar to the real no-haze image in terms of detail, color, contrast and so on.
摘要
针对雾天环境下图像去雾过程中出现的细节丢失、颜色失真、对比度下降的问题, 提出了一种双分支卷积结合细节增强的图像去雾网络DBDENet (double branch convolution combined with detail enhanced image de-fogging network), 此网络包含图像去雾模块和细节增强模块两部分。在图像去雾模块中, 设计了基于深度可分离卷积和差分卷积的双分支卷积块DBConv (double branch convolution), 并将其与U-Net网络相结合, 有效减轻了图像去雾过程中的细节丢失问题; 将由通道注意力机制和像素注意力机制组合成的ATT (Attenion)块引入到图像去雾模块中, 提高了模块的特征提取能力, 抑制了与当前任务不相关的特征, 进一步减轻了去雾过程中颜色失真和对比度下降问题。在细节增强模块中, 将经过图像去雾模块后的图像输入到细节增强模块中进一步恢复图像的细节信息, 使图像更趋近于真实域中的图像。图像去雾模块与细节增强模块相结合提升了网络的泛化能力, 使其在有雾数据集中具有更好的适应能力。实验在公开数据集ITS、Haze4K与公开真实数据集IHAZE上进行, 在定量客观分析比较中, 平均峰值信噪比和平均结构相似性的数值分别达到了39.69 dB和0.994, 相较于对比网络模型中的最优算法有一定提升。在主观视觉分析中, 经过DBDENet网络去雾后的图像在细节、颜色、对比度等方面相较与所提对比算法更接近于真实无雾图像。
Key words: difference convolution / depth-separable convolution / image dehazing / attention mechanism
关键字 : 差分卷积 / 深度可分离卷积 / 图像去雾 / 注意力机制
© 2025 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
图像去雾在视觉领域中属于基础应用, 在雾天时, 图像生成过程中光线会发生散射或者出现光线被吸收的情况, 使得采集到的户外图像受到严重的损害, 所以雾天图像通常表现出模糊、对比度低、颜色失真等视觉质量差的问题。在后续的高级视觉任务如目标检测、自动驾驶等工作中, 雾天图像会严重影响其任务可靠性。图像去雾算法大体可以分为2种类型, 一种基于传统算法实现, 另外一种基于深度学习算法实现。
传统去雾算法应用比较广泛的有Retinex算法[1]、直方图均衡化算法[2]等。此类算法仅通过增强图像的对比度、饱和度和清晰度等实现图像去雾, 会对图像的细节信息和颜色等方面造成损害, 所以整体去雾效果一般。基于物理模型的去雾算法主要考虑雾的成像原理、光的散射和衰减建立模型。通过获取图像的过程建模, 之后根据相应的先验知识结合建立的模型, 解出其中的去雾图像。Fattal[3]于2008年提出了一种基于物理模型的方法, 该方法假设图像的反射率在局部区域内是恒定的, 同时场景中的颜色与空气介质之间相互独立, 随后利用独立成分分析和马尔可夫模型实现去雾。但该方法只有在薄雾的场景中才能取得良好的效果。He等[4]在2010年提出的暗通道先验去雾(dark channel prior, DCP)是影响力较大的基于物理模型的方法之一, DCP认为对于室外图像, 无雾图像局部块中至少有1个颜色通道的强度接近于0, 基于上述原理, DCP从雾天图像中估计透射率图, 并结合简单的全局大气光估计得到去雾图像。随后, 针对暗通道先验去雾算法的不足, 学者提出了一系列的改进算法[5–6]。然而, 基于物理模型的去雾方法通过经验统计获取先验知识,并利用该先验推导出透射图。当场景不满足这些先验时, 它们可能导致结果中存在严重误差, 最著名的案例是DCP在天空区域中表现较差。
上述传统基于物理模型的去雾算法在特定场景下取得了一定的去雾效果, 但它们往往依赖于特定场景的先验知识。在实际应用中, 复杂多变的自然环境和光照条件使得这些算法的通用性和鲁棒性受到限制。因此, 如何开发出一种更加通用、高效的去雾算法成为了当前的研究热点。近年来随着深度学习技术的发展, 基于深度学习的算法应用越来越广泛, 这类算法通过构建深度神经网络模型, 从大量数据中学习去雾的映射关系, 这种学习方法提高了模型对不同场景下图像去雾的适应性, 其网络模型较传统去雾算法来说具有更广泛的通用性。Cai等[7]于2016年设计了DehazeNet去雾网络, 此网络结合复原算法中的假设和先验信息得到复原结果。同年, Ren等[8]提出了一种多尺度网络结构MSCNN, 此网络使用粗尺度网络提取透射率信息并用细尺度网络优化透射率。DehazeNet和MSCNN由于透射率的单独训练, 其去雾结果存在不稳定性。2017年, Li等[9]提出了AOD-Net网络模型, 此模型仅使用轻量级的主干网络即可获得良好的去雾性能。但此网络没有深入分析图像特征, 导致去雾结果存在亮度偏暗和去雾不彻底现象。2020年, Qin等[10]提出了一种端到端的FFA-Net网络模型, 并在此网络中提出了包含通道注意力和像素注意力的特征注意力模块, 有效提高了图像去雾性能, 但此网络去雾后的部分图像出现了颜色失真现象。Yuda等[11]于2022年提出了一种基于U-Net的gUnet网络, 其在去雾过程中有较好的效果, 但此网络在除雾过程中很难保留原始图的细节信息, 出现去雾后细节信息丢失等问题。综上, 当前基于深度学习的去雾算法虽然提升了网络的通用性和鲁棒性,但算法依然存在特征提取不充分的问题, 缺乏保持图像原有的一些细节信息的能力, 导致去雾过程出现细节丢失、颜色失真、对比度下降等问题。
针对上述问题, 本文在U-Net基础上提出了DBDENet去雾网络模型算法。该网络主要采取2种措施以解决图像去雾过程中的细节丢失、颜色失真、对比度下降等问题。第1种措施是在保证图像去雾效果的基础上尽可能多地提取图像的纹理和梯度等细节信息, 以提高图像去雾过程的质量。第2种措施是通过有效的细节增强模块恢复去雾过程中丢失的细节信息, 使图像更接近真实域中的图像。算法的主要贡献如下: ①算法设计了一种独立的双分支卷积块DBConv, 该卷积块中包含深度可分离卷积和差分卷积, 以提取图像中更多纹理特征; ②在网络中引入了像素注意力和通道注意力融合的ATT块[10], 以提升网络的有效特征提取能力, 同时抑制了与当前任务不相关的特征; ③网络中的细节增强模块能够同时提取图像的局部和全局信息, 并在不损失图像分辨率情况下增强经过图像去雾处理后的图像细节, 使得去雾图像更加接近真实场景中的图像。④在公开数据集上进行了广泛对比实验及消融实验, 验证了子模块的有效性, 及整体网络的优越性。
1 双分支卷积结合细节增强的图像去雾
本节介绍双分支卷积结合细节增强图像去雾网络DBDENet。双分支卷积结合细节增强图像去雾网络包含图像去雾模块和细节增强模块两部分。首先将输入的有雾图像送入图像去雾模块中, 在保证去雾效果的同时增加细节保持能力; 之后将生成的去雾图像送入细节增强模块中进行细节增强, 使去雾后的图像更接近真实域中的图像。下面将具体介绍网络的2个子模块。
1.1 图像去雾模块
图像去雾模块如图 1中绿色方框标出部分所示, 此模块可以看作U-Net模型的变体, 将U-Net的基础卷积块替换为包含深度可分离卷积和差分卷积的双分支卷积块DBConv, DBConv可以帮助图像去雾模块提取图像中细节信息并高效聚合提取的特征, 实现更好的去雾效果。在模块中引入了包含通道注意力和像素注意力的ATT块, 有效增强了图像去雾模块的特征表示能力, 此外, 此模块中使用ATT块对来自下采样不同路径的特征图进行动态融合, 进一步提高了模块提取特征的能力。本文网络的下采样部分使用大小为3×3为且步长为2的卷积核进行卷积操作, 逐渐减小特征图的尺寸和通道数, 提取低级别特征。在上采样部分则由1×1卷积与像素重组(PixelShuffle)上采样操作构成, 将低分辨率图像恢复至原始图像大小。
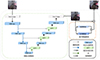 |
图1 双分支卷积结合细节增强图像去雾网络架构图 |
1.2 双分支卷积块
如图 2所示, 双分支卷积块DBConv主要由BatchNormal层、差分卷积分支、深度可分离卷积分支、门控机制构成。给定1张输入特征图, 特征图首先经过BatchNormal层, 对其进行归一化处理, 经过归一化处理的数据分别进入卷积块的2个分支, 如图 2所示。
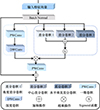 |
图2 双分支卷积块架构图 |
差分卷积分支由3个差分卷积以及Sigmoid函数构成, 深度可分离卷积分支由一维卷积和深度卷积构成。
双分支卷积块DBConv的差分卷积分支中3个差分卷积分别为中心差分卷积、角度差分卷积、水平垂直差分卷积。其中中心差分主要用于提取保留图像的边缘信息。角度差分主要用于提取保留图像的纹理和方向信息。水平和垂直差分主要用于提取保留图像的梯度信息。三者的混合使用可以更全面地提取并保留图像相关差异的细节信息, 帮助增强网络去雾效果。
在差分卷积分支中首先将归一化后的特征图X经过3个差分卷积的运算, 提取的特征之后由Sigmoid函数得到X1的输出, 如(1)式所示。
 (1)
(1)
式中: DC1为角度差分卷积;DC2为中心差分卷积;DC3为垂直差与水平差分卷积的混合。⊕表示将运算结果逐像素相加。X为归一化之后的结果。
DBConv的深度可分离卷积包含一维卷积和深度卷积, 与普通卷积相比, 其在降低运行参数量的同时, 有效提取了图像的局部特征。经过深度可分离卷积之后得到了结果X2, 如(2)式所示。
 (2)
(2)
式中: Pwconv表示一维卷积; Dwconv表示深度卷积; X表示经过归一化之后的结果。
得到X1, X2之后, 选择深度可分离卷积分支的输出X2作为差分卷积分支X1的门控信号, 使用另一个一维卷积进行投影。提高网络对图像细节的保持能力, 减轻网络在去雾过程中出现的细节丢失问题。使用门控机制可以有效地提高网络的表达能力, 这在图像复原任务中比较常见。投影之后的结果与最初的输入进行加和操作得到DBConv块的输出。
1.3 注意力模块
如图 3所示, 注意力模块ATT[10]主要由通道注意力和像素注意力构成。其中ATT块中的通道注意力帮助模型识别和保留图像中的正确颜色分布, 而像素注意力则确保这些颜色信息在图像中的适当位置得到处理。这种双重关注策略有助于减少颜色失真, 对比度下降的问题。使得去雾后的图像色彩更加自然和真实。
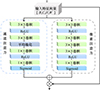 |
图3 注意力模块图 |
通道注意力模块和像素注意力模块的具体结构如图 3所示, 通过卷积、标准化、激活函数等操作, 计算输入特征图在通道维度和像素维度的注意力权重。
在ATT块中, 其输入包括下采样层的特征映射与上采样层的特征映射(跳过连接)。ATT块首先将2种输入特征拼接起来。之后拼接的特征图分别经过通道注意力和像素注意力模块计算像素和空间通道的注意力权重。最后, 将权重相加后利用最终注意力权重对输入特征图进行加权求和, 得到融合后的特征图作为ATT块的输出,如(3)式所示。
 (3)
(3)
式中: CA表示点通道注意力;PA表示像素注意力;X ∈[B, C, H, W]表示经过拼接之后的特征图;⊕表示通道注意力权重和像素注意力权重的相加操作;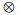 表示拼接后的特征图与所求注意力权重的相乘操作。
表示拼接后的特征图与所求注意力权重的相乘操作。
1.4 细节增强模块
在进行图像去雾的过程中, 会不可避免地丢失一些细节信息。因此在此网络中添加了细节增强模块, 用于增强图像中的内在细节。细节增强模块为图 1橙色方框标出的部分, 具体结构图如图 4所示, 细节增强模块包含全局细节增强和局部细节增强, 全局细节增强用于提取多尺度的全局特征, 局部细节增强针对图像的局部细节特征。
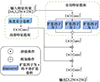 |
图4 细节增强模块图 |
局部细节增强部分采用一个角度差分卷积和1×1的浅层卷积实现局部特征提取,如(4)式所示。
 (4)
(4)
式中:x代表输入特征向量;x ∈[64, 3, 256×256]表示输入数据x的批量大小为64, 通道数为3, 大小为256×256;ADC表示角度差分卷积;DC表示1×1的浅层卷积。X1代表局部细节增强的输出。
全局细节增强通过平滑扩张卷积来实现, 平滑扩张卷积不会造成图像分辨率的损失。在全局细节增强中, 输入特征映射首先经过1个1×1的卷积层, 然后通过3个扩张因子分别为1, 2, 3的平滑扩张卷积用于提取多尺度全局特征, 之后将得到的不同尺度的全局特征拼接在一起。再通过1×1卷积层实现信道间的信息融合, 如(5)~(6)式所示。
 (5)
(5)
 (6)
(6)
式中:x代表输入特征向量,x ∈[64, 3, 256×256];DC表示1×1的卷积操作。Dl1代表扩张因子为1的平滑扩张卷积;Dl2代表扩张因子为2的平滑扩张卷积;Dl3代表扩张因子为3的平滑扩张卷积;⊙代表拼接操作;Y代表得到的多尺度的全局特征经过拼接之后的结果;X2代表调整信道数之后的全局细节增强模块的输出。
在经过全局细节增强提取全局信息之后, 将之前提取到的局部信息通过2次加法操作融入提取到的全局信息中, 每个加法操作之后都跟随1个卷积层, 通过将级联特征映射传递到这2个卷积层, 进一步进行通道调整和信息融合, 得到最终的输出特征映射,如(7)式所示。
 (7)
(7)
式中:X1代表局部细节增强部分的输出特征;X2代表全局细节增强的输出特征, ⊕代表加法融合操作;DC代表 1×1的卷积操作。Y代表细节增强模块的最终输出, Y ∈[3, 256×256]表示输出为三通道256×256大小的图片。
2 实验与结果
2.1 实验设置与数据集
实验平台CPU型号为12 CPU Intel(R) Xeo-n(R) Platinum 8255C, 主频为2.50 GHz, 内存为43 GB, 显卡为RTX3090, 显存为24 GB。实验的深度学习框架采用Pytorch1.8.1, Python版本3.8, CUDA版本为11.1。DBDENet网络训练时输入的图片大小为256×256, 训练的批量大小为64, 初始学习率为8×10-4, 训练迭代次数为1 000。网络使用AdamW优化器(β1=0.9, β2=0.999)和余弦退火策略来训练模型, 其中学习率从初始学习率逐渐降低到8×10-6。
为了验证所提方法的有效性, 使用了ITS、Haze4K、IHAZE这3个数据集数进行实验。ITS室内数据集, 包含13 990张合成模糊图像。Haze4K数据集是融合了室内数据和室外数据的1个混合数据集, 总共包含了4 000个图像对。IHAZE数据集中包含35个有雾图像和相应的无雾室内图像, 此数据集中的雾霾图像是使用专业雾霾机产生的真实雾霾生成的。图像是在受控环境中捕获的, 因此无雾和有雾图像都是在相同的照明条件下捕获的。
为了验证算法的有效性, 本文算法主要与DCP[4]算法、DehazeNet[7]算法、AOD-Net[9]算法、FFA-Net[10]算法、gUnet-T[11]算法、MSBDNet[12]算法、DMT-Net[13]算法、PFDN[14]算法、AECR-Net[15]算法、DeHamer[16]算法及UDN[17]算法进行比较。
2.2 损失函数
本文采用了平滑L1损失函数, 平滑L1损失函数能够直观地衡量网络的输入与输出之间的差异。函数可表示为
 (8)
(8)
 (9)
(9)
式中:N表示图像的总像素数;i表示图像的第i个像素;F表示有雾图像经过网络之后输出的无雾图像;J表示有雾图像对应的真实无雾图像;x表示输出图像与真实图像之间的差距。
2.3 定量客观分析
为了从客观角度评价本文DBDENet模型去雾效果的优劣性, 本文定量求解对比网络在ITS和Haze4K这2个公共数据集上去雾结果的平均峰值信噪比(PSNR)和平均结构相似性(SSIM)。PSNR值越高, 代表图像质量越好、失真越少、处理后图像与清晰图像之间误差越小。SSIM用于衡量2幅图像相似程度, SSIM值越接近于1代表 2幅图结构越相似。结果如表 1~2所示。
各算法在混合数据集Haze4K中PSNR和SSIM的值
各算法在室内数据集ITS中PSNR和SSIM的值
表 1展示了不同去雾算法在Haze4K数据集上的实验结果, 由表 1可知, DBDENet网络的PSNR值优于表 1中所提到的其他先进算法, SSIM值与表 1中提到的先进算法中最高值相同。表 2显示了不同去雾算法在ITS数据集上的实验结果, 由表 2可知DBDENet在ITS数据集中的PSNR和SSIM值优于表 2中所提到的其他先进算法。
从表 1和表 2中的平均指标上面可以看出, 本文去雾算法在2个数据集中的定量指标PSNR和SSIM上都取得了最好的结果, 表明DBDENet网络可以有效提高去雾图像的质量。
2.4 主观视觉分析
主观视觉分析以上述定量客观分析中的网络作为基础, 分别在3个数据集中进行主观视觉分析。对于Haze4K数据集与ITS数据集, 选择了较好且经典的4个网络与本文模型进行实验。对于IHAZE真实数据集, 其数据较少不足以对网络进行更好训练, 且其数据为室内数据, 因此, 采用同为室内数据的ITS数据集训练出来的网络, 且对比网络与ITS数据集的对比网络相同。
图 5显示了DBDENet去雾网络与对比网络在Haze4K数据集室外图像上的对比结果, 从图 5b)的主观视觉分析可以看出, AOD-Net网络去雾结果中有雾的残余, 效果不彻底。图 5c)对应的FFA-Net网络对于景深较大的区域无法做到完全去雾。由图 5d)DMT-Net网络的第2幅图树影部分来看, 图像出现细节丢失的现象。从图 5e)gUnet-T网络可以看出,去雾后的结果图整体颜色偏暗, 图像出现了对比度下降问题。同时图 5e)在第2幅图像的天空区域出现了颜色失真现象。从图 5f)中可以看出本文网络的去雾效果在色彩和细节还原度上均优于其他对比算法, 去雾后图像颜色更自然, 保留了更多的图像细节信息。
 |
图5 混合数据集Haze4K中各算法主观对比图 |
图 6展示了DBDENet网络与对比网络在ITS数据集中的室内雾图去雾结果比较。从图 6b)~6c)可以看出AOD-Net网络与FFA-Net网络的去雾结果图中有少量雾的残余。从图 6d)~6e)可以看出,AECR-Net网络与gUnet-T网络去雾后的图像相较于真实无雾图颜色偏深, 出现颜色失真和对比度下降问题。从图 6f)可以看出,本文去雾后图像的网络复原结果更加清晰, 在高频区域复原颜色正常, 更接近自然图像。
 |
图6 室内数据集ITS中各算法主观对比图 |
图 7显示了DBDENet网络与对比网络在IHAZE数据集上的对比结果, 可以看出, 其他去雾网络在处理图像时, 往往存在难以彻底去除的雾残余问题, 如图 7c)~7e)所示, 或者不可避免地有颜色偏差问题(见图 7b))。本文算法相较于其他对比网络来说, 去雾结果与真实无雾图在细节、颜色、对比度方面的主观差异更小, 在去雾过程中, 很好地保留了图片的颜色和细节信息, 更符合人眼的视觉感知。
 |
图7 真实数据集IHAZE中各算法主观对比图 |
图 8~9为Haze4K测试集与ITS测试集SOTS-IN的视觉主观局部放大效果比较。从图 8~9可以看出, 其他网络出现了颜色失真和去雾不完全的情况。而本文网络相较于其他网络在色彩细节方面与真实图像最为接近。
 |
图8 混合数据集Haze4K中各算法图像去雾局部放大图 |
 |
图9 室内数据集ITS中各算法图像去雾局部放大图 |
图 10为IHAZE数据集的视觉主观局部放大效果比较, 可以看出其余算法出现了细节缺失、颜色失真和对比度下降的问题, 而本文方法(见图 10f))去雾后的图像细节和色彩更接近真实无雾图像。表明本文算法对颜色失真、细节缺失、对比度下降等状况有一定改善, 可以获得较好的视觉体验。
 |
图10 真实数据集IHAZE中各算法图像去雾局部放大图 |
相较于对比算法, 本文去雾算法在保持PSNR和SSIM上最好结果的同时, 去雾后的图片在细节保留与色彩亮度还原方面更为贴近真实无雾图像。这充分证明, 本文网络在图像去雾过程中能够有效缓解细节丢失、颜色失真、对比度下降等问题。
2.5 消融实验结果及分析
为了验证算法中各模块有效性, 对使用的3个模块(DBConv、ATT、细节增强模块)在Haze4K数据集上进行了消融实验。本文基础网络为1个U-Net的去雾网络。
表 3总结了算法中提出的模块性能指标, 从表 3中可以看出加入DBConv块、ATT块与细节增强模块之后的网络相较于基础网络,PSNR值和SSIM值都有较明显上升, 验证了算法所提模块的有效性。同时从图 11展示的消融实验可视化效果来看, DBConv块在去雾过程中恢复了图像的更多细节信息, 同时提升了网络的泛化性。细节增强模块使去雾后的图像更接近于真实域中的图像, 证明了本文提出模块的有效性。
不同模块的消融实验
 |
图11 混合数据集Haze4K模块消融实验对比图 |
为了验证DBConv中3种类型融合差分卷积的有效性, 本文进行了如表 4所示的消融实验。
双分支卷积模块DBConv中差分卷积在Haze4K数据集中的消融实验
表 4中相较于其他3个模型, 模型W对图像去雾评价指标的提升更为明显, 同时从图 12结果来看, 模型F、G、H的去雾图像在天空区域出现颜色不连续现象。而模型W的去雾结果并未观察到天空区域出现块状分布或者视觉上的显著不连续性问题。表明本文使用的3种差分卷积的混合更完整地提取了图像的相关细节信息, 使得去雾后的图像更加接近于真实域中的图像。
 |
图12 混合数据集Haze4K差分卷积消融实验对比及其区域放大图 |
2.6 泛化实验结果及分析
为了验证DBDENet的泛化性, 设置了如下实验:对在ITS数据集上训练得到的AOD-Net、FFA-Net、MSBDN网络和gUnet-T网络与本文网络, 在Haze4K数据集中进行跨数据集测试。
实验结果如表 5所示,其中包含2种评估数据:ITS标签数据代表网络在ITS数据集上完成训练与测试的结果,Haze4K标签数据则为网络在ITS数据集训练后迁移至Haze4K测试集的表现。跨数据集测试结果表明,gUnet-T网络在Haze4K测试中表现出较强的泛化能力,其PSNR值下降12.95 dB、SSIM值下降0.043,位列性能衰减幅度前2位;本文提出的网络模型则展现出最优的跨域稳定性,PSNR与SSIM分别下降11.87 dB和0.038,成为所有对比模型中指标衰减最小方案。其余对比模型在Haze4K数据集上的性能衰减幅度均显著高于上述2个模型。
室内数据集ITS上各训练模型在混合数据集Haze4K中的泛化实验
这一结果表明, 本文提出的网络模型在跨数据集测试中, 相较于其他网络能够较好地保持其性能, 有较强的泛化性。这说明模型相较于其他网络能够较好地适应和处理新的数据, 具有较好的泛化性能。
3 结论
如前所述, 针对当前图像去雾过程中出现的细节丢失、颜色失真、对比度下降的问题, 本文提出了DBDENet去雾网络模型。在模型中首先设计了DBConv块以减轻图像去雾过程中的细节丢失问题的问题。其次, 使用注意力ATT块提取并优化特征处理和信息传递, 减少去雾过程出现的颜色失真和对比度下降的问题。之后, 加入图像增强模块, 以减小去雾图与真实无雾图之间的差异。最后, 客观和主观的实验结果表明, DBDENet模型所提改进措施优化了现有算法出现的如细节丢失、颜色失真、对比度下降的问题, 提升了模型性能。同时本文设计的双分支卷积模块对于需要保留图像细节信息的网络模型有一定的参考价值。
References
- JIANG B, WOODELLl G A, JOBSON D J. Novel multi-scale retinex with color restoration on graphics processing unit[J]. Journal of Real-Time Image Processing, 2015, 10: 239–253. [Article] [Google Scholar]
- STARK J A. Adaptive image contrast enhancement using generalizations of histogram equalization[J]. IEEE Trans on Image Processing, 2000, 9(5): 889–896 [NASA ADS] [CrossRef] [Google Scholar]
- FATTAL R Single image dehazing[J]. ACM Transactions on Graphics, 2008, 27(3): 1–9 [Google Scholar]
- HE K, SUN J, TANG X. Single image haze removal using dark channel prior[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2010, 33(12): 2341–2353 [Google Scholar]
- YANG Yan, WANG Zhiwei. Adaptive image dehazing algorithm based on mean unequal relation optimization[J]. Journal of Electronics&Information Technology, 2020, 42(3): 755–763 (in Chinese) [Google Scholar]
- WANG J B, HE N, ZHANG L L, et al. Single image dehazing with a physical model and dark channel prior[J]. Neurocomputing, 2015, 149: 718–728. [Article] [Google Scholar]
- CAI B, XU X, JIA K, et al. Dehazenet: an end-to-end system for single image haze removal[J]. IEEE Trans on Image Processing, 2016, 25(11): 5187–5198. [Article] [NASA ADS] [CrossRef] [Google Scholar]
- REN W, LIU S, ZHANG H, et al. Single image dehazing via multi-scale convolutional neural networks[C]//14th European Conference on Computer Vision, Amsterdam, the Netherlands, 2016: 154–169 [Google Scholar]
- LI B, PENG X, WANG Z, et al. Aod-net: all-in-one dehazing network[C]//Proceedings of the IEEE International Conference on Computer Vision, 2017: 4770–4778 [Google Scholar]
- QIN X, WANG Z, BAI Y, et al. FFA-net: feature fusion attention network for single image dehazing[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2020: 11908–11915 [Google Scholar]
- DAI L, LIU H, LI S. MSNet: A multistage network for lightweight image dehazing with content-guided attention and adaptive encoding[J]. Electronics, 2024, 13(19): 1–12. [Article] [Google Scholar]
- DONG H, PAN J, XIANG L, et al. Multi-scale boosted dehazing network with dense feature fusion[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 2157–2167 [Google Scholar]
- LIU Y, ZHU L, PEI S, et al. From synthetic to real: image dehazing collaborating with unlabeled real data[C]//Proceedings of the 29th ACM International Conference on Multimedia, 2021: 50–58 [Google Scholar]
- DONG J, PAN J. Physics-based feature dehazing networks[C]//16th European Conference on Computer Vision, Glasgow, UK, 2020: 188–204 [Google Scholar]
- WU H, QU Y, LIN S, et al. Contrastive learning for compact single image dehazing[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 10551–10560 [Google Scholar]
- GUO C L, YAN Q, ANWAR S, et al. Image dehazing transformer with transmission-aware 3D position embedding[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 5812–5820 [Google Scholar]
- HONG M, LIU J, LI C, et al. Uncertainty-driven dehazing network[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2022: 906–913 [Google Scholar]
All Tables
All Figures
|
图1 双分支卷积结合细节增强图像去雾网络架构图 |
| In the text | |
|
图2 双分支卷积块架构图 |
| In the text | |
|
图3 注意力模块图 |
| In the text | |
|
图4 细节增强模块图 |
| In the text | |
|
图5 混合数据集Haze4K中各算法主观对比图 |
| In the text | |
|
图6 室内数据集ITS中各算法主观对比图 |
| In the text | |
|
图7 真实数据集IHAZE中各算法主观对比图 |
| In the text | |
|
图8 混合数据集Haze4K中各算法图像去雾局部放大图 |
| In the text | |
|
图9 室内数据集ITS中各算法图像去雾局部放大图 |
| In the text | |
|
图10 真实数据集IHAZE中各算法图像去雾局部放大图 |
| In the text | |
|
图11 混合数据集Haze4K模块消融实验对比图 |
| In the text | |
|
图12 混合数据集Haze4K差分卷积消融实验对比及其区域放大图 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.