| Issue |
JNWPU
Volume 42, Number 6, December 2024
|
|
|---|---|---|
| Page(s) | 1135 - 1143 | |
| DOI | https://doi.org/10.1051/jnwpu/20244261135 | |
| Published online | 03 February 2025 | |
RGB-D salient object detection based on BC2 FNet network
基于BC2FNet 网络的RGB-D显著性目标检测 network
1
School of Physics and Electrical Engineering, Weinan Normal University, Weinan 714099, China
2
Engineering Research Center of X-ray Imaging and Detection, University of Shaanxi Province, Weinan 714099, China
3
School of Automation, Northwestern Polytechnical University, Xi'an 710072, China
Received:
11
October
2023
Abstract
In the face of complex scene images, the introduction of depth information can greatly improve the performance of salient object detection. However, up-sampling and down-sampling operations in neural networks maybe blur the boundaries of objects in the saliency map, thereby reducing the performance of salient object detection. Aiming at this problem, a boundary-driven cross-modal and cross-layer fusion network (BC2FNet) for RGB-D salient object detection is proposed in this paper, which preserves the boundary of the object by adding the guidance of boundary information to the cross-modal and cross-layer fusion, respectively. Firstly, a boundary generation module is designed to extract two kinds of boundary information from low-level features of RGB and depth modalities, respectively. Secondly, a boundary-driven feature selection module is designed, which is dedicated to simultaneously focusing on important feature information and preserving boundary details in the process of RGB and depth modality fusion. Finally, a boundary-driven cross-layer fusion module is proposed which simultaneously adds two kinds of boundary information in the process of up-sampling fusion on adjacent layers. By embedding this module into the top-down information fusion flow, the predicted saliency map can contain accurate objects and sharp boundaries. Simulation results on five standard RGB-D data sets show that the proposed model can achieve better performance.
摘要
面对复杂的场景图像, 深度信息的引入可以大大提高显著性目标检测的性能。然而, 神经网络的上采样和下采样操作会模糊显著图中目标的边界, 从而降低显著性目标检测性能。针对此问题, 提出了一种基于边界驱动跨模态跨层融合网络(BC2FNet)的RGB-D显著性目标检测方法。该网络在跨模态和跨层融合中分别加入边界信息引导来保持目标区域。设计了边界生成模型, 分别从RGB和深度模态的低层特征中提取2种边界信息; 设计边界驱动的特征选择模块, 在RGB与深度模态融合过程中, 聚焦重要特征信息并保留边界细节; 提出了一种边界驱动的跨层融合模块, 在相邻层的上采样融合过程中加入2种边界信息。通过将该模块嵌入到自顶向下的信息融合流中, 预测出包含精确目标和清晰边界的显著性图。在5种标准RGB-D数据集上进行仿真实验, 结果证明所提出的模型具有较好的性能。
Key words: salient object detection / boundary-driven / cross-modal fusion / cross-layer fusion
关键字 : 显著性目标检测 / 边界驱动 / 跨模态融合 / 跨层融合
© 2024 Journal of Northwestern Polytechnical University. All rights reserved.
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
显著性目标检测(SOD)的目的是在给定图像中定位和选择最具有视觉吸引力的对象或区域。它是计算机视觉领域(CV)的一个热门话题,具有很高的研究价值和广泛的应用场景。SOD检测到的显著区域包含更多有用的语义信息,因此,它们经常被用于其他计算机视觉任务的预处理,如视觉跟踪[1]、图像分割、图像质量评估、物体识别等[2]。
早期RGB-D显著性目标检测主要研究RGB和深度图像中的有用信息,设计手工制作特征,如中心先验、边界先验和对比度。这些手工特征信息表达能力较低,导致在面对复杂场景图像时检测结果不满意。随着卷积神经网络(CNN)的快速发展,由于其在提取特征方面的优势,各种方法都使用CNN对RGB-D显著性目标进行检测,大大提高了检测性能。然而,在具体检测过程中也存在一些问题。CNN中上采样和下采样操作会丢失目标边界细节,影响SOD的整体性能。因此,如何在检测显著目标的同时保留目标边界信息是一个关键问题。
针对此问题,提出了许多RGB-D SOD方法以保持物体清晰的边界。根据解决方案的不同可将这些方法分为两大类:①设计不同类型的损失函数激励网络模型在训练过程中约束目标的边界,以此保证显著目标具有明确的边界[3];②设计各种边界检测网络学习边界特征以辅助SOD[4]。这些方法虽然在一定程度上保留了显著目标的边界信息,但只使用了网络模型某一阶段(如跨模态融合或显著性图预测)学习到的边界信息,并没有充分利用边界信息辅助显著性目标检测,使得目标边界不够清晰。因此,本文认为提高目标精度并保留目标边界信息可以从以下2个方面考虑:①如何从RGB和深度模态中提取准确的边界细节信息;②如何有效地利用提取的边界信息加入SOD。
基于以上2个方面,本文提出了一种边界驱动BC2FNet的RGB-D SOD方法。该网络将学习到的边界特征融入到整个SOD过程中,使预测的显著性图包含清晰边界的显著性目标。首先,考虑到主干网提取高层特征包含更多的语义信息,而低层特征包含更多细节信息,提出了一种边界生成模块(BGM),分别从RGB和深度模态的低层特征中提取2种类型的边界信息。其次,为了充分利用提取的边界信息,分别在SOD的跨模态和跨层融合过程中加入边界信息。具体而言,本文设计了一种边界驱动特征选择模块(BFSM),实现RGB特征与深度特征的有效融合,该模块能够在保留目标边界信息的同时,重点关注重要特征。此外,本文还设计了一种边界驱动跨层融合模块(BCFM),有效整合相邻层特征,并将该模块嵌入自顶向下的信息融合流中,预测最终的显著性图。本文的贡献总结如下:
1) 针对现有SOD方法中目标边界不清晰问题,设计了一种边界驱动BC2FNet的SOD网络,该网络既能准确预测显著目标,又能保留目标边界。
2) 提出了一种边界生成模块,从RGB和深度模态的低层特征中提取2种边界信息,以辅助显著目标检测。
3) 分别设计了边界驱动特征选择融合模块和边界驱动跨层融合模块。在跨模态融合和跨层融合中加入2种边界信息,使得网络在检测显著目标过程中始终保持清晰的边界信息。
4) 在5种标准数据集上进行仿真实验,证明了本文提出的网络模型优于其他对比方法。
1 相关工作
1.1 RGB-D显著性目标检测
许多RGB SOD方法能实现较好的检测效果。然而,当面对复杂背景和低对比度复杂图像时,其检测结果会受到目标缺失和背景干扰的影响。
考虑到易于获取的深度图像中含有利于显著目标定位的三维空间结构信息,许多学者采用RGB图像和深度图像进行SOD,获得了较好的检测结果。
传统RGB-D显著性方法,主要利用不同类型的手工特征,如颜色、边界、全局对比度、空间先验信息等,从RGB和深度图像中提取有用的特征信息,并利用特征信息预测显著性图。Cong等[5]提出使用颜色和深度信息计算显著性图。Ren等[6]将区域对比度与背景、深度和方向先验相结合,得到显著性图。Liang等[7]设计了一种基于对比度和深度引导背景先验的3D立体显著性图。
随着深度学习的快速发展,与传统手工特征在信息传递上的局限性相比,基于CNN提取的特征信息包含了丰富的语义信息,具有较强的表征能力。因此,许多基于CNN的RGB-D SOD方法研究取得了巨大的进展。根据RGB图像与深度图像的融合方法,可以分为3类:
1) 早期融合。将通道维度上的深度图像和RGB图像进行拼接,形成4个通道,然后,输入网络预测显著性图。
2) 后期融合。将RGB图像和深度图像输入到网络中生成不同类型的特征,然后将这些特征整合到网络中预测最终的显著性图。
3) 中间融合。从RGB图像和深度图像提取不同层次的信息,然后融合这些层次特征来预测最终的显著性图。
Chen等[8]提出了一种替代的细化策略来逐步融合RGB特征和深度特征。Li等[9]提出了3种RGB的深度交互模型,分别处理低层、中层和高层的跨模态信息融合。Zhang等[10]提出了RGB诱导的细节增强模块和深度诱导的语义增强模块,分别将其应用于低层特征和高层特征融合,实现差异化的跨模态融合。Zhang等[11]提出了一种双向传递选择网络,逐步双向融合RGB信息和深度信息。Li等[12]提出了一种分层交替交互模型,以有效增强RGB特征与深度特征之间的跨模态交互。这些方法预测的显著性图存在边界模糊问题。因此,本文将边界信息整合到RGB-D SOD中,提出了一种边界驱动的跨模态跨层融合网络。
1.2 边界显著性目标检测
CNN中的上采样和下采样操作容易破坏显著目标的边界信息,进而降低SOD的性能。因此许多学者提出了不同的解决方案激励突出的物体保持清晰的边界。Qin等[2]通过融合二元交叉熵(BCE)、结构相似性(SSIM)和交联(IOU)损失设计了一种混合损失函数,协助网络模型预测清晰边界的显著性图。Pang等[3]提出了一种包含边缘增强损失和区域增强损失的混合增强损失函数,以优化显著目标的边界细节,增强显著区域一致性。Niu等[1]在多尺度密集融合网络架构中加入边缘敏感损失(ESI),以保持检测到的突出区域边界。此外,也有一些方法以边界信息为中心设计不同的网络结构。Wang等[13]提出了一种显著边界检测模块探索边界信息。Liu等[14]在主网络中增加了一种预测分支评估显著目标的边界。Song等[15]提出了一种同时学习显著性对象区域、边界显著性预测网络和边界保持网络的方法。Yang等[16]设计了一种基于连通性的边缘特征提取方法,该方法直接从网络输出中提取边缘特征信息。Zhai等[17]提出了一种分叉骨干策略网络,利用低层特征中的细节信息优化显著目标的边界。Ji等[4]提出了一种结合边界、深度和显著性的协作学习框架。Li等[18]提出了显著性引导位置边缘机制,同时定位显著目标,缓解边界模糊问题。Jin等[19]设计了一种两阶段的跨模态融合方法,使用高层和低层特征分别预测初始显著性图和目标边界。
与上述方法不同的是,本文首先提出边界生成模块,分别从RGB图和其对应的深度图中学习出边界特征,然后将边界特征引入跨模态和跨层融合中,预测包含目标清晰边界的显著性图。
2 本文方法
2.1 整体结构
本文提出的BC2FNet整体结构如图 1所示,该图由2个边界生成模块(BGM)、4个边界驱动特征选择模块(BFSM)和3个边界驱动跨层融合模块(BCFM)组成。其中,BFSM和BCFM模块构成本文跨模态跨层融合策略。首先采用PVTv2骨干网分别从RGB图像和深度图像中提取4层特征,使用1×1卷积层来降低提取分层特征的通道维数,得到通道维数为32的RGB特征{fri, i=1, 2, 3, 4}和深度特征{fdi, i=1, 2, 3, 4}。其次, 对RGB特征和深度特征进行合成得到提取的2类边界信息图。然后,通过BFSM将提取的2类边界信息结合通道和空间注意机制进行RGB特征和深度特征的跨模态融合。最后,在相邻层的上采样融合过程中加入2种边界信息,通过将BCFM模块嵌入到自顶向下的信息融合流中,得到目标边界清晰的显著性图。
 |
图1 本文提出BC2FNet的总体框图 |
2.2 边界生成模型
CNN中的上采样和下采样过程会丢失目标的边界信息,而边界信息也会深刻影响RGB-D SOD的性能。考虑到主干网络提取的高层特征包含较多的语义信息,而低层特征包含较多的边界细节,本文从低层特征中挖掘更多的边界信息以辅助SOD。如图 2所示,在多目标场景下,骨干网提取4层边界信息。可以看出,前3层保留了更多的边界特征,而第4层几乎没有物体的边界信息。因此,本文设计了边界生成模块,分别从RGB和深度特征的前3层提取准确边界信息。BGM网络结构如图 3所示。
首先,将前3层的RGB特征与深度特征进行融合,生成2个融合特征。具体操作如下:
 (1)
(1)
 (2)
(2)
式中:Conv(·)指核大小为3×3的卷积操作;C(·)表示连接运算符;Up2(·)和Up4(·)分别表示2×双线性和4×双线性上采样操作。Fcatr和Fcatd分别表示融合RGB特征和深度特征。
然后,考虑到合成特征存在噪声干扰,本文采用平均池化和Sigmoid激活函数学习加权因子。最后,运用元素乘法和元素加法运算,将学习到的加权因子对集成特征进行加权。因此,可以同时增强边界细节信息和抑制背景信息。具体操作为
 (3)
(3)
 (4)
(4)
式中:o∈{r, d}, Wo表示学习到的权值因子;Bo表示从RGB和深度特征获得的边界特征。S(·)表示Sigmoid激活函数;Avg(·)为自适应平均池化操作;⊗和⊕分别表示元素的乘积和元素求和。
 |
图2 利用骨干网络提取不同场景下的层次边界图 |
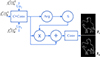 |
图3 BGM模型的结构图 |
2.3 边界驱动特征选择模型
如上所述,可将跨模态融合分为早期融合、中期融合及后期融合。本文利用中间融合策略,提出了一种边界驱动的跨模态融合特征选择模块。在跨模态融合过程中,首先使用2种类型的RGB和深度特征的边界信息引导网络学习目标的边界信息。其次,考虑到骨干网提取分层特征中存在大量冗余信息,本文引入了通道注意模型和空间注意模型,对通道维度和空间维度上的重要特征信息进行关注。本文提出BFSM的结构如图 4a)所示,主要包括3个分支:RGB分支、深度分支和融合分支。每个分支由边界信息和一个特征选择模块(FSM)组成,目的是在保留边界信息的同时关注重要的目标信息。
本文提出的BFSM由边界驱动和特征选择两部分组成。在RGB分支中加入RGB边界信息的引导,在深度分支中加入深度边界信息的引导,在融合分支中加入RGB和深度边界信息的联合引导。因此,跨模态融合特征不仅包含有模态特定的边界信息,而且包含模态融合的边界信息。其实现过程如(5)~(7)式所示。
 (5)
(5)
 (6)
(6)
 (7)
(7)
式中, Bri, Bdi和Bfi分别表示第i层RGB特征、深度特征和边界保留信息的融合特征。
在经过3种分支学习到保留边界信息的特征后, 本文提出通过3种FSM来选择重要特征。FSM具体结构如图 4b)所示, 它由通道注意(CA)和借鉴卷积块注意模型(CBAM)的空间注意(SA)组成。首先, 将Bri, Bdi和Bfi输入到CA中得到通道注意图, 该注意图引导输入特征在信道维度上选择重要的特征区域, 并对其进行增强。然后, 将通道注意模型选择的特征发送给SA, 在空间维度上进行新一轮特征选择, 进一步强化特征。具体操作为
 (8)
(8)
 (9)
(9)
式中:m∈{r, d, f}, CGMP(·)是沿通道维度的全局最大池化操作;SGMP(·)是沿着空间维度的全局最大池化操作。最后, 将3分支双选后的特征整合为一个特征, 完成跨模态融合。操作流程为
 (10)
(10)
式中含有1个内核大小为3×3的卷积层, 1个批处理归一化层和1个ReLU激活函数层。Fi表示第i层RGB特征与深度特征的融合特征。
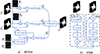 |
图4 边界驱动特征选择模块和特征选择模块结构图 |
2.4 边界驱动跨层融合模型
为了更好地利用跨模态融合特征{Fi, i∈{1, 2, 3, 4}}和2种边界信息{Bo, o∈{r, d}}, 本文提出了一种简单有效的BCFM模块。如图 1所示, 通过将该模块嵌入到自顶向下的信息融合流中, 预测显著性图包含准确的对象和清晰的边界。提出BCFM模块如图 5所示。
首先, 对前一层的跨模态融合特征Fi+1进行上采样, 并通过级联操作将其余当前层的跨模态融合特征Fi合并。考虑到上采样操作会丢失目标的边界信息, 通过拼接操作将2类边界信息合并到跨层融合特征中, 恢复丢失的边界信息。最后, 通过3×3卷积层对通道维数进行降维, 得到保留边界信息的跨层融合特征Ffi。
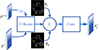 |
图5 BCFM模块框图 |
2.5 损失函数
1) 边界损失。本文借助2个边界特征Br和Bd, 通过卷积层和上采样层得到2个预测的边界映射Mbr和Mbd。将经典的Canny边缘检测算法应用于显著性映射真值图, 得到边界映射的地面真值(GT)。边界损失定义为
 (11)
(11)
式中:Gb表示边界映射地面真值;Lbce(·)表示二值交叉熵损失函数, 其表达式如(12)式所示。
 (12)
(12)
式中, xi∈X, yi∈Y; N为像素总数。
2) 显著损失。本文将最后一个边界驱动的跨层融合模块生成的特征Ff1输入到卷积层和上采样层中, 以获得最终的显著性图Sp。同理, 本文使用二元交叉熵损失函数(BCE)反映预测的显著性图Sp和显著性图地面真值Gs之间的差异。显著性损失定义为
 (13)
(13)
因此, 网络训练过程中总损失包括边界损失和显著性损失两部分。
 (14)
(14)
式中, λ1和λ2为权值系数, 在实验中其值均取为1.0。
3 实验结果分析
3.1 数据集
本文采用5种标准数据集验证所提方法的有效性,包括NJUD[4]、NLPR[20]、LFSD[21]、STERE[22]、和SIP[23]。NJUD由1 985幅来自互联网、3D电影和富士W3立体相机拍摄的图像组成。NLPR包含1 000张微软Kinect收集的室内和室外图像。LFSD由Lytro光场相机收集的100幅光场图像组成,包括60幅室内场景和40幅室外场景。STERE包含1 000张全部来自互联网的立体图像。SIP由929张具有不同场景和各种挑战性因素的高分辨率图像组成。为了与其他方法进行公平的比较,根据以前的工作,使用来自NJUD的1 485个样本和来自NLPR的700个样本作为训练数据集。将训练集和其他数据集中剩余的数据作为测试集。
采用S量测(Sα)、E量测(Eξ)、F量测(Fβ)和M 4个评价指标,将本文方法与其他方法进行比较。S量测用于计算区域感知与对象感知之间的结构相似度;E量测用于获取图像层统计信息和局部像素匹配信息;F量测用来计算召回率;M用于计算预测显著性图与GT之间的平均绝对值误差。其中Sα, Eξ和Fβ的值越大越好,M的值越小越好。
3.2 实现细节
本文方法采用Pytorch框架, 并在单个GeForce RTX 3080 GPU上进行了实验。主干网络采用PVTv2或ResNet50, 去掉最后一个分类层, 在ImageNet对预训练模型进行初始化。在训练和测试阶段, 将输入图像的分辨率调整为352×352。为了防止出现过拟合, 本文采用随机翻转、旋转和裁剪边界等变换对所有数据进行增强。采用Adam对模型进行优化, 初始学习率定为0.000 1, 每50个epoch为学习率除以10。在实验中, 批处理大小设置为6, 共训练了150个epoch。
3.3 对比实验
将本文提出的BC2FNet在5种标准数据集上与8种最先进的RGB-D显著性检测算法进行比较,包括CoNet[4]、HdFNet[3]、DsA2F[20]、BiANet[21]、DFM[22]、SsLSOD[23]、C2DFNet[24]和MvSalNet[25]。为了公平比较,本文采用相应文献提供的显著性图和显著性计算评价结果。
1) 客观评价。表 1显示了本文提出的BC2FNet与8种最先进的方法在5种数据集上的4种评估标准对比。可以观察到,基于PVTv2骨干网的方法在NJUD、NLPR、STERE和SIP数据集上的性能优于所有方法。在LFSD数据集上,本文方法的Eξ和M值略低于DSA2F方法。对于5种标准数据集,本文方法在Sα和Fβ 2种指标上的性能提高了1%。对于基于ResNet50的方法,可以看到在4种评估指标下的性能大多处于前3个级别,与最优结果相差很小。
HdFNet方法提出一种混合增强损失函数来优化显著目标的边界,本文方法与此方法相比在NJUD、NLPR、LFSD、STERE和SIP数据集上分别提升了2.1%, 1.3%, 2.9%, 1.9%和1.5%。CoNet方法首先从RGB模态的低层特征中获取边界信息,然后将边界信息融入RGB模态和深度模态预测显著图。本文方法与CoNet方法相比在NJUD、NLPR、LFSD、STERE和SIP数据集上分别提升了3.3%, 3.1%, 2.4%, 1.6%和3.7%。与这2种典型方法的比较结果证实了本文方法能够有效地保留显著目标的区域和边界。总之,与8种方法的比较充分证实了本文提出的BC2FNet的优越性。
2) 主观评价。图 6显示了本文提出的BC2Net与6种最先进方法在复杂场景图像下的视觉对比,可以看出,所提出方法预测的显著性图更接近于GT。同时,本文的显著性图与其他方法相比包含更多边界清晰的显著性目标。证明了本文所提BC2FNet网络的有效性。
本文方法与8个最先进的方法使用4种评估指标进行定量比较
 |
图6 将本文提出的方法与6种最先进的方法进行视觉比较 |
3.4 消融实验
在本节中, 为了证明所提出的BGM、BFSM和BCFM对整个网络的贡献, 分别在3个模块上进行消融实验。
1) 边界生成模块的有效性。为了验证BGM的有效性, 本文进行了不同策略的实验。①增加Br(only Br):仅使用RGB模态的前3层边界特征Br进行后续跨模态融合和跨层融合。②增加Bd(only Bd):仅将前3层深度模态特征得到的边界特征Bd加入到跨模态融合和跨层融合中来预测显著性图。③w/o Bo:在跨模态和跨层融合过程中, 不使用提取的2个边界特征来预测显著性图。根据表 2, 可以观察到, 无论是使用边界信息还是仅使用其中一种都会降低所提BC2FNet的性能。用上述3种方案得出的显著图如图 7e)~7g)所示, 与图 7d)相比, 花朵和玩偶的边界比较模糊, 证实了本文提出的边界生成模块的有效性。
2) 边界驱动特征选择模块的有效性。在跨模态融合过程中,BFSM用于保留目标边界信息,并选择重要特征。因此,本文对该模块的2个部分进行了2次实验,以验证其有效性。①w/o BFSM-B: 去掉边界驱动特征选择模块中引入2种类型的边界信息。②w/o FSM: 在边界驱动特征选择模块中,去掉负责特征选择功能的通道注意模块和空间注意模块。根据表 2可以发现去除任何部分都会降低检测性能。从图 8所示的视觉对比可以看出,去除边界信息之后得出的图 8e)中花朵和玩偶的边界信息并不清楚,去除2个注意模块后得出的图 8f)中花朵和玩偶都出现重要目标区域特征的缺失。
3) 边界驱动跨层融合模块的有效性。在本文提出的BC2FNet中,BCFM主要用于融合相邻层特征,并将该模块嵌入到自顶而下的信息流中预测显著性图。因此,本文通过以下实验来验证其有效性。①w/o BCFM-B:去掉边界驱动跨层融合模块中添加的2种边界信息。②w/o BCFM:不使用BCFM进行自顶向下的预测显著性图,经过跨模态融合后的增强特征直接上采样成GT大小,并通过拼接操作对增强特征整合预测最终的显著性图。从表 2和图 9可以看出,去除任何部分都会降低性能,并且会出现对象不完整和边界不清晰问题。
BGM、BFSM和BCFM的消融实验
 |
图7 边界生成模型视觉比较消融研究 |
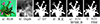 |
图8 边界驱动特征选择模型视觉对比消融研究 |
 |
图9 边界驱动跨层融合模型视觉对比消融研究 |
4 结论
针对现有的许多方法预测显著性图边界不清晰问题,提出了一种边界驱动跨模态跨层融合网络的RGB-D SOD方法。首先,提出了一种边界生成模型,分别从RGB模态和深度模态的低层特征中提取2种类型的边界信息。其次,设计了边界驱动特征选择模块,将2种类型边界信息和2种类型注意机制引入跨模态融合中,使融合后的特征既能保留边界信息,又能保留重要特征。最后,提出了一种边界驱动跨层融合模块,将2种边界信息引入相邻层的融合过程。该模块嵌入自顶向下的信息流中,使预测的显著性图包含清晰边界的正确目标。在5种标准数据集上的主观和客观实验分析中证明了本文所提BC2FNet的优越性。
References
- NIU Y, LONG G, LIU W, et al. Boundary-aware RGB-D salient object detection with cross-modal feature sampling[J]. IEEE Trans on Image Process, 2020, 29(5): 9496–9507 [NASA ADS] [CrossRef] [Google Scholar]
- QIN X, ZHANG Z, HUANG C, et al. BASNet: boundary-aware salient object detection[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, 2019: 7471–7481 [Google Scholar]
- PANG Y, ZHANG L, ZHAO X, et al. Hierarchical dynamic filtering network for RGB-D salient object detection[C]//Proceedings of the Computer Vision, 2020: 235–252 [Google Scholar]
- JI W, LI J, ZHANG M, et al. Accurate RGB-D salient object detection via collaborative learning[C]//Proceedings of the Computer Vision, 2020: 52–69 [Google Scholar]
- CONG R, LEI J, ZHANG C., et al. Saliency detection for stereoscopic images based on depth confidence analysis and multiple cues fusion[J]. IEEE Signal Process Letters, 2016, 23(8): 819–823. [Article] [CrossRef] [Google Scholar]
- REN J, GONG X J, YU L, et al. Exploiting global priors for RGB-D saliency detection[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, 2015: 25–32 [Google Scholar]
- LIANG F, DUAN L, MA W, et al. Stereoscopic saliency model using contrast and depth-guided-background prior[J]. Neurocomputing, 2018, 275(15): 2227–2238. [Article] [CrossRef] [Google Scholar]
- CHEN S, FU Y. Progressively guided alternate refinement network for RGB-D salient object detection[C]//Proceedings of the Computer Vision, 2020: 520–538 [Google Scholar]
- LI G, LIU Z, YE L, et al. Cross-modal weighting network for RGB-D salient object detection[C]//Proceedings of the Computer Vision, 2020: 665–681 [Google Scholar]
- ZHANG C, CONG R, LIN Q, et al. Cross-modality discrepant interaction network for RGB-D salient object detection[C]//Proceedings of the 29th ACM International Conference on Multimedia, 2021: 2094–2102 [Google Scholar]
- ZHANG W, JIANG Y, FU K, et al. BTS-net: bi-directional transfer-and-selection network for RGB-D salient object detection[C]//Proceedings of the 2021 IEEE International Conference on Multimedia and Expo, Shenzhen, 2021: 1–6 [Google Scholar]
- LI G, LIU Z, CHEN M, et al. Hierarchical alternate interaction network for RGB-D salient object detection[J]. IEEE Trans on Image Process, 2021, 30(6): 3528–3542. [Article] [CrossRef] [Google Scholar]
- WANG W, ZHAO S, SHEN J, et al. Salient object detection with pyramid attention and salient edges[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, 2019: 1448–1457 [Google Scholar]
- LIU J J, HOU Q, CHENG M M, et al. A simple pooling-based design for real-time salient object detection[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, 2019: 3912–3921 [Google Scholar]
- SONG D, DONG Y, LI X. Hierarchical edge refinement network for saliency detection[J]. IEEE Trans on Image Process, 2021, 30: 7567–7577. [Article] [NASA ADS] [CrossRef] [Google Scholar]
- YANG Z, SOLTANIAN-ZADEH S, FARSIU S. BiconNet: an edge-preserved connectivity-based approach for salient object detection[J]. Pattern Recognition, 2022, 12(6): 121–131. [Article] [Google Scholar]
- ZHAI Y, FAN D P, YANG J, et al. Bifurcated backbone strategy for RGB-D salient object detection[J]. IEEE Trans on Image Process, 2021, 30(9): 8727–8742. [Article] [NASA ADS] [CrossRef] [Google Scholar]
- LI C, CONG R, PIAO Y, et al. RGB-D salient object detection with cross-modality modulation and selection[C]//Proceedings of of the Computer Vision, 2020: 225–241 [Google Scholar]
- JIN W D, XU J, HAN Q, et al. CDNet: complementary depth network for RGB-D salient object detection[J]. IEEE Trans on Image Process, 2021, 30(9): 3376–3390. [Article] [NASA ADS] [CrossRef] [Google Scholar]
- SUN P, ZHANG W, WANG H, et al. Deep RGB-D saliency detection with depth-sensitive attention and automatic multi-modal fusion[C]//Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, 2021: 1407–1417 [Google Scholar]
- ZHANG Z, LIN Z, XU J, et al. Bilateral attention network for RGB-D salient object detection[J]. IEEE Trans on Image Process, 2021, 30(5): 1949–1961. [Article] [CrossRef] [Google Scholar]
- ZHANG W, JI G P, WANG Z, et al. Depth quality-inspired feature manipulation for efficient RGB-D salient object detection[C]//Proceedings of the 29th ACM International Conference on Multimedia, 2021: 731–740 [Google Scholar]
- ZHAO X, PANG Y, ZHANG L, et al. Self-supervised representation learning for RGB-D salient object detection[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2022 [Google Scholar]
- ZHANG M, YAO S Y, HU B Q, et al. C2DFNet: criss-cross dynamic filter network for RGB-D salient object detection[J]. IEEE Trans on Multimedia, 2022, 25(3): 1–13 [Google Scholar]
- ZHOU J Y, WANG L J, LU H C, et al. MVSalNet: multi-view augmentation for RGB-D salient object detection[C]//Proceedings of the Computer Vision, 2022: 270–287 [Google Scholar]
All Tables
All Figures
|
图1 本文提出BC2FNet的总体框图 |
| In the text | |
|
图2 利用骨干网络提取不同场景下的层次边界图 |
| In the text | |
|
图3 BGM模型的结构图 |
| In the text | |
|
图4 边界驱动特征选择模块和特征选择模块结构图 |
| In the text | |
|
图5 BCFM模块框图 |
| In the text | |
|
图6 将本文提出的方法与6种最先进的方法进行视觉比较 |
| In the text | |
|
图7 边界生成模型视觉比较消融研究 |
| In the text | |
|
图8 边界驱动特征选择模型视觉对比消融研究 |
| In the text | |
|
图9 边界驱动跨层融合模型视觉对比消融研究 |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.