| Issue |
JNWPU
Volume 37, Number 3, June 2019
|
|
|---|---|---|
| Page(s) | 515 - 522 | |
| DOI | https://doi.org/10.1051/jnwpu/20193730515 | |
| Published online | 20 September 2019 | |
Memory Compact High-Speed QC-LDPC Decoder Based on FPGA
存储紧缩性高速QC-LDPC译码器的FPGA实现
1
School of Electronics and Information, Northwestern Polytechnical University, Xi’an, 710072, China
2
China Academy of Space Technology, Xi’an, 710010, China
Received:
20
May
2018
Abstract
In this paper, two compact memory strategies for partially parallel QC-LDPC decoder architecture are proposed. By compacting several adjacent rows hard decisions and extrinsic messages into one memory entry, which not only reduces the number of memory banks for hard decisions, but also facilitates multiple data accesses per clock cycle so as to increase the throughput of decoder. We demonstrate significant high speed and area efficient benefits of using the proposed techniques with an FPGA implementation of a CCSDS LDPC decoder on Xilinx XC5VLX330 device. The result shows that our new decoder can operate at a maximum frequency of 250 MHz after place and route, and achieve a throughput up to 2 Gb/s at 14 iterations.
摘要
提出了一种高速部分并行准循环低密度奇偶校验码(quasi-cyclic low density parity check codes,QC-LDPC)译码器架构和该架构下的2种紧缩性存储策略,采用将多个相邻行的硬判决码字和外信息压缩到一个存储单元、硬判决待输出码字信息紧缩性存储及相对应的高速译码器架构,不仅减少了用于硬判决码字的存储块的数量,而且可以便于一个时钟周期内对多个数据同时进行访问并处理,从而提高了译码器的数据处理吞吐量。通过采用Xilinx XC4VLX160 FPGA实现CCSDS标准中的LDPC译码器验证了文中提出的这种紧缩性存储策略及其高速译码器架构可以有效地利用FPGA资源来实现高速译码器,实现结果显示该译码器在布局布线后时钟频率可以工作在250 MHz,译码器采用14次迭代,对应2 Gb/s的译码吞吐量。
Key words: quasi-cyclic low density parity check codes (QC-LDPC) / LDPC decoder / BRAM memory / FPGA / CCSDS / hard decisions / throughput
关键字 : QC-LDPC码 / LDPC译码器 / BRAM存储器 / FPGA / CCSDS
© 2019 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
近年来由于误码率(bit error rate, BER)性能非常接近香农极限和内在的并行译码特性, 低密度奇偶校验(low density parity check codes, LDPC)码[1]引起了极大的关注。作为LDPC的一个特殊子类, 准循环LDPC(quasi-cyclic LDPC, QC-LDPC)码不仅具有与随机LDPC相比拟的性能, 而且可以方便地采用移位寄存器编码[2], 有效地采用部分并行译码器架构进行译码[3-11]。因此, QC-LDPC码已被作为最近的先进通信和存储系统的前向纠错编码标准, 如数字视频广播(DVB-S2)、中国移动多媒体广播(CMMB)、广义无线接入网(WIMAX)、无线局域网(WiFi)及空间通信(CCSDS)等标准。
由于准循环结构的LDPC码在硬件实现复杂度和译码吞吐量之间具有好的折衷性, 现阶段有许多关于QC-LDPC译码器的研究, 其中对存储有效的部分并行架构的研究尤其多(见文献[3-11])。然而, 一般来说, LDPC码要具有优异的译码性能其码长一般较长(例如几千比特), 且需要采用基于置信度传播的迭代软判决译码算法, 在译码迭代过程中必须使用存储器存储大量的中间运算数据, 因此, 需占据大量的硬件资源, 这将极大地限制译码器的吞吐量性能, 为了降低存储资源且不损失误码性能, 现阶段提出了许多有效的架构[3-11]。文献[3]采用多个运算单元同时处理来自不同m个行块的(或n个列块)的信息, 需要m×n个存储器来存储判决信息, 文献[4]中, 在PCU(parity computer unit)阶段, 可以观察到硬判决存储器仅为读模式, 采用双端口存储器将硬判决存储器个数可以减半, 即 个。文献[5]采用的译码架构没有考虑伴随式为零提前终止译码的情况, 会消耗大量功耗且不利于空闲时序的充分利用[6], 文献[7-9]均采用BRAM来实现译码器架构, 而这些考虑提前终止译码器的文章中均需要额外的存储器来存储硬判决码字, 一般来说, 这些硬判决码字占整个译码器存储块比例较大, 本文作者在文献[10-11]中计算了这部分存储资源占总资源的比例, 并给出了中低速QC-LDPC译码器如何来节省这部分资源的存储方法。
个。文献[5]采用的译码架构没有考虑伴随式为零提前终止译码的情况, 会消耗大量功耗且不利于空闲时序的充分利用[6], 文献[7-9]均采用BRAM来实现译码器架构, 而这些考虑提前终止译码器的文章中均需要额外的存储器来存储硬判决码字, 一般来说, 这些硬判决码字占整个译码器存储块比例较大, 本文作者在文献[10-11]中计算了这部分存储资源占总资源的比例, 并给出了中低速QC-LDPC译码器如何来节省这部分资源的存储方法。
以前期工作[10-11]的研究为基础, 本文提出了硬判决码字与外信息共享存储器和硬判决待输出码字信息紧缩的2种存储方法及其对应的高速译码器架构, 可无存储访问冲突地应用于任意并行度的QC-LDPC译码器。本文提出的这种紧缩性存储策略不仅需要的存储块资源更少, 而且能节省访问多个存储器的地址资源, 这就保证了本架构的QC-LDPC译码器能在有限的FPGA资源中实现更高的译码吞吐量。
1 LDPC背景知识
1.1 LDPC码基础
LDPC码可以用一个M×N的稀疏校验矩阵H来描述, H矩阵中大部分元素是0, 只有少部分1。M表示校验方程的个数, 也表示校验节点的个数。而N表示码长及变量节点的个数。矩阵行中1的个数为行重dc, 列中1的个数为列重dv。当dc和dv为常数时LDPC码为规则LDPC码, 否则为非规则LDPC码。
最常用的LDPC码是QC-LDPC码, QC-LDPC码的H矩阵结构可以被分为m×n个子矩阵, 即基矩阵, 每个基矩阵均为L×L的方阵, 即M=m×L和N=n×L。基矩阵m×n中的每个1元素均可由一个L×L的单位矩阵向右循环移位来扩展。这种结构的校验矩阵使硬件设计时很容易确定非零元素的位置, 它使Tanner图的随机连接变得有规律易处理。因此, QC-LDPC码的这些特性使它非常适合硬件实现。
1.2 LDPC译码算法
典型的LDPC译码算法为和积译码(SPA)[12], SPA提供了一种强有力的译码方法, 但这种方法的复杂度大且实现时对量化长度很敏感。最小和算法(MSA)[13]仅在校验节点处理时做了一个近似, 其他地方与SPA类似。硬件实现中最常用的派生MSA是归一化最小和算法(NMSA)[13], 在第i次迭代, NMSA的校验节点更新单元(CNU)采用下面的公式计算校验节点到变量节点(C2V)的更新信息Rmn(i)
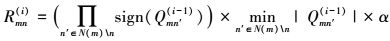 1
1
这里引入归一化因子α来补偿MSA简化SPA的损失。Qmn是变量节点到校验节点的信息(V2C), N(m)表示与校验节点m相连的变量节点集合。N(m)\n表示不包括变量节点n与校验节点m相连的变量节点集合。
在第i次迭代, 变量节点处理单元(VNU)计算Qmn(i)和Qn(i)的公式如下
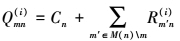 2
2
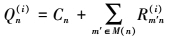 3
3
M(n)表示与变量节点n相连的校验节点集合, 即H矩阵第n列中1对应的校验节点; 同理M(n)\m表示从集合M(n)中去掉元素m之后的子集。Cn表示连接变量节点n的信道信息(或内信息)。
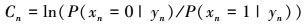 4
4
这里C2V和V2C均为外信息。译码将一直重复迭代直到校验方程(由校验方程计算模块(PCU)来判断)满足或达到预先设定的最大迭代次数为止。
1.3 传统的QC-LDPC译码器架构
对于一个规则QC-LDPC码的校验矩阵, 它由m×n个行列重均为1的L×L子矩阵构成。类似于文献[3-4]中典型的部分并行译码器架构, 如图 1所示。
m个n输入CNUs, n个m+1输入VNUs和m个n输入PCUs联合完成译码器的处理过程。这里PCUs表示校验方程判决单元, 来进行校验方程计算和迭代判决功能。CNUs, VNUs和PCUs统称为处理单元PUs。除了PUs, 本架构还需要m×n个RAMM存储器Ms, t(1≤s≤m, 1≤t≤n)用来存储VNUt和CNUs处理过程中交换的外信息。n个RAMF存储块Ft(1≤t≤n)用来存储信道信息。m×n个RAMC存储器Cs, t(1≤s≤m, 1≤t≤n)用来存储判决信息。这里, Q表示采用Q bits量化。为了避免数据访问冲突, 所有的存储块均采用双端口RAM, 一个端口读另外一个端口写。每个存储块包含L个存储单元。
对于QC-LDPC码, 存储器RAMM的地址产生器可以简化, 在VNU阶段, 地址产生器连续产生地址0, 1, …, L。在CNU和PCU阶段, 地址产生器顺序产生地址βs, t, βs, t+1, …0, 1, …βs, t-1。这里βs, t为QC-LDPC码的循环移位值。因此, 地址产生器可以简单地用模L计数器来实现。每个RAMM存储器连接一个模L计数器来产生相应的存储器地址。
 |
图1 传统的QC-LDPC译码器结构框图 |
2 本文提出的紧缩性存储策略
2.1 硬判决信息和外信息共享存储策略
PCU用来做校验方程计算, 显然, PCUs和CNUs是同时进行工作的, 因为当VNUs为CNUs产生外信息时, 它同时产生校验方程所需要的硬判决信息(见公式(3))。为了匹配CNUs和VNUs的并行度, 类似于CNUs, m个PCUs同时对m个行块的校验方程进行计算, 而m个行块内的校验方程串行进行计算。每个PCUs需要n个硬判决信息, 所以在一个时钟周期需要从存储器中同时读出m×n个硬判决信息。为了避免上面描述的存储器访问冲突, 一个直接的方法[3]是采用m×n个Cs, t(1≤s≤m, 1≤t≤n)来存储判决信息, 每个存储单元存储位宽为1 b, 深度为L。在Xilinx FPGA中, 一个18 kb block RAM构成一个存储块。所以仅PCU就需要m×n个存储器, 按照传统的QC-LDPC译码器架构, 译码器共需要2m×n+n个存储器。
在前期研究的文献[4]中, 也考虑了降低硬判决存储块的方法, 在PCU阶段, 可以观察到硬判决存储器仅采用读模式, 因为采用了双端口存储器, 所以硬判决存储器个数可以减半, 即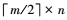 个。这种改进方法将译码器总存储个数降为m×n+
个。这种改进方法将译码器总存储个数降为m×n+ 个。
个。
在FPGA实现时, 另外一种采用长位宽的移位寄存器来存储硬判决信息, 不仅占用大量的逻辑资源, 而且导致极大的关键路径延迟, 这对高速设计是很不利的。
然而, 我们观察到当CNU和PCU同时工作时, 相应的m×n个外信息(确切来说是变量节点到校验节点的信息, 即V2C)和m×n个硬判决信息需要从Ms, t和Cs, t中分别读出。同时, 很关键的一点是CNU所需的外信息和PCU所需的判决信息来自于相同的行, 所以CNU和PCU需要从存储器的同一个地址βs, t, βs, t+1, …, L-1, 0, 1, …, βs, t-1中读取数据。
从上面的分析, 与传统的分开存储外信息和硬判决信息的方法不同, 我们采用将2种外信息和判决信息封装到同一个存储单元, 取决于它们的地址相同, 所以可以避免存储器访问冲突。外信息和硬判决信息合并的存储器RAMMC定义为MCs, t, 如图 2所示。当并行度p>1时, MCs, t的位宽为p×(Q+1), 深度为 。因此, 合并的存储器RAMMC占用了m×n个18 kb BRAM。
。因此, 合并的存储器RAMMC占用了m×n个18 kb BRAM。
更进一步, 这种方法的另外一个优点是, CNUs和PCUs可以共享同一组地址产生器, 可以节省m×n个模 的计数器资源。
的计数器资源。
 |
图2 提出新的存储外信息和判决信息的存储器MCs, t |
2.2 紧缩性硬判决信息存储策略
然而, 上面的硬判决和外信息共享的存储策略会导致一个问题, 当校验方程满足或预先设定的最大迭代次数到达时, 硬判决信息将作为最终的译码结果输出。而RAMMC存储器的2个端口总是同时被CNU(PCU)或VNU的输入输出占据着, 如果想从RAMMC存储器提取硬判决输出, 会导致存储器访问冲突。为了解决这个问题, 在VNU阶段, 在处理器的输出写入RAMMC的同时, n个硬判决信息应写入存储器RAMC。这个存储器RAMC在输出时仅为读模式, 定义为C, 它采用了紧缩性存储方法。然而, 与RAMMC合并封装外信息和硬判决信息不同, RAMC将n个硬判决信息封装到同一个存储单元中, 如图 3所示。在输出阶段, 从存储块C可以同时取出n个硬判决信息。所有的码字(硬判决信息)通过分别选择每个列块的n个硬判决信息来实现每个时钟周期p b的输出。在并行度为p>1的情况下, 存储器C的位宽为p×n, 深度为 。因此在Xilinx FPGA, RAMC仅需要1~2块18 kb BRAM。加上m×n个RAMM存储块, 本文的译码器需要m×n+n+1≈m×n+n个存储块, 可以减少m×n个存储块。
。因此在Xilinx FPGA, RAMC仅需要1~2块18 kb BRAM。加上m×n个RAMM存储块, 本文的译码器需要m×n+n+1≈m×n+n个存储块, 可以减少m×n个存储块。
 |
图3 新的存储硬判决信息的存储器C |
3 CCSDS标准的近地QC-LDPC译码器
本节采用上文提出的存储器紧缩策略, 在Xilinx FPGA Virtex 5 XC5VLX330上来实现CCSDS标准中近地QC-LDPC(8 176, 7 156)码作为一个实例。
3.1 CCSDS标准的近地QC-LDPC码特性
CCSDS标准中近地QC-LDPC(8 176, 7 156)的校验矩阵是一个规则码, 其列重为4, 行重为32[14], 该校验矩阵由m×n=2×16个循环基矩阵Ai, j构成, 这里L=511, Ai, j的每行每列中均有2个非零元素, 即Ai, j的行列重均为2, 校验矩阵如公式(5)所示, 校验矩阵的分布图如图 4所示, 图 4中的每个点表示校验矩阵中的一个1。
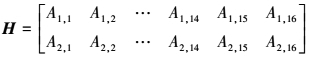 5
5
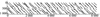 |
图4 校验矩阵分布图 |
3.2 紧缩性存储的QC-LDPC译码器架构
为了提高吞吐量, 采用p>1的并行度, 该架构可以简单地应用到p=1的低并行度情况。这个并行度p表示每个处理单元PUs同时对校验矩阵1元素对应的p行(或p列)进行处理。
图 5给出了紧缩性存储的QC-LDPC译码器架构, 外信息与硬判决信息的位宽为(Q+1)p b, 及H矩阵p列硬判决信息封装在一起对应的信息位宽为np b, 分别存储于存储单元RAMMC和RAMC中。为了将数据紧缩或从紧缩的数据中恢复出各自的外信息和硬判决信息, 引入合并/拆分模块。每个RAMF用来存储H矩阵p个列块对应的信道信息。在提出的架构中, 精确来说有2种外信息:变量节点到校验节点的信息(V2C)和校验节点到变量节点的信息(C2V)。但只有V2C合并硬判决信息存储于RAMMC。本文提出的译码器处理步骤如下:
初始化:
将从信道接收到的一帧信道信息存储到存储块Ft, 将所有的存储块MCs, t里面的内容初始化为零。数据是按列的顺序存储在Ft, C和MCs, t中, 这里先进行变量节点的更新, 因为存储块MCs, t里面的内容初始化为零。同样的, 如果初始化存储块MCs, t=Ft, 则校验节点就先进行更新。初始化迭代次数i=1。
迭代译码:
变量节点的更新:在VNU阶段, 来至存储器RAMMC的Qp b的C2V信息和存储器RAMF的Qp b信道信息同时发送给VNUs, 经过VNU计算处理后, 更新的Qp b的V2C信息和来至于后验概率符号的p比特的硬判决信息, 经合并/拆分模块合并为(Q+1)p b后写回至与读同样地址的存储器RAMMC中, 地址顺序为0, 1, …,  。
。
校验节点的更新和校验方程的计算(CNU-PCU):PCU与CNU是同时进行工作的。类似地, 在PCU和CNU阶段, (Q+1)p b的紧缩信息同时从存储器RAMMC中读出, 并通过合并/拆分模块恢复出2种信息, Qp b的V2C信息和p b的硬判决信息, 分别送入CNU和PCU进行计算, 更新的Qp b的V2C写回至与读同样地址的存储器, 地址顺序为 。同时, PCU计算出来的伴随式送入停止准则。
。同时, PCU计算出来的伴随式送入停止准则。
判决:如果停止准则满足或者到达预先设定的最大迭代次数, 跳转出迭代译码并将np b的硬判决信息输出; 否则, 继续迭代译码。
文献中有很多关于处理模块的实现技术, 如文献[3-11]。类似这些实现方法, 均采用降低关键路径延迟来提高时钟频率fclk, 在CNU和VNU中需要插入多级流水线。在本文中, 假设CNU和VNU分别插入c级和v级流水线。当关键路径延迟相同时, 行重dc越重, c越大, 同理, 列重dv越重, v越大。从上面的译码过程中可以看到, 本文的译码器一次迭代共需要 个时钟周期。
个时钟周期。
 |
图5 提出的紧缩性QC-LDPC译码器架构 |
4 实现结果
本节通过实现CCSDS标准近地QC-LDPC译码器来验证我们提出的紧缩性译码器架构的优势, 采用NMSA译码算法, 硬件平台采用Xilinx XC4VLX160 FPGA, 综合和实现均采用ISE 14.7工具。
对于LDPC译码器, CNUs更新行对应的信息, 行重为32, m=2, 所以译码器需要2p个32输入的CNUs, p为译码器的并行度, 本设计中的译码器p=8。同理, VNUs更新列对应的信息, 列重为4, n=16, 所以译码器需要16p个(4+1)输入的VNUs。
如图 5所示, 本文的译码器包括3种存储器, 分别是RAMF用来存储信道信息, RAMMC用来存储外信息和硬判决信息, RAMC用来存储待输出的硬判决信息。在本文的架构中, 存储器的深度均为2 =128, 采用2倍的
=128, 采用2倍的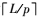 深度使译码器接收信道信息的同时可以进行译码, 而CNUs和VNUs对不同帧的数据交替处理。采用这种方法, 译码器可以同时接收信道信息、译码和输出译码结果。量化比特数Q=6 b, 这3种存储器的位宽却不同, RAMF为Qp=48 b, RAMMC为(Q+1)p=56 b, RAMC np=128 b。综上, 需要n=16个位宽为48 b深度为128的存储器用来存储信道信息, 共16×48×128=96 kb。1个位宽为128 b深度为128的存储器用来存储信道信息, 共128×128=16 kb。而外信息存储器的个数与校验矩阵基矩阵中非零的个数64成正比, 共64×56×128=448 kb。因此, 存储器总数为96+16+448=560 kb。本文的译码器共使用了16+64+2=82个存储块, 占用164个18 kb双端口BRAMs。
深度使译码器接收信道信息的同时可以进行译码, 而CNUs和VNUs对不同帧的数据交替处理。采用这种方法, 译码器可以同时接收信道信息、译码和输出译码结果。量化比特数Q=6 b, 这3种存储器的位宽却不同, RAMF为Qp=48 b, RAMMC为(Q+1)p=56 b, RAMC np=128 b。综上, 需要n=16个位宽为48 b深度为128的存储器用来存储信道信息, 共16×48×128=96 kb。1个位宽为128 b深度为128的存储器用来存储信道信息, 共128×128=16 kb。而外信息存储器的个数与校验矩阵基矩阵中非零的个数64成正比, 共64×56×128=448 kb。因此, 存储器总数为96+16+448=560 kb。本文的译码器共使用了16+64+2=82个存储块, 占用164个18 kb双端口BRAMs。
为了提高硬件利用率, 2类处理单元采用重叠交替对2帧数据进行译码[4], CNU和VNU均采用c=v=7级流水线, 所以译码器在一次迭代中总共需要v+c+2 =142个时钟, 当信道信息并行4路输入时, 接收完整的1帧需要8 176/4=2 044个时钟, 所以, 最大迭代次数为Im=
=142个时钟, 当信道信息并行4路输入时, 接收完整的1帧需要8 176/4=2 044个时钟, 所以, 最大迭代次数为Im= =14次。现阶段, LDPC一般与QPSK等二维调制方式相结合, 此时译码器同时接收2路数据(I, Q)对应的帧。本文采用计算机仿真的方法对量化译码性能进行分析, 使用2.2节的NMSA译码算法, 其中归一化因子α=0.75, 采用AWGN信道, QPSK调制方式, 最大迭代次数为14次和50次。采用图中Init(6, 2)表示初始信道信息采用(6, 2) bits量化, Mid(6, 2)表示外信息采用(6, 2)b量化。从图 6的仿真曲线中可以看出, 信道信息和外信息均采用6 b量化, 其中小数位2 b, 整数位3 b, 性能已经非常接近浮点译码情况, 而且迭代14次的定点量化译码性能与迭代50次的精确SPA译码误比特性能相差小于0.15 dB。
=14次。现阶段, LDPC一般与QPSK等二维调制方式相结合, 此时译码器同时接收2路数据(I, Q)对应的帧。本文采用计算机仿真的方法对量化译码性能进行分析, 使用2.2节的NMSA译码算法, 其中归一化因子α=0.75, 采用AWGN信道, QPSK调制方式, 最大迭代次数为14次和50次。采用图中Init(6, 2)表示初始信道信息采用(6, 2) bits量化, Mid(6, 2)表示外信息采用(6, 2)b量化。从图 6的仿真曲线中可以看出, 信道信息和外信息均采用6 b量化, 其中小数位2 b, 整数位3 b, 性能已经非常接近浮点译码情况, 而且迭代14次的定点量化译码性能与迭代50次的精确SPA译码误比特性能相差小于0.15 dB。
由于本文译码器处理单元采用重叠交替对I, Q 2帧数据进行译码, 且内部并行8路译码, 信道信息并行4路输入。所以本文所设计的译码器的吞吐量为fclk×4×2=8fclk, 这里fclk表示译码器的最高工作频率。经过布局布线和上板验证后我们的译码器最高工作频率为250 MHz, 对应2 Gb/s译码吞吐量, 最大迭代14次。
本文采用提出的设计方法对2种不同的LDPC码进行了译码器实现, 其中实现的CCSDS LDPC(8 176, 7 154)译码器与文献[3, 5, 7]的实现结果进行了比较, 实现的译码器的码长均为8 176,度分布(dv, dc)均为(4, 8),均采用6 b量化,如表 1所示; 实现的LDPC(1 296, 648)译码器与文献[8-9]的实现结果进行了比较, 实现的译码器的迭代次数均为20次,如表 2所示。
从表 1可见, 采用本文提出的译码器架构在FPGA Virtex 4上实现的CCSDS LDPC(8 176, 7 154)译码器, 当吞吐量为2 Gb/s时, 占用的硬件资源为164个18 kb BRAM(或560 kb存储空间)、56 778个查找表(LUT)和86 942个寄存器(FF)。
文献[3]采用FPGA Virtex 2实现了相同功能的译码器, 在时钟频率为193.4 MHz时, 吞吐量为193 Mb/s, 占用的资源总量为128个18 kb BRAM、28 229个LUT和26 926个FF。Virtex 4与Virtex 2的LTU资源同为4输入LTU, BRAM和FF的结构也大致相同, 由表 1的比较结果可见, 本文译码器的吞吐量约为文献[3]的10倍, 但从资源的使用情况上看, 本文的译码器的逻辑资源占用量仅为文献[3]译码器的2倍多, 其实现效率更高。这主要是由于文献[3]译码器避免存储器冲突的方法占用了大量的硬件资源, 而本文译码器的紧缩性存储及架构更有效, 同时文献[3]采用原始的F-SPA译码算法, 比本文采用的NMSA译码算法更复杂, 实现处理模块所需的硬件资源也更多。
文献[7]中采用的BP-based算法实际与本文采用的归一化最小和译码算法相同, 只是不同文献中表述不一致, 该译码器在FPGA EP2S180上实现, 时钟频率为200 MHz, 吞吐量为640 Mb/s, ALUs使用量为3.8×104个, FF为3×104个, 存储器资源共使用1 300 kb。与文献[8]相比, 本文译码器在存储器资源使用量上具有明显的优势, 且其余资源的利用效率也更高。
文献[5]与本文使用了完全相同的译码算法和FPGA器件。当时钟频率为212 MHz时, 该译码器吞吐量可达到714 Mb/s, 使用的硬件资源LUT为27 046, FF为27 210, 18 kb BRAM存储器为80个。由于文献[5]采用的译码架构没有考虑伴随式为零提前终止译码的情况, 不仅消耗大量的功耗而且不利于空闲时序的充分利用[6]。与文献[5]相比, 虽然本文译码器的资源翻了一番多, 但译码吞吐量约为文献[5]的3倍, 实现效率更高。另外, 本文译码器在BRAM的使用数量上优势不是特别明显, 但在存储空间使用总量上比文献[5]要少得多, 这使得本文的译码器结构在ASIC实现上更具优势。
采用本文提出的架构, 在FPGA Virtex 6上, 我们还实现了码长为1 296, L=54的规则(3, 6)QC-LDPC译码器, 设计时信道信息并行8路输入, 所以接收完整的1帧需要1 296/8=162个时钟。译码器内部并行度p=18, CNU和VNU均采用c=v=1级流水线, 一次迭代共需v+c+2  =8个时钟周期, 迭代次数可设计为Im=
=8个时钟周期, 迭代次数可设计为Im= =20次。由于规则(3, 6)码的循环矩阵的个数为18, 对于Vertex 6, 2个18 kb BRAMs自动合并为一个36 kb BRAMs, 所以按照本文提出的架构占用的36 kb BRAM存储器的个数为m×n+n+1=6+18+1=25。对应译码器的吞吐量为fclk×8×2=16fclk, 经过布局布线和上板验证后本文译码器的最高工作频率为230 MHz, 对应3.68 Gb/s译码吞吐量, 最大迭代20次。
=20次。由于规则(3, 6)码的循环矩阵的个数为18, 对于Vertex 6, 2个18 kb BRAMs自动合并为一个36 kb BRAMs, 所以按照本文提出的架构占用的36 kb BRAM存储器的个数为m×n+n+1=6+18+1=25。对应译码器的吞吐量为fclk×8×2=16fclk, 经过布局布线和上板验证后本文译码器的最高工作频率为230 MHz, 对应3.68 Gb/s译码吞吐量, 最大迭代20次。
文献[8]采用I-OMS, 即带偏移量的最小和算法, 采用相同的FPGA Virtex 6, 当时钟频率为223 MHz时, 吞吐量为2.41Gb/s, LUT为90 872, FF为23 352, 存储器资源为96个36 kb BRAM和24个18 kb BRAM。该译码器的BRAM资源使用量远大于本文译码器的25个36 kb BRAM, 逻辑资源比本文稍多, 而本文译码器的吞吐量更高。
文献[9]与文献[3]采用相同的F-SPA译码算法, 比本文采用的NMSA的译码算法更复杂, 采用FPGA Virtex 7对LDPC(1 296, 648)码进行实现, 当时钟频率为233 MHz时, 吞吐量为3.35 Gb/s, LUT-FF共使用78 299。与文献[9]相比, 本文译码器吞吐量和逻辑资源利用效率稍高。但在BRAM存储资源的利用效率上, 本文译码器具有明显优势, 在3.68 Gb/s吞吐量下本文译码器仅占用25个36 kb的BRAM存储资源, 较文献[9]的104个36 kb BRAM有明显优势。另外, 如果减少量化比特数, 使用与文献[9]相同的3 b量化, 本文译码器的资源可以进一步减少。
通过上面的对比分析, 可以看到本文设计的高速译码器在吞吐量、逻辑资源和存储器资源与现有设计相比具有一定优势, 这主要是由于本文在设计译码器时, 采用硬判决码字与外信息共享存储器和硬判决待输出码字信息紧缩的2种存储方法及其对应的高速译码器架构, 对于任意并行度的QC-LDPC译码器, 均可避免存储访问冲突问题。这种紧缩性存储策略不仅需要更少的存储块资源, 而且CNUs和PCUs能共享同一组地址产生器, 可以节省访问多个存储器的地址计数器资源。另外, 本文译码器采用NMSA算法, 该算法无非线性运算, 更易于硬件实现。与现有文献相比, 本文提出的译码器架构, 存储器和逻辑资源消耗更少, 同时这种设计仅需要提高块内的并行路数, 即可以进一步提高LDPC译码器的吞吐量, 可以灵活地调节LDPC译码器的设计并行度, 满足不同硬件平台不同吞吐量的需求。
 |
图6 量化及迭代次数对CCSDS近地QC-LDPC码误比特率的影响 |
本文的译码器与现有的LDPC(8 176, 7 154)译码器资源对比
提出的译码器与现有的LDPC(1296, 648)译码器资源对比
5 结论
对于部分并行QC-LDPC译码器架构, 多种信息均需要内部存储器, 包括信道信息, 外信息和硬判决信息, 这3种信息通常被分别存储。然而, 本文提出两种紧缩的存储方法, 第一种采用将p个相邻行的外信息和硬判决信息合并存储来节省存储块数, 另一种同样将p个相邻列的硬判决信息合并存储来避免处理和输出的访问冲突。采用我们的架构, 在Xilinx XC4VLX160 FPGA实现的CCSDS标准近地LDPC译码器, 时钟频率为250 MHz时, 吞吐量可达2 Gb/s, 对应的最大迭代次数为14次。
References
- GallagerR G. Low-Density Parity-Check Codes[J]. IRE Trans on Information Theory, 1962, 8(1): 21-28 [Article] [Google Scholar]
- LiZ, ChenL, ZengL, et al. Efficient Encoding of Quasi-Cyclic Low-Density Parity Check Codes[J]. IEEE Trans on Communications, 2006, 54(1): 71-81 [Article] [CrossRef] [Google Scholar]
- WangZ F, CuiZ. Low-Complexity High-Speed Decoder Design for Quasi-Cyclic LDPC Codes[J]. IEEE Trans on Very Large Scale Integration Systems, 2007, 15(1): 104-114 [Article] [CrossRef] [Google Scholar]
- DaiY M, YanZ Y, ChenN. Optimal Overlapped Information Passing Decoding of Quasi-Cyclic LDPC Codes[J]. IEEE Trans on Very Large Scale Integration Systems, 2008, 16(5): 565-578 [Article] [CrossRef] [Google Scholar]
- ChenX, KangJ, LinS, et al. Memory System Optimization for FPGA-Based Implementation of Quasi-Cyclic LDPC Codes Decoders[J]. IEEE Trans on Circuits and Systems I:Regular Papers, 2011, 58(1): 98-111 [Article] [CrossRef] [Google Scholar]
- ChristopherG B, FrankR K. On the VLSI Energy Complexity of LDPC Decoder Circuits[J]. IEEE Trans on Information Theory, 2017, 63(5): 2781-2795 [Article] [Google Scholar]
- Demangel F, Fau N, Drabik N, et al. A Generic Architecture of CCSDS Low Density Parity Check Decoder for Near-Earth Applications[C]//Proceedings of Design, Automation & Test in Europe Conference & Exhibition, Nice, France, 2009: 1242-1245 [Google Scholar]
- Truong N L, Khoa L, Ghaffari F, et al. FPGA Design of High Throughput LDPC Decoder Based on Imprecise Offset Min-Sum Decoding[C]//Proceedings of IEEE 13th International New Circuits and Systems Conference, Grenoble, France, 2015: 7-10 [Google Scholar]
- Nimara S, Boncalo O, Amaricai A, et al. FPGA Architecture of Multi-Codeword LDPC Decoder with Efficient BRAM Utilization[C]//Proceedings of IEEE 19th International Symposium on Design and Diagnostics of Electronic Circuits & Systems, Kosice, Slovakia, 2016: 20-23 [Google Scholar]
- Xie T J, Yuan R J, Zhang J H. A Shared Hard Decisions Storing in Partially Parallel FPGA-Based QC-LDPC Decoder[C]//Proceedings of IEEE International Conference on Communication Problem-Solving, Guilin, China, 2015: 594-596 [Google Scholar]
- Xie T J, Li B, Yang M, et al. Memory Compact High-Speed QC-LDPC Decoder[C]//IEEE International Conference on Signal Processing, Communications and Computing, Xiamen, China, 2017: 22-25 [Google Scholar]
- MackayD J C, NealR M. Near Shannon Limit Performance of Low Density Parity Check Codes[J]. Electronics Letters, 1997, 33(6): 457-458 [Article] [CrossRef] [Google Scholar]
- ChenJ H, DholakiaA, EleftheriouE, et al. Reduced-Complexity Decoding of Ldpc Codes[J]. IEEE Trans on Communications, 2005, 53(8): 1288-1299 [Article] [CrossRef] [Google Scholar]
- CCSDS. Low Density Parity Check Codes for Use in Near-Earth and Deep Space Applications[S]. CCSDS 131.1-O-2, 2007 [Google Scholar]
All Tables
All Figures
|
图1 传统的QC-LDPC译码器结构框图 |
| In the text | |
|
图2 提出新的存储外信息和判决信息的存储器MCs, t |
| In the text | |
|
图3 新的存储硬判决信息的存储器C |
| In the text | |
|
图4 校验矩阵分布图 |
| In the text | |
|
图5 提出的紧缩性QC-LDPC译码器架构 |
| In the text | |
|
图6 量化及迭代次数对CCSDS近地QC-LDPC码误比特率的影响 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.